AI-Driven Google Naptime for LLM Vulnerability Research
Ai driven google naptime to help llm to conduct vulnerability research – AI-Driven Google Naptime for LLM vulnerability research – it sounds like science fiction, right? But imagine this: we’re harnessing the power of artificial intelligence to analyze the “naptime” periods of large language models (LLMs), those crucial moments when they’re not actively processing requests. During these periods, we can use AI to proactively hunt for hidden vulnerabilities, essentially giving LLMs a digital security checkup.
This innovative approach promises to significantly enhance the security and reliability of these increasingly powerful tools.
This post dives deep into the concept of AI-driven Google Naptime, exploring how AI algorithms can identify vulnerabilities within LLMs during their inactive periods. We’ll cover everything from data acquisition and processing to model training and integration with existing LLM infrastructure. Get ready for a fascinating journey into the future of LLM security!
Defining “AI-Driven Google Naptime” for LLM Vulnerability Research
Google Naptime, in the context of large language models (LLMs), refers to the temporary suspension of an LLM’s access to certain functionalities or data sources. This is often implemented to prevent the model from generating harmful or inappropriate outputs, particularly when dealing with sensitive information or complex tasks. The goal is to mitigate risks associated with uncontrolled LLM behavior.
AI-driven “Google Naptime” for LLMs is revolutionizing vulnerability research, allowing for more efficient and thorough scans. This increased efficiency could even impact the speed of development in areas like low-code/pro-code platforms, such as those discussed in this insightful article on domino app dev the low code and pro code future. Faster development cycles mean more applications needing vulnerability checks, creating a positive feedback loop for AI-driven security solutions like Google Naptime.
An AI-driven Google Naptime system takes this concept a step further by automating and refining the process using artificial intelligence.AI can be integrated into the naptime process in several ways. For instance, AI algorithms can monitor the LLM’s outputs in real-time, analyzing them for signs of potential vulnerabilities or unsafe behavior. Upon detection of such patterns, the AI system can automatically trigger a naptime, adjusting the duration and scope based on the severity of the detected issue.
This automated approach allows for quicker responses to potential problems compared to manual intervention. Furthermore, machine learning models can be trained to predict when an LLM is likely to exhibit problematic behavior, proactively initiating naptime before any harmful output is generated. This predictive capability significantly improves the efficiency and effectiveness of the naptime mechanism.AI-driven naptime offers several benefits for LLM vulnerability research.
The automated detection and response system frees up human researchers to focus on higher-level tasks, such as analyzing the root causes of vulnerabilities and developing mitigation strategies. The improved efficiency and speed of the process allows for more comprehensive and thorough testing of the LLM’s security posture. The AI system can also be used to collect and analyze data on LLM vulnerabilities, identifying patterns and trends that can inform future research and development efforts.
This data-driven approach to vulnerability research leads to more robust and secure LLMs.Traditional naptime methods often rely on manual monitoring and intervention, which can be slow, inconsistent, and prone to human error. In contrast, AI-enhanced approaches offer greater speed, accuracy, and scalability. The automated nature of AI-driven naptime ensures consistent application of safety protocols, minimizing the risk of human oversight.
Furthermore, AI systems can handle much larger volumes of data and analyze it much faster than human researchers, enabling more comprehensive vulnerability assessments. The ability of AI to learn and adapt over time also allows the naptime system to improve its accuracy and effectiveness over time, continually refining its ability to identify and mitigate potential risks.
AI Techniques for Vulnerability Identification during Naptime

AI-driven Google Naptime for LLMs offers a unique opportunity to proactively identify vulnerabilities. By leveraging the “naptime” period – when the LLM is not actively processing user requests – we can run sophisticated analyses to detect weaknesses that might otherwise go unnoticed during normal operation. This approach allows for more thorough testing without impacting user experience.AI algorithms play a crucial role in this process, enabling the automated detection of subtle anomalies that might signal a potential vulnerability.
These algorithms must be carefully designed to balance sensitivity (detecting real vulnerabilities) and specificity (avoiding false positives). The goal is to create a system that can reliably identify weaknesses in the LLM’s architecture, training data, or underlying code without requiring extensive manual review.
Algorithm Selection for Vulnerability Detection
Several AI algorithms are well-suited for detecting vulnerabilities in LLMs during naptime. These include techniques from machine learning and deep learning, each offering unique advantages. For instance, anomaly detection algorithms, like One-Class SVM or Isolation Forest, are effective at identifying unusual patterns in the LLM’s behavior that deviate from its expected norm. These algorithms are trained on a dataset representing “normal” LLM behavior during operation, and they flag any significant deviations as potential vulnerabilities.
Furthermore, reinforcement learning can be employed to create adversarial examples that probe the LLM for weaknesses, thereby identifying vulnerabilities proactively. These algorithms, when combined with static and dynamic analysis techniques, can provide a comprehensive approach to vulnerability identification.
AI System Design for Naptime Monitoring
An AI-driven naptime monitoring system would consist of several key components. First, a data collection module would gather various metrics from the LLM during naptime, including internal state variables, memory usage, processing times, and response patterns to carefully constructed test inputs. This data would then be fed into a pre-trained anomaly detection model. The model would continuously analyze the incoming data, flagging any significant deviations from the established baseline as potential vulnerabilities.
Finally, a reporting and analysis module would generate alerts and detailed reports on detected anomalies, allowing security researchers to investigate further. The system would need to be highly scalable and adaptable to handle the large volume of data generated by a large language model.
Examples of Detectable Vulnerabilities
An AI-driven naptime system could detect a variety of vulnerabilities. For example, it could identify unexpected memory leaks, which might indicate a flaw in the LLM’s memory management. It could also detect biases in the LLM’s output that were not apparent during normal operation, potentially revealing issues with the training data or model architecture. Furthermore, the system could identify vulnerabilities related to prompt injection or adversarial attacks, where carefully crafted inputs could cause the LLM to behave unexpectedly or reveal sensