
Embracing the Benefits of LLM Securely
Embracing the benefits of LLM securely is crucial in today’s rapidly evolving technological landscape. LLMs offer incredible potential across various sectors, from revolutionizing customer service with AI chatbots to powering groundbreaking medical research. However, this potential comes with significant security challenges. This post delves into the critical aspects of securing LLM deployments, exploring everything from mitigating bias and protecting data privacy to designing robust security monitoring systems and building user trust.
We’ll examine the inherent risks associated with LLMs, including vulnerabilities to adversarial attacks and the ethical considerations of deploying powerful AI models. We’ll also explore practical strategies for implementing secure development practices, ensuring fairness, and complying with data privacy regulations like GDPR and CCPA. Ultimately, the goal is to harness the transformative power of LLMs while mitigating the risks and building a future where AI benefits everyone safely and responsibly.
Understanding LLM Capabilities and Limitations
Large Language Models (LLMs) are transforming various sectors, offering unprecedented potential. However, their deployment necessitates a thorough understanding of both their capabilities and inherent limitations, especially concerning security. This understanding is crucial for responsible innovation and risk mitigation.
LLM Potential Benefits Across Sectors
LLMs are proving invaluable across numerous fields. In healthcare, they assist in diagnosis, drug discovery, and personalized medicine by analyzing vast medical datasets. Financial institutions leverage LLMs for fraud detection, risk assessment, and algorithmic trading, improving efficiency and accuracy. The legal sector benefits from LLMs’ ability to analyze legal documents, predict case outcomes, and automate legal research. In education, LLMs personalize learning experiences and provide instant feedback to students.
Customer service is revolutionized through LLMs’ ability to provide 24/7 support and handle complex queries. These are just a few examples of the transformative power of LLMs.
Inherent Risks and Vulnerabilities of LLM Deployment
Despite their benefits, LLMs present significant security challenges. One major concern is data poisoning, where malicious actors inject biased or inaccurate data into the training dataset, leading to flawed and potentially harmful outputs. Another risk is prompt injection, where attackers craft malicious prompts to manipulate the LLM into revealing sensitive information or performing unintended actions. Model extraction attacks aim to steal the model’s intellectual property by repeatedly querying it and analyzing its responses.
Furthermore, LLMs can be vulnerable to adversarial attacks, where subtle modifications to input data can drastically alter the output, leading to unpredictable and potentially dangerous consequences. Finally, the sheer scale of data processed by LLMs creates significant privacy concerns, particularly if sensitive information is included in the training data or used in queries.
Security Implications of Different LLM Architectures
The security implications vary depending on the LLM architecture. Transformer-based models, while powerful, are often more susceptible to adversarial attacks due to their reliance on attention mechanisms. Recurrent Neural Networks (RNNs), on the other hand, might be less vulnerable to these specific attacks but can suffer from other security weaknesses. Federated learning approaches, which train models on decentralized data, offer enhanced privacy but introduce new challenges in ensuring data integrity and model robustness.
The choice of architecture significantly impacts the overall security posture and necessitates a tailored security strategy.
Comparison of Security Measures for LLMs
The following table Artikels the strengths and weaknesses of various security measures for LLMs:
| Security Measure | Strengths | Weaknesses | Suitable for |
|---|---|---|---|
| Data sanitization and preprocessing | Reduces risk of data poisoning and bias | Can be computationally expensive and may not eliminate all risks | All LLM deployments |
| Input validation and sanitization | Mitigates prompt injection attacks | Requires careful design and implementation; can impact usability | All LLM deployments |
| Differential privacy | Enhances data privacy during training | Can reduce model accuracy; complex to implement | Training datasets with sensitive information |
| Model watermarking | Helps detect unauthorized model copies | Can be circumvented with sophisticated techniques | Protecting intellectual property |
Implementing Secure LLM Development Practices
Building and deploying LLMs responsibly requires a robust security framework throughout the entire development lifecycle. Ignoring security best practices can lead to vulnerabilities that expose sensitive data, compromise model integrity, and even enable malicious actors to manipulate the system for nefarious purposes. This section Artikels key strategies for developing secure LLM applications.
Secure Software Development Lifecycle for LLMs
A secure SDLC for LLMs extends traditional software development practices to specifically address the unique security challenges posed by these powerful models. This includes incorporating security considerations from the initial design phase, through development, testing, and deployment, and finally, ongoing monitoring and maintenance. A key difference lies in the emphasis on data security and model integrity throughout the entire process.
For example, rigorous data sanitization should be implemented at every stage, from data collection and preprocessing to model training and deployment. Regular security audits and penetration testing should be conducted to identify and address potential vulnerabilities before they can be exploited. Furthermore, the development team needs to be trained on secure coding practices specifically for LLMs, understanding the potential attack vectors and mitigation techniques.
