6 Essential Steps for an Effective Incident Response Plan
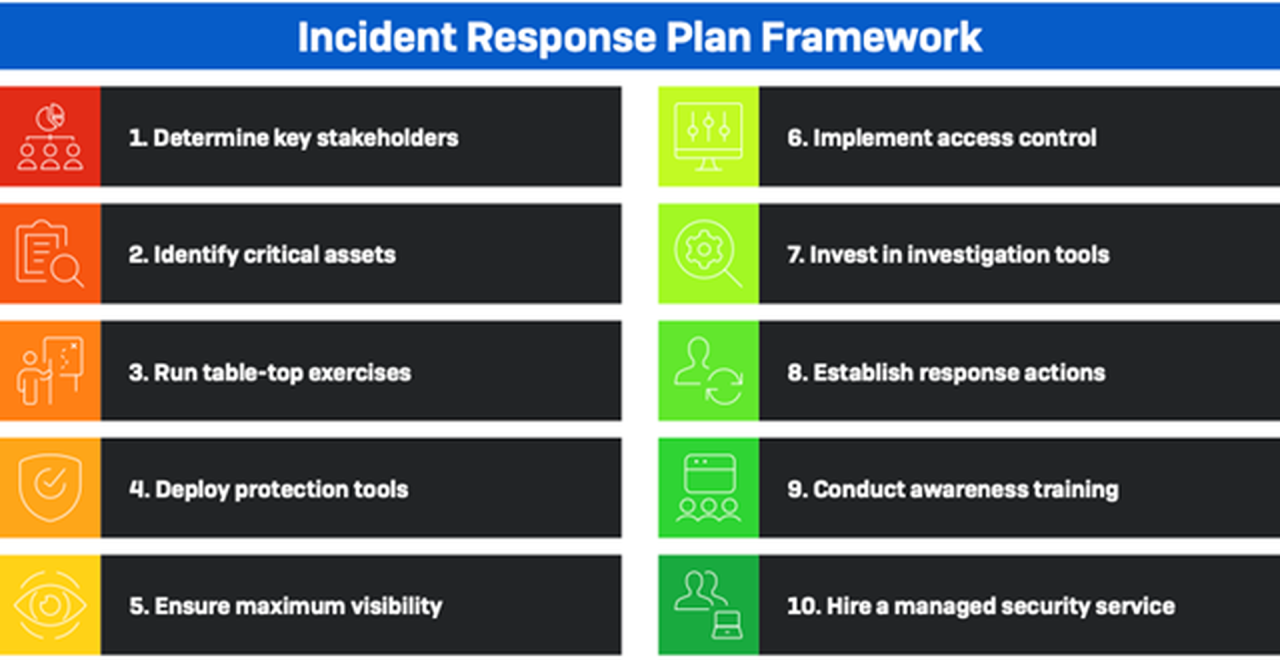
6 Essential Steps for an Effective Incident Response Plan: Ever felt that sickening feeling in your gut when something goes wrong with your online security? This isn’t just a tech problem; it’s a potential business disaster. A solid incident response plan is your safety net, your emergency playbook for when things go south. This guide breaks down six crucial steps to building a plan that will protect your business and your sanity.
We’ll delve into the nitty-gritty of preparation, from creating a detailed inventory of your systems to establishing clear communication protocols. We’ll cover how to identify and contain incidents, eradicate threats, and recover your systems. Finally, we’ll explore the vital post-incident analysis that helps you learn from mistakes and strengthen your defenses for the future. Get ready to transform your approach to online security!
Preparation: 6 Essential Steps For An Effective Incident Response Plan
A robust incident response plan is the bedrock of effective cybersecurity. Without a well-defined plan, even the most skilled team will struggle to contain and mitigate incidents efficiently. Preparation isn’t just about having a document; it’s about creating a living, breathing system that adapts to evolving threats and ensures your organization is ready to respond effectively when the inevitable occurs.
Key Components of a Comprehensive Incident Response Plan Inventory
A comprehensive inventory is crucial for efficient incident response. This inventory should include details on all critical systems, data assets, and their associated vulnerabilities. It should also document existing security controls, recovery procedures, and contact information for key personnel. Think of it as a detailed map of your digital landscape, highlighting both strengths and weaknesses. Regular updates are essential to keep this inventory accurate and relevant.
