
The Man Behind Kimwolf: An Investigation into the Identity of "Dort" and the Escalating Cyberattacks
In early January 2026, KrebsOnSecurity brought to light the alarming discovery of a critical vulnerability that served as the foundation for Kimwolf, a botnet that had rapidly ascended to become the world’s largest and most disruptive. Since that revelation, the individual orchestrating Kimwolf’s operations, known by the online moniker "Dort," has engaged in a calculated and aggressive campaign of retaliation. This campaign has included a relentless barrage of distributed denial-of-service (DDoS) attacks, doxing operations, and email flooding targeted at the security researcher who initially exposed the vulnerability and this author. Most recently, Dort’s actions escalated to a chilling extreme: orchestrating a swatting incident, falsely reporting a serious crime at the researcher’s home to dispatch a heavily armed police tactical team. This in-depth investigation aims to synthesize available public information to shed light on the identity and activities of "Dort."
The Genesis of Dort: From Minecraft Cheats to Global Disruption
The digital footprint of "Dort" suggests a trajectory from amateur hacking in online gaming communities to involvement in sophisticated cybercriminal enterprises. Publicly available information, including a "dox" circulated in 2020, asserted that Dort was a Canadian teenager, reportedly born in August 2003, who also used the aliases "CPacket" and "M1ce."
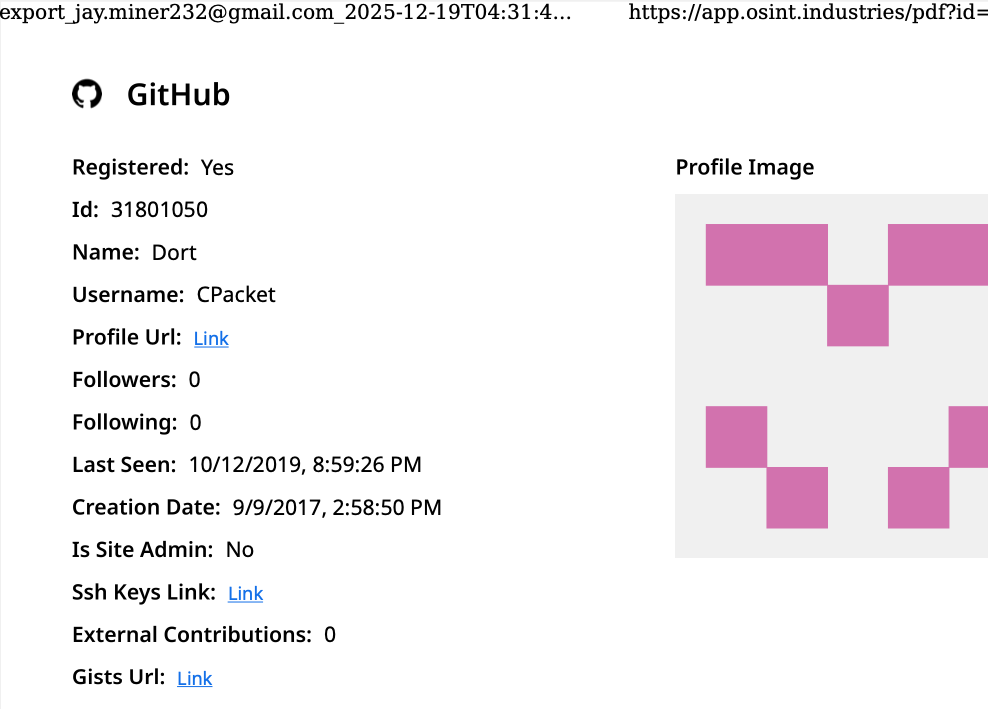
A deep dive into the username "CPacket" on the open-source intelligence platform OSINT Industries reveals a GitHub account created in 2017. This account, associated with both "Dort" and "CPacket," utilized the email address [email protected]. This email address appears to be a central node in tracing Dort’s early online activities.
Further analysis by the cyber intelligence firm Intel 471 indicates that [email protected] was instrumental in the creation of multiple accounts across various cybercrime forums between 2015 and 2019. These included platforms like Nulled, where the username was "Uubuntuu," and Cracked, where the user was identified as "Dorted." Intel 471’s findings are particularly significant as they report that both of these accounts were registered from the same Internet Protocol (IP) address originating from Rogers Communications in Canada (specifically, 99.241.112.24). This geographic linkage strengthens the assertion of Dort’s Canadian origins.
Dort’s initial notoriety stemmed from their active participation in the popular Microsoft game, Minecraft. Here, they developed and distributed "Dortware," a software suite designed to enable cheating for other players. This early foray into developing tools for circumventing game rules appears to have been a stepping stone, transitioning from illicit gaming enhancements to enabling more serious criminal endeavors on a global scale.
Escalation to Cybercrime Forums and the LAPSUS$ Connection
The evolution of Dort’s online persona is marked by the adoption of the nickname "DortDev." In March 2022, this identity was active on the chat server of the notorious cybercrime group LAPSUS$. This association places Dort within a network known for high-profile data breaches and extortion campaigns against major corporations.