Data Sanitization and Input Validation Best Practices
Effective data sanitization and input validation are critical for preventing data poisoning and adversarial attacks. Before feeding data into an LLM, it’s crucial to remove or neutralize potentially harmful elements. This includes techniques like removing personally identifiable information (PII), scrubbing sensitive s, and applying robust input validation to prevent unexpected or malicious inputs from affecting the model’s behavior.
For example, input validation should ensure that all inputs conform to the expected data type and format, preventing unexpected behavior or crashes. Regularly updating and improving these sanitization and validation processes is essential, as new attack vectors are constantly emerging. Failure to do so could leave the LLM vulnerable to manipulation. A well-designed input validation system can significantly reduce the risk of adversarial attacks by filtering out malicious or unexpected inputs before they can reach the model.
Detecting and Mitigating Adversarial Attacks
Adversarial attacks aim to manipulate the LLM’s output by introducing carefully crafted inputs. These attacks can range from subtle perturbations in input data to more sophisticated techniques designed to exploit vulnerabilities in the model’s architecture. Methods for detecting these attacks include anomaly detection, which flags unusual input patterns or model outputs that deviate from expected behavior. Another approach involves using adversarial training, where the model is trained on adversarial examples to improve its robustness.
Furthermore, employing techniques like input regularization and output filtering can help mitigate the impact of successful attacks. Regular monitoring of the model’s performance and behavior is crucial for early detection of potential adversarial activity. For example, a sudden drop in accuracy or unusual output patterns could indicate an ongoing attack.
Robust Authentication and Authorization Mechanisms
Securing access to LLM services requires robust authentication and authorization mechanisms. Strong password policies, multi-factor authentication (MFA), and role-based access control (RBAC) are essential for preventing unauthorized access. API keys and access tokens should be carefully managed and rotated regularly to minimize the risk of compromise. Detailed logging and monitoring of all access attempts are crucial for detecting and responding to security incidents.
For instance, implementing RBAC ensures that only authorized users can access specific LLM functionalities, preventing unauthorized access to sensitive data or model parameters. Regular security audits and penetration testing of the authentication and authorization systems are vital to identify and address vulnerabilities.
Mitigating Bias and Ensuring Fairness in LLMs
Large language models (LLMs) are trained on massive datasets, and these datasets inevitably reflect the biases present in the real world. This means LLMs can inadvertently perpetuate and even amplify harmful stereotypes and prejudices in their outputs, leading to unfair or discriminatory outcomes. Addressing this issue is crucial for responsible LLM development and deployment.
Bias in LLMs manifests in various ways, impacting different aspects of their performance and application. Understanding these manifestations is the first step towards developing effective mitigation strategies.
Sources of Bias in LLM Training Data and Outputs
The biases present in an LLM’s output are directly linked to the biases present in its training data. This data often comes from sources like books, articles, websites, and code, all of which may contain biased or skewed representations of certain groups or topics. For example, a dataset heavily skewed towards male authors might lead an LLM to generate text that predominantly features male characters or perspectives.
Similarly, datasets reflecting historical prejudices can result in outputs that reinforce harmful stereotypes about race, gender, religion, or other sensitive attributes. The selection process for the training data itself can introduce bias, as can the way the data is pre-processed and cleaned before being fed to the model. Finally, the model’s architecture and training algorithms can also inadvertently amplify existing biases.
Strategies for Mitigating Bias and Promoting Fairness in LLM Applications
Several strategies can be employed to mitigate bias and promote fairness in LLMs. Data preprocessing techniques, such as re-weighting samples from underrepresented groups or removing biased data points, can help to balance the training data. Adversarial training, where the model is trained to resist adversarial examples designed to expose its biases, is another promising approach. Furthermore, developing techniques for post-processing LLM outputs, such as using fairness-aware ranking algorithms or incorporating human-in-the-loop feedback mechanisms, can help to filter out biased or unfair predictions.
Finally, careful selection and curation of training data, combined with rigorous evaluation of the model’s performance across different demographic groups, are crucial steps in ensuring fairness.
Techniques for Evaluating the Fairness and Ethical Implications of LLM Outputs
Evaluating the fairness of LLM outputs requires a multi-faceted approach. One common method is to measure the model’s performance across different demographic groups, using metrics such as accuracy, precision, and recall. Significant disparities in performance across groups may indicate the presence of bias. Furthermore, qualitative assessments, involving human evaluation of the model’s outputs for bias and fairness, can provide valuable insights.