For example, the inventory should reflect any changes in infrastructure, software updates, or personnel changes within the organization.
Communication Protocol for Internal and External Stakeholders
Effective communication is paramount during an incident. Your plan should clearly Artikel communication channels and protocols for internal teams (IT, legal, PR, etc.) and external stakeholders (customers, partners, regulatory bodies). This might involve pre-defined templates for press releases, internal notifications, and regulatory reporting. Consider establishing a central communication hub, perhaps a dedicated communication platform or a designated individual responsible for disseminating timely and accurate information.
A well-defined escalation path is also essential to ensure critical information reaches the appropriate individuals promptly.
Prioritized List of Potential Incidents and Their Associated Impact Levels
Proactive identification of potential incidents is key to preparedness. This involves brainstorming various scenarios, such as malware infections, data breaches, denial-of-service attacks, and insider threats. Each scenario should be assigned a severity level based on its potential impact on business operations, reputation, and legal compliance. This prioritization helps focus resources on the most critical threats and ensures a swift and effective response.
For instance, a ransomware attack resulting in data loss would likely be prioritized higher than a minor phishing attempt.
Process for Regularly Reviewing and Updating the Incident Response Plan
A static plan is a useless plan. Regular review and updates are essential to maintain the plan’s relevance and effectiveness. This should involve periodic tabletop exercises to simulate incident scenarios, testing response procedures, and identifying areas for improvement. Updates should also incorporate lessons learned from past incidents, changes in technology, and evolving threat landscapes. A schedule should be established for these reviews, perhaps quarterly or annually, depending on the organization’s risk profile and the dynamic nature of its IT environment.
Roles, Responsibilities, and Contact Information for the Incident Response Team, 6 essential steps for an effective incident response plan
Clear roles and responsibilities are vital for coordinated response. The following table Artikels a sample structure; adapt it to your specific needs.
| Role | Responsibility | Contact Information | On-Call Schedule |
|---|---|---|---|
| Incident Commander | Overall incident management | [Name], [Email], [Phone] | Rotating weekly |
| Security Analyst | Technical investigation and containment | [Name], [Email], [Phone] | 24/7 on-call rotation |
| Legal Counsel | Legal and regulatory compliance | [Name], [Email], [Phone] | On-call as needed |
| Public Relations | External communication | [Name], [Email], [Phone] | On-call as needed |
Identification
The second crucial step in any effective incident response plan is swift and accurate identification. This involves not only detecting a potential security incident but also confirming its existence and determining its scope. Misidentification can lead to wasted resources and a delayed response, potentially exacerbating the damage. Therefore, a clear and efficient process is essential.
Identifying security incidents requires a multi-faceted approach, leveraging various detection methods tailored to different types of threats. These methods range from automated security tools constantly monitoring network traffic and system logs to manual analysis of user reports and unusual activity. The speed and accuracy of this identification phase directly impact the overall effectiveness of the incident response.
Methods for Detecting Security Incidents
Effective incident detection relies on a combination of automated and manual methods. Automated systems provide continuous monitoring, alerting security teams to potential issues. Manual analysis, on the other hand, is crucial for investigating suspicious activity that might not trigger automated alerts.
- Security Information and Event Management (SIEM) systems: These systems collect and analyze security logs from various sources, identifying patterns indicative of malicious activity. For example, a SIEM might detect a sudden surge in failed login attempts from a single IP address, suggesting a brute-force attack.
- Intrusion Detection/Prevention Systems (IDS/IPS): These systems monitor network traffic for malicious patterns, blocking or alerting on suspicious activity. An IDS might detect a port scan, indicating an attempt to identify vulnerabilities on the network.
- Endpoint Detection and Response (EDR) solutions: EDR solutions monitor individual devices for malicious activity, providing detailed insights into compromised systems. An EDR might detect malware execution or unauthorized data exfiltration attempts.
- Vulnerability scanners: Regularly scanning systems for known vulnerabilities helps identify potential entry points for attackers. Identifying a publicly known vulnerability on a web server highlights a potential attack vector.