On these platforms, Dort actively promoted and sold services such as temporary email address registration and "Dortsolver." Dortsolver is a piece of code capable of bypassing various CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) services, which are designed to prevent automated account abuse and bot activity. These offerings were openly advertised in 2022 on SIM Land, a Telegram channel dedicated to SIM-swapping and account takeover activities, indicating a move towards monetizing tools for more pervasive cybercrimes.
Collaboration and Financial Exploitation: The Role of "Qoft"
Evidence gathered by the cyber intelligence firm Flashpoint further illuminates Dort’s collaborative activities. Flashpoint indexed posts from 2022 on SIM Land, detailing how Dort developed their disposable email and CAPTCHA bypass services in conjunction with another hacker operating under the handle "Qoft."

In a revealing online exchange from 2022, Qoft explicitly stated, "I legit just work with Jacob," referring to Dort as their exclusive business partner. Qoft further boasted about their joint exploits, claiming they had collectively stolen over $250,000 worth of Microsoft Xbox Game Pass accounts. This was achieved by developing a program that could mass-create Game Pass identities using compromised payment card data. This admission directly links Dort, under the name Jacob, to significant financial fraud.
Identifying "Jacob": Tracing the Digital Breadcrumbs
The identity of "Jacob," as referred to by Qoft, has been a crucial element in piecing together Dort’s profile. Constella Intelligence, a breach tracking service, discovered that the password used for the [email protected] account was reused by only one other email address: [email protected]. This finding aligns remarkably with the 2020 doxing information that placed Dort’s birthdate in August 2003 (8/03), suggesting a connection between these two email addresses and the individual.
A search for [email protected] on DomainTools.com revealed its use in 2015 to register several Minecraft-themed domain names. These registrations were consistently attributed to a "Jacob Butler" residing in Ottawa, Canada, and linked to the Ottawa phone number 613-909-9727.
Constella Intelligence’s data further indicates that [email protected] was used to create an account on the hacker forum Nulled in 2016. Additionally, the same email address was associated with the Minecraft username "M1CE," one of the aliases previously linked to Dort. By pivoting off the password used for the Nulled account, further connections were uncovered. This password was shared across the email addresses [email protected] (a slight variation of the original) and [email protected]. The latter email address is particularly noteworthy as it is associated with a domain belonging to the Ottawa-Carleton District School Board, suggesting a potential link to Dort’s educational background.
Data indexed by Spycloud, another breach tracking service, suggests that at one point, Jacob Butler may have shared a computer with his mother and a sibling. This familial connection could potentially explain why their email accounts were linked to the password "jacobsplugs." Efforts to solicit comments from Jacob Butler or other members of the Butler household regarding these findings were unsuccessful at the time of reporting.
The "MemeClient" Identity and the Escalation to Swatting
The open-source intelligence service Epieos identified [email protected] as the creator of the GitHub account "MemeClient." This discovery provides another piece of the puzzle. Flashpoint had previously indexed a deleted anonymous post on Pastebin.com from 2017, which explicitly stated that "MemeClient" was the creation of a user known as "CPacket" – one of Dort’s earliest known monikers. This establishes a clear lineage from early Minecraft-related activities to more sophisticated tool development.
The intense, retaliatory actions taken by Dort following the publication of the Kimwolf botnet investigation underscore the personal impact of the exposure. On January 2, 2026, KrebsOnSecurity published "The Kimwolf Botnet is Stalking Your Local Network," an article detailing research by Benjamin Brundage, founder of the proxy tracking service Synthient. Brundage’s investigation revealed how Kimwolf operators were exploiting a little-known vulnerability in residential proxy services to infect poorly secured devices, such as TV boxes and digital photo frames, connected to the internal networks of proxy endpoints.
By the time this article was published, many of the affected proxy providers had been notified by Brundage and had begun patching the vulnerabilities, significantly hindering Kimwolf’s expansion capabilities. Within hours of the article’s release, Dort retaliated by creating a Discord server bearing this author’s name. This server was used to disseminate personal information and issue violent threats against Brundage, KrebsOnSecurity, and others involved in the investigation.