These assessments can involve rating the outputs on scales measuring offensiveness, stereotyping, and overall fairness. Finally, techniques like counterfactual fairness analysis, which assesses how the model’s predictions would change if a protected attribute (e.g., gender or race) were altered, can help to identify and address potential sources of bias.
Ethical Considerations for Responsible LLM Development and Deployment
Before deploying an LLM, several ethical considerations must be addressed. This includes ensuring the model’s outputs are not discriminatory or harmful, protecting user privacy, and maintaining transparency about the model’s limitations and potential biases. It is crucial to develop clear guidelines and procedures for addressing bias and ensuring fairness throughout the entire LLM lifecycle, from data collection and model training to deployment and monitoring.
Regular audits and evaluations of the model’s performance are essential to identify and address emerging biases or ethical concerns. Furthermore, open communication with stakeholders, including users and the wider community, is vital to build trust and ensure responsible use of LLMs.
Protecting Data Privacy in LLM Systems
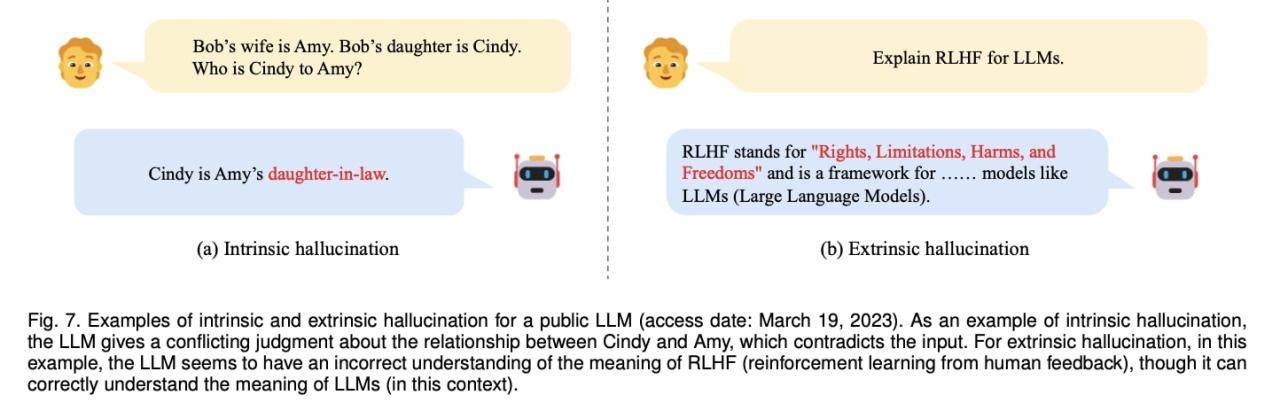
The increasing use of Large Language Models (LLMs) necessitates robust strategies for safeguarding sensitive data. LLMs are trained on massive datasets, often including personally identifiable information (PII), making data privacy a critical concern. Effective protection requires a multi-faceted approach encompassing data anonymization, compliance with regulations, and secure data management practices.
Data Anonymization and Protection Techniques
Protecting sensitive data during LLM training is paramount. Several techniques can help anonymize data, reducing the risk of re-identification. Differential privacy, for instance, adds carefully calibrated noise to the data, making it statistically useful while preserving individual privacy. Data masking replaces sensitive elements with pseudonyms or substitutes, obscuring direct links to individuals. Federated learning allows training on decentralized data sources without directly sharing the data itself.
These methods, when applied strategically, significantly mitigate the risks associated with training LLMs on sensitive datasets.
Compliance with Data Privacy Regulations
Adherence to regulations like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) is non-negotiable. GDPR, for example, mandates data minimization, purpose limitation, and the right to be forgotten. CCPA grants consumers rights regarding their personal information, including the right to access, delete, and opt-out of data sales. Building LLMs requires careful consideration of these regulations at every stage, from data collection and preprocessing to model deployment and ongoing monitoring.
Compliance necessitates robust data governance frameworks and mechanisms for handling data subject requests. For example, a company developing an LLM for customer service needs to ensure all data used is compliant with relevant regulations and that processes are in place to handle customer requests to access, correct, or delete their data.
Secure Data Storage and Access Control Mechanisms
Secure storage and access control are vital for protecting data used in LLM applications. Employing encryption, both in transit and at rest, is crucial. This prevents unauthorized access to sensitive data even if a breach occurs. Access control mechanisms, such as role-based access control (RBAC), restrict access to data based on user roles and permissions. Data should be stored in secure environments, like cloud platforms with robust security features, and access should be carefully monitored and audited.