- User reporting: Employees often play a critical role in incident detection. Encouraging employees to report suspicious emails, websites, or unusual system behavior is crucial.
Verifying the Existence and Scope of a Suspected Incident
Once a potential incident is detected, a thorough verification process is necessary to confirm its existence and determine its impact. This involves systematically investigating the suspected breach to ascertain the affected systems, data compromised, and the potential damage.
- Gather information: Collect all available data related to the suspected incident, including logs, alerts, and user reports.
- Analyze the data: Examine the collected data to identify patterns and determine the nature of the incident. This might involve correlating events from different sources to build a comprehensive picture.
- Confirm the incident: Based on the analysis, confirm whether a security incident has indeed occurred. This might involve validating suspicious activity against known attack techniques or malware signatures.
- Determine the scope: Identify the affected systems, data, and users. This helps prioritize the response efforts and limit further damage.
- Assess the impact: Evaluate the potential consequences of the incident, including financial losses, reputational damage, and legal implications.
Common Indicators of a Potential Security Breach
Recognizing common indicators is vital for early detection. These indicators can vary widely depending on the type of breach but often include unusual system behavior or security alerts.
- Unusual login attempts (e.g., multiple failed logins from unfamiliar locations).
- Unexpected network traffic (e.g., large data transfers to unknown destinations).
- System performance degradation (e.g., slow response times or system crashes).
- Compromised accounts (e.g., unauthorized access to sensitive data).
- Suspicious emails or phishing attempts.
- Unexplained changes to system configurations.
Incident Confirmation Decision-Making Process
A flowchart is essential for visualizing the decision-making process. The flowchart below illustrates a simplified process.
Flowchart Description: The flowchart would begin with a “Suspected Incident?” box. A “Yes” branch leads to a “Gather Information & Analyze” box, which then branches to “Incident Confirmed?” A “Yes” leads to “Determine Scope & Impact,” while a “No” leads to “False Alarm.” The “Determine Scope & Impact” box then leads to the next stage of the incident response plan.
Collecting and Preserving Initial Evidence
Preserving the integrity of evidence is paramount. Improper handling can compromise the investigation and legal proceedings.
- Isolate affected systems: Disconnect compromised systems from the network to prevent further damage and data exfiltration.
- Create forensic images: Create bit-by-bit copies of hard drives and other storage devices to preserve the original data. These images should be verified for accuracy.
- Document all actions: Maintain a detailed log of all actions taken during the investigation, including timestamps and descriptions of the steps involved.
- Use chain of custody procedures: Maintain a record of who handled the evidence and when to ensure its integrity and admissibility in court.
- Employ appropriate tools: Utilize specialized forensic tools to collect and analyze evidence effectively.
Containment
Containment is the crucial third step in incident response, aiming to limit the damage caused by a security incident. It’s about preventing the problem from spreading further and minimizing the impact on your systems and data. Effective containment requires swift action and a well-defined strategy. Think of it as putting out a fire – you need to contain the flames before they engulf the entire building.
The primary goal of containment is to isolate the affected systems or data to prevent further compromise. This involves quickly identifying the scope of the incident and implementing measures to stop the spread of malware, unauthorized access, or data breaches. The sooner you can contain the incident, the less severe the consequences are likely to be.
Isolating Affected Systems
Isolating affected systems involves disconnecting them from the network to prevent further propagation of the threat. This might involve physically unplugging network cables, disabling network interfaces, or using network segmentation tools to isolate the affected systems from the rest of the network. For example, a compromised server could be isolated by disabling its network card or placing it in a separate VLAN.
This prevents the malware from spreading to other machines via network connections. A thorough assessment of network connections is essential before and after isolation.
Disabling Compromised Accounts and Services
Disabling compromised accounts and services is a critical step in limiting the impact of an incident. This prevents attackers from maintaining access to your systems and data. This includes changing passwords for affected accounts, disabling accounts suspected of being compromised, and temporarily shutting down affected services to prevent further exploitation. For instance, if an attacker gains access via a specific web application, disabling that application temporarily limits their access until the vulnerability can be remediated.
Malware Infection Containment Checklist
A structured approach is vital when dealing with a malware infection. This checklist provides a framework for effective containment.
- Disconnect the infected system from the network.
- Disable affected accounts and services.
- Create a forensic image of the infected system (if possible and feasible, for later analysis).
- Initiate a full system scan with updated antivirus software.
- Remove or quarantine identified malicious files.
- Reinstall the operating system if necessary.
- Implement updated security measures to prevent future infections.
Network Segmentation and Other Containment Techniques
Network segmentation divides a network into smaller, isolated segments. This limits the impact of a security breach by containing the threat within a specific segment. Other containment techniques include the use of firewalls, intrusion detection/prevention systems (IDS/IPS), and data loss prevention (DLP) tools. For example, a financial institution might segment its network to isolate sensitive customer data from less sensitive internal systems.
This ensures that if one segment is compromised, the others remain secure.
Securing Affected Data and Preventing Data Exfiltration
Data exfiltration – the unauthorized transfer of data – is a major concern during a security incident. Securing affected data involves identifying the data at risk, securing access to it, and monitoring for any unauthorized attempts to access or transfer it.
- Identify the types and locations of affected data.
- Implement access controls to restrict access to the affected data.
- Monitor network traffic for suspicious activity, such as large data transfers or connections to external IP addresses.
- Use data loss prevention (DLP) tools to detect and prevent sensitive data from leaving the network.
- Consider data encryption to protect data in transit and at rest.
Eradication
Eradication is the crucial fourth step in incident response, focusing on completely removing the root cause of the security incident and restoring systems to a secure state. This goes beyond simply containing the threat; it requires a systematic approach to eliminate malware, patch vulnerabilities, and strengthen security controls to prevent recurrence. Failing to properly eradicate a threat leaves your organization vulnerable to further attacks and potential data breaches.
So, you’re building a rock-solid incident response plan? Remember those six essential steps! Efficient communication is key, and that’s where streamlined application development comes in; check out this article on domino app dev the low code and pro code future to see how it can boost your team’s response time. Back to the plan: don’t forget post-incident analysis – it’s crucial for continuous improvement and preventing future issues.
Effective eradication involves a multi-faceted approach, combining technical expertise with a well-defined process. This includes removing malicious code, patching exploited vulnerabilities, and implementing enhanced security measures to prevent future compromises. The specific methods will vary depending on the nature of the incident, but the underlying principle remains consistent: complete removal of the threat and restoration of a secure operating environment.
Malware Removal Methods
Malware removal necessitates a combination of techniques. This may involve using specialized anti-malware tools to scan and remove malicious files, registry entries, and processes. In some cases, manual removal might be necessary, requiring in-depth analysis of system logs and processes to identify and eliminate the threat. System restore points, if available and unaffected, can be used to revert the system to a pre-infection state.
However, restoring from a backup is often the most reliable method to ensure complete eradication. For persistent threats, advanced techniques like memory forensics might be required to identify and remove rootkits or other deeply embedded malware.
Vulnerability Patching and Security Control Strengthening
Following malware removal, patching known vulnerabilities is paramount. This involves updating operating systems, applications, and firmware with the latest security patches to close any gaps exploited by the attacker. Beyond patching, strengthening security controls involves reviewing and enhancing existing security policies and procedures. This could involve implementing multi-factor authentication (MFA), strengthening access controls, implementing intrusion detection and prevention systems (IDS/IPS), and regularly conducting security awareness training for employees.
A robust security information and event management (SIEM) system can provide valuable insights for future threat detection and prevention.
Remediation Techniques for Different Incident Types
Remediation strategies vary widely based on the type of incident. For example, a ransomware attack requires data recovery from backups, while a phishing incident might involve password resets and employee retraining. A denial-of-service (DoS) attack necessitates identifying and mitigating the source of the attack, potentially involving network filtering or collaborating with internet service providers (ISPs). Data breaches require thorough investigation, notification of affected individuals, and potential legal action.
Each incident demands a tailored approach to restore security and prevent future occurrences.