The Escalation to Swatting and Threats of Violence
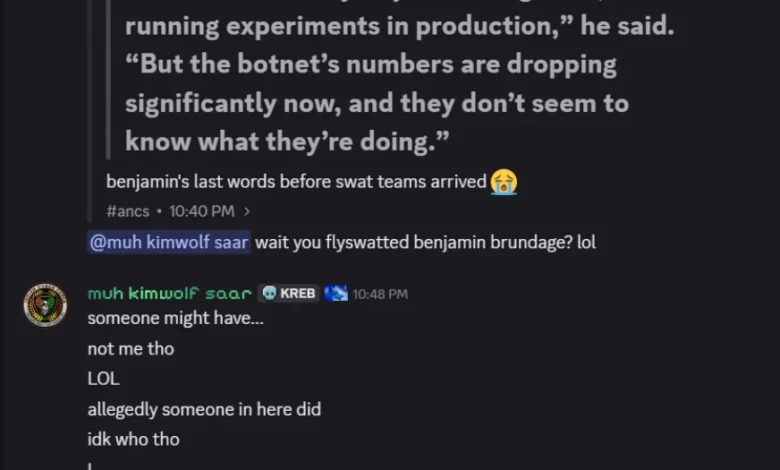
The situation escalated dramatically in the week preceding this report. Dort and associates, using the Discord server (which was then named "Krebs’s Koinbase Kallers"), orchestrated and threatened a swatting attack against Benjamin Brundage. This involved posting his home address and personal details, leading to a false police report and a visit from local law enforcement officers to his residence. During this incident, another member of the server posted a door emoji and further taunted Brundage, adding a layer of psychological warfare to the physical threat.
Adding a disturbing layer to these events, a link to a SoundCloud track, a vitriolic "diss track" recorded by DortDev, was shared on the server. The track included a pinned message from Dort stating, "Ur dead nigga. u better watch ur fucking back. sleep with one eye open. bitch." The lyrics themselves were chillingly specific, referencing the potential consequences of a swatting incident: "It’s a pretty hefty penny for a new front door… If his head doesn’t get blown off by SWAT officers. What’s it like not having a front door?" This direct endorsement and lyrical threat of swatting, combined with the actual swatting incident, paints a grim picture of Dort’s escalating criminal behavior and their willingness to employ extreme tactics.
Jacob Butler’s Response and Disputed Timeline
In an update to the investigation, Jacob Butler did respond to requests for comment, speaking briefly with KrebsOnSecurity via telephone. Butler stated that he had not noticed earlier requests for comment because he had not been actively online since 2021, citing a period where his home was repeatedly targeted by swatting incidents.
He acknowledged developing and distributing a Minecraft cheat in the past but asserted that he had not played the game in years and had no involvement in "Dortsolver" or any other activities attributed to the "Dort" nickname after 2021. "It was a really old cheat and I don’t remember the name of it," Butler stated, regarding his Minecraft modification. "I’m very stressed, man. I don’t know if people are going to swat me again or what. After that, I pretty much walked away from everything, logged off and said fuck that. I don’t go online anymore. I don’t know why people would still be going after me, to be completely honest."
When questioned about his current occupation, Butler indicated that he primarily stays at home, assisting his mother, due to struggles with autism and social interaction. He maintained that it was highly probable that one or more of his old accounts had been compromised and that someone else was impersonating him online as "Dort." "Someone is actually probably impersonating me, and now I’m really worried," Butler expressed. "This is making me relive everything."
However, significant discrepancies exist within Butler’s timeline. His voice during the phone conversation bore a striking resemblance to the "Jacob/Dort" whose voice was captured in a September 2022 YouTube recording of a "Clash of Code" competition. In this recording, Dort exhibited a torrent of profanity remarkably similar to the language used in the diss rap threatening Benjamin Brundage. Furthermore, at approximately the 26-minute mark of the competition recording, Dort can be heard explicitly threatening to swat their opponent.
When confronted with this evidence, Butler dismissed the voice similarity, claiming it was not his own but rather that of an impersonator who had likely cloned his voice. "I would like to clarify that was absolutely not me," Butler stated. "There must be someone using a voice changer. Or something of the sorts. Because people were cloning my voice before and sending audio clips of ‘me’ saying outrageous stuff."
Implications and Future Trajectory
The case of "Dort" and the Kimwolf botnet highlights a concerning trend in the cybercriminal landscape: the escalation from seemingly innocuous online activities to large-scale criminal operations with real-world consequences. The ability of individuals to leverage vulnerabilities for massive disruption, coupled with their willingness to employ intimidation and violence, poses a significant threat to individuals and organizations alike.
The rapid growth of Kimwolf, coupled with Dort’s aggressive retaliation against those who expose their activities, underscores the need for continued vigilance and robust cybersecurity measures. The exploitation of residential proxy services, as detailed in the initial investigation, demonstrates the interconnectedness of the digital infrastructure and how seemingly minor weaknesses can be exploited for widespread impact.
The ongoing investigation into Dort’s activities and the Kimwolf botnet is critical for understanding the evolving tactics of cybercriminals. The confluence of botnet operations, DDoS attacks, doxing, and swatting incidents represents a multi-faceted assault on individuals and the integrity of online information. As law enforcement and cybersecurity professionals continue to track these threats, the ability to link online aliases to real-world identities, as demonstrated in this investigation, remains a crucial component in dismantling these sophisticated criminal enterprises. The legal ramifications for Dort, should their identity be definitively established and further evidence of their direct involvement in criminal activities be confirmed, are likely to be severe, potentially involving significant prison sentences and substantial fines. The world watches to see if Dort will be brought to justice for their role in orchestrating one of the most significant cyber threats of recent times.









{kind=link}