For instance, only authorized personnel with specific roles should have access to the training data, and all access attempts should be logged for auditing purposes. Furthermore, implementing robust authentication and authorization mechanisms is critical to prevent unauthorized access to the LLM system and its associated data.
Data Flow in a Secure LLM System
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| Data Collection |---->| Data Anonymization|---->| Model Training |---->| Model Deployment|
+-----------------+ +-----------------+ +-----------------+ +-----------------+
^ |
| v
+---------------------------------------------------------------------+
| Secure Storage & Access Control |
+-------------------------------------------------+
This flowchart illustrates a simplified data flow.
Data is collected, anonymized using techniques described earlier, then used for model training. The trained model is deployed securely, with continuous monitoring and access control throughout the entire process. The secure storage and access control mechanism underpins the entire system, ensuring that data remains protected at every stage.
Monitoring and Responding to Security Incidents
Protecting LLMs requires a proactive approach to security, and a robust monitoring system is the cornerstone of this approach. A breach isn’t just a technical issue; it can lead to reputational damage, financial losses, and legal repercussions. Therefore, continuous monitoring and a well-defined incident response plan are crucial.
Effective monitoring goes beyond simple alerts. It involves a multi-layered approach designed to detect anomalies and potential threats in real-time. This includes tracking system logs for unusual activity, monitoring API calls for suspicious patterns, and continuously assessing the model’s outputs for unexpected or harmful behavior. Furthermore, regular security audits and penetration testing are vital for identifying vulnerabilities before they can be exploited.
Designing a Comprehensive Security Monitoring System for LLMs
A comprehensive security monitoring system for LLMs needs to encompass several key areas. Firstly, it should include real-time logging of all LLM activities, including input prompts, model responses, and processing times. This data can be analyzed to identify anomalies and potential attacks. Secondly, the system should incorporate intrusion detection systems (IDS) and security information and event management (SIEM) tools to monitor network traffic and identify malicious activities.
Thirdly, regular vulnerability scanning and penetration testing should be conducted to proactively identify and address weaknesses in the system. Finally, the system needs to be able to automatically alert security personnel of any suspicious activity, allowing for rapid response. This may involve automated alerts based on pre-defined thresholds or machine learning models trained to detect anomalous behavior.
Procedures for Detecting and Responding to Security Breaches
Detecting a security breach often involves analyzing system logs for unusual activity. This could include a sudden spike in API calls from an unexpected source, unusually long processing times, or the generation of outputs that deviate significantly from the expected behavior. Once a breach is suspected, the first step is to contain the damage. This involves isolating the affected system, preventing further unauthorized access, and gathering forensic evidence.
Next, a thorough investigation should be conducted to determine the root cause of the breach and its extent. This investigation should involve analyzing logs, network traffic, and the LLM’s internal state. Finally, appropriate remediation steps should be taken to fix the vulnerability and prevent future breaches. This might involve patching software, updating security configurations, or retraining the LLM model.
Incident Response Plans for LLM-Related Security Incidents
A well-defined incident response plan is crucial for minimizing the impact of a security breach. Such a plan should Artikel roles and responsibilities, communication protocols, and escalation procedures. For example, a hypothetical incident response plan might involve a dedicated security team responsible for investigating and containing the breach, a communication team responsible for informing stakeholders, and a legal team responsible for managing any legal ramifications.
The plan should also include pre-defined procedures for different types of incidents, such as data breaches, denial-of-service attacks, and unauthorized access. Regular drills and simulations should be conducted to ensure the plan is effective and that the team is prepared to respond to real-world incidents.
Strategies for Recovering from LLM-Related Security Incidents, Embracing the benefits of llm securely
Recovery from a security incident involves several steps. First, the affected system needs to be restored to a secure state. This might involve restoring from backups, reinstalling software, or rebuilding the system from scratch. Next, the LLM model itself might need to be retrained or replaced if it has been compromised. Finally, it is crucial to review and update the security monitoring system and incident response plan to prevent similar incidents from happening in the future.
This includes analyzing the root cause of the breach, identifying any weaknesses in the system, and implementing appropriate countermeasures. A post-incident review should be conducted to evaluate the effectiveness of the response and identify areas for improvement. For example, a company might discover a weakness in their authentication system and implement multi-factor authentication as a result of an incident.
Building Trust and Transparency in LLM Systems: Embracing The Benefits Of Llm Securely

Building trust in Large Language Models (LLMs) is paramount for their successful and secure adoption. Users need to understand how these systems work and what their limitations are to confidently utilize them. Transparency and explainability are key to fostering this trust, alongside robust mechanisms for addressing potential concerns and ensuring responsible use.