System and Data Restoration
Restoring systems and data to a secure state is the final, critical step in eradication. This typically involves restoring from backups, ensuring the integrity and authenticity of the restored data. Before restoring data, it’s crucial to verify the backup’s integrity to ensure it is free from malware or corruption. Following restoration, a thorough system scan should be performed to confirm the absence of any remaining malicious code.
Finally, access controls should be re-verified to ensure only authorized users have access to sensitive data.
Tools and Techniques for Eradication
The choice of tools and techniques depends heavily on the type of incident.
Here’s a categorization of tools and techniques:
- Malware Removal: Anti-malware software (e.g., Malwarebytes, Kaspersky), system restore points, manual malware removal tools, memory forensics tools.
- Vulnerability Patching: Patch management software (e.g., Microsoft SCCM, WSUS), vulnerability scanners (e.g., Nessus, OpenVAS).
- Data Recovery: Backup and recovery software (e.g., Veeam, Acronis), data recovery tools (e.g., Recuva, PhotoRec).
- Security Control Enhancement: Intrusion detection/prevention systems (IDS/IPS), firewalls, SIEM systems, multi-factor authentication (MFA) solutions.
- Forensic Analysis: Digital forensics tools (e.g., EnCase, FTK Imager), network monitoring tools (e.g., Wireshark, tcpdump).
Recovery
The recovery phase is arguably the most crucial part of incident response. It’s where we rebuild and restore systems and data to their pre-incident state, ensuring business continuity and minimizing the impact on operations. A well-defined recovery plan, tested regularly, is paramount to a swift and effective response. This involves a structured approach, focusing on restoring system functionality and validating data integrity.Restoring affected systems and data requires a methodical approach.
This process involves bringing systems back online, restoring data from backups, and verifying the integrity of both the systems and the restored data. The speed and efficiency of this phase directly impact the overall recovery time objective (RTO) and recovery point objective (RPO), critical metrics for business continuity.
Data Restoration from Backups
A robust backup and recovery strategy is essential. This includes regular backups of critical data, stored securely offsite, and a clearly defined procedure for restoring that data. The restoration process should follow a phased approach, prioritizing critical systems and data. For example, restoring the database server before restoring application servers. Data verification methods, such as checksum comparisons, are crucial to ensure data integrity after restoration.
A discrepancy would signal a potential issue requiring further investigation and potentially a recovery from an earlier backup.
System Functionality Validation
After restoring systems and data, rigorous testing is needed to validate system functionality and data integrity. This involves running comprehensive tests, including system checks, application tests, and data validation checks. For instance, a financial institution might perform reconciliation checks to verify the accuracy of transaction data after restoring their financial systems. Any discrepancies identified during this validation process require immediate attention to prevent further complications or data loss.
Recovery Checklist
A detailed checklist is vital for a smooth recovery process. This checklist ensures no step is missed, and that the recovery proceeds systematically. The specific tasks will vary based on the nature and scale of the incident, but generally include:
- Verify backup integrity before initiating the restoration process.
- Prioritize system and data restoration based on criticality.
- Restore systems in a controlled environment, if possible, to minimize risks.
- Conduct thorough system and data validation checks after restoration.
- Document all actions taken during the recovery process.
- Perform a post-incident review to identify areas for improvement.
Minimizing Downtime and Ensuring Business Continuity
Minimizing downtime is a key objective during recovery. Strategies include utilizing redundant systems, employing failover mechanisms, and having a disaster recovery site ready. For example, a large e-commerce company might have multiple data centers in different geographical locations to ensure continuous operation even if one center is affected by an incident. A well-defined communication plan, informing stakeholders of the incident and recovery progress, is also critical for maintaining confidence and minimizing disruption.
Regular drills and simulations of the recovery plan can help identify and address potential weaknesses before a real incident occurs.
Post-Incident Activity
The final, and arguably most crucial, step in effective incident response is the post-incident activity. This isn’t just about tidying up; it’s about learning from mistakes, strengthening defenses, and preventing future incidents. A thorough post-incident review allows organizations to transform a negative experience into a valuable opportunity for growth and improved security posture.A comprehensive post-incident review involves a structured process of analyzing the entire incident lifecycle, from initial detection to final recovery.
This analysis should identify not only what went wrong but also what went right, highlighting both successes and failures to provide a holistic understanding of the event. This approach enables a more effective and targeted improvement strategy.
Conducting a Thorough Post-Incident Review
The post-incident review should be conducted by a team comprising members from various departments involved in the incident response, including IT security, operations, and potentially legal. The review should follow a predetermined timeline to ensure timely completion and avoid information decay. The process typically involves gathering all relevant data, including logs, alerts, and communication records. This data is then analyzed to reconstruct the timeline of events, pinpoint weaknesses in the existing security controls, and determine the root cause(s) of the incident.
This phase often includes interviews with individuals involved in the response to gain firsthand perspectives and contextual information.
Documenting Lessons Learned and Identifying Areas for Improvement
A structured framework is essential for documenting lessons learned. A simple yet effective approach involves using a standardized template to capture key details for each incident. This template should include sections for:
- Incident Summary: A concise overview of the incident, including date, time, and a brief description.
- Timeline: A chronological account of events, highlighting key milestones and decision points.
- Root Cause Analysis: A detailed analysis identifying the underlying causes of the incident.
- Impact Assessment: An evaluation of the impact of the incident on the organization, including financial losses, reputational damage, and disruption to operations.
- Lessons Learned: A summary of key insights gained from the incident, including specific actions that could have prevented or mitigated the incident.
- Recommended Improvements: Specific, actionable recommendations for improving the incident response plan and security posture.
This structured approach ensures consistency and facilitates easy comparison across multiple incidents, revealing recurring patterns and systemic vulnerabilities.
Examples of Effective Post-Incident Reports
Effective post-incident reports are concise, factual, and action-oriented. They avoid technical jargon where possible, making them easily understandable to a broad audience. A well-structured report clearly Artikels the incident, its impact, the root cause analysis, and the recommended improvements. For example, a report might detail a phishing attack, explaining how the attacker gained access, the compromised data, the remediation steps taken, and the suggested improvements to employee training and security awareness programs.
Another example might focus on a ransomware attack, detailing the encryption method used, the recovery process, and recommendations for improving backup and recovery procedures. These reports should always prioritize clarity and actionable insights over extensive technical detail.
Implementing Changes Based on Post-Incident Review Findings
Once the post-incident review is complete, the identified improvements should be prioritized and implemented. This requires a clear action plan with assigned responsibilities and deadlines. Regular progress monitoring is crucial to ensure timely implementation. For example, if the review identifies a weakness in vulnerability scanning procedures, the action plan might include implementing a more comprehensive scanning schedule, integrating the scanner with the security information and event management (SIEM) system, and providing additional training to security personnel.
Improving the Incident Response Plan and Security Posture
The findings from the post-incident review should be directly incorporated into the organization’s incident response plan. This might involve updating procedures, improving communication protocols, or enhancing security controls. For instance, if the review reveals a delay in incident detection, the plan might be updated to include more proactive monitoring tools and automated alerts. Similarly, if the review highlights a lack of effective communication during the incident, the plan might be revised to incorporate more robust communication channels and procedures.
This iterative process of review, improvement, and implementation is essential for maintaining a strong and adaptive security posture.