Methods for Enhancing Transparency and Explainability
Enhancing the transparency of LLM decision-making involves providing insights into the internal processes that lead to a particular output. This can be achieved through various techniques. One approach is to develop methods for visualizing the model’s attention mechanisms, highlighting which parts of the input text most influenced the generated response. This allows users to see the reasoning behind the LLM’s conclusions, increasing their understanding and confidence.
Embracing the benefits of LLMs securely is crucial, especially as we integrate them into increasingly complex systems. This careful approach extends to application development, and I’ve been exploring how this plays out with the exciting advancements in domino app dev, the low-code and pro-code future , which offers powerful tools while demanding robust security considerations. Ultimately, securely harnessing LLMs means proactively addressing potential vulnerabilities across the entire development lifecycle.
Another promising area is the development of interpretable models, which are designed from the ground up to be more easily understood. These models might use simpler architectures or incorporate mechanisms that explicitly track the reasoning process. Finally, providing model cards – documents that describe the model’s capabilities, limitations, and potential biases – can significantly improve transparency and allow users to make informed decisions about their use.
Mechanisms for Building User Trust
Building user trust requires a multi-faceted approach. Clear and concise communication about the LLM’s capabilities and limitations is crucial. This includes openly acknowledging the potential for errors and biases. Providing mechanisms for users to provide feedback and report issues is equally important. This feedback loop allows developers to identify and address problems, demonstrating responsiveness and commitment to improving the system.
Furthermore, independent audits and certifications can significantly boost user confidence, providing external validation of the system’s security and reliability. For example, a system might receive certification demonstrating its compliance with relevant data privacy regulations. This third-party validation reassures users that their data is being handled responsibly.
Embracing the benefits of LLMs securely is crucial, especially as we increasingly rely on cloud services. Understanding and managing your cloud security posture is paramount, and that’s where understanding solutions like bitglass and the rise of cloud security posture management becomes vital. By prioritizing robust security measures, we can safely unlock the incredible potential of LLMs without compromising sensitive data.
The Importance of User Education and Awareness
User education is essential for fostering secure LLM adoption. Users need to understand the potential risks associated with using LLMs, such as the possibility of biased outputs or the risk of data breaches. Providing clear and accessible educational resources, such as tutorials, FAQs, and online courses, can help users develop a better understanding of these technologies and how to use them safely.
Promoting responsible use through clear guidelines and best practices is also vital. For example, educating users about the importance of critically evaluating LLM outputs and not relying on them blindly is crucial. Regular updates and communication about security improvements further strengthen trust and demonstrate a commitment to user safety.
Best Practices for Communicating Security Information to Users
| Communication Method | Content | Frequency | Accessibility |
|---|---|---|---|
| Model Cards | Detailed description of model capabilities, limitations, biases, and training data. | One-time, updated as needed. | Easily accessible online, linked from the system interface. |
| FAQs | Answers to common user questions about security and privacy. | Continuously updated. | Prominently displayed on the system website and within the application. |
| Security Bulletins | Notifications of significant security updates, vulnerabilities, or incidents. | As needed. | Email notifications, in-app alerts, and website announcements. |
| Privacy Policy | Clear explanation of how user data is collected, used, and protected. | Updated annually or as needed. | Easily accessible on the system website and within the application. |
Summary
Successfully embracing the benefits of LLMs securely requires a multi-faceted approach. It’s not just about implementing technical safeguards; it’s about fostering a culture of responsible AI development and deployment. By understanding the limitations, proactively mitigating risks, and prioritizing ethical considerations, we can unlock the transformative potential of LLMs while ensuring a secure and equitable future for all. This ongoing journey demands constant vigilance, adaptation, and a commitment to continuous improvement in both technology and ethical practice.
General Inquiries
What are adversarial attacks against LLMs?
Adversarial attacks involve manipulating inputs to an LLM to produce unintended or malicious outputs. These attacks can range from subtle changes in text to more sophisticated techniques aimed at exploiting vulnerabilities in the model’s architecture.
How can I ensure my LLM application complies with GDPR?
GDPR compliance requires careful consideration of data processing, storage, and user rights. This includes implementing appropriate technical and organizational measures to protect personal data, providing transparency to users about data usage, and ensuring users have the right to access, correct, or delete their data.
What are some common sources of bias in LLMs?
Bias in LLMs often stems from biased training data, reflecting societal prejudices present in the text and data used to train the model. This can lead to unfair or discriminatory outcomes. Careful data curation and bias mitigation techniques are essential.
How can I build user trust in my LLM-powered system?
Building trust involves transparency about how the LLM works, clearly communicating its limitations, and providing mechanisms for users to understand and challenge its decisions. Regular audits and independent verification can also help.