Epilogue
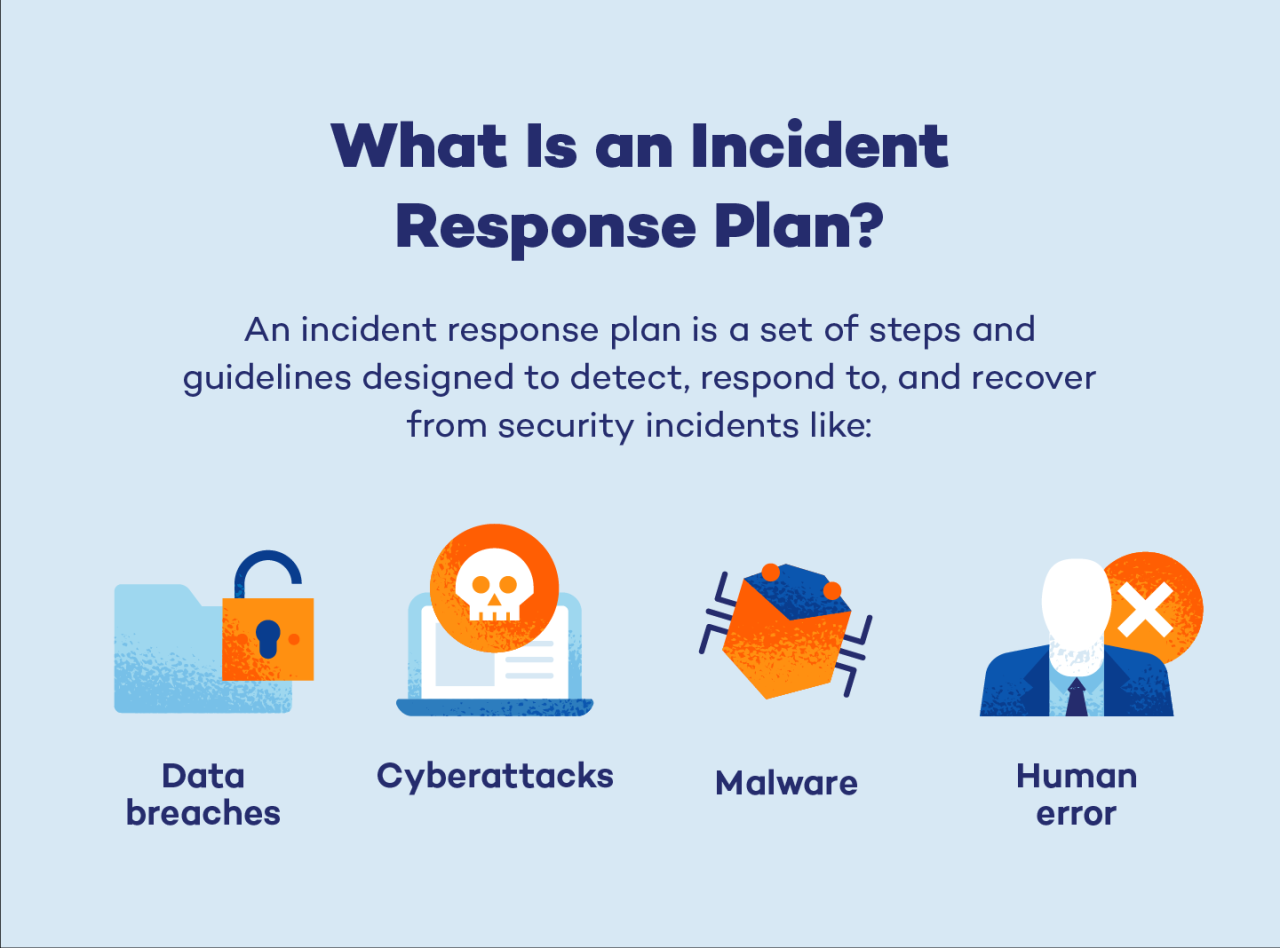
Building a robust incident response plan isn’t a one-time task; it’s an ongoing process. Regular review, updates, and team training are essential to keep your plan relevant and effective. By following these six steps, you’ll not only be better prepared to handle security incidents but also foster a culture of proactive security within your organization. Remember, a well-defined plan isn’t just about damage control; it’s about peace of mind and the ability to bounce back stronger from any challenge.
Popular Questions
What if we don’t have a dedicated IT team?
Even small businesses need a plan. Consider outsourcing parts of your response, or assigning roles to existing staff with clear responsibilities and training.
How often should we test our incident response plan?
Regular testing is crucial. Aim for at least annual simulations, and more frequently if you make significant system changes.
What kind of documentation is essential in a post-incident review?
Detailed logs, timelines, communication records, and a comprehensive analysis of what happened, what worked, and what needs improvement are key.
What’s the difference between containment and eradication?
Containment is about stopping the spread of an incident; eradication is about completely removing the threat.
How do I choose the right tools for my incident response plan?
The best tools depend on your specific needs and resources. Consider factors like budget, system complexity, and the types of threats you face. Research and compare options before making a decision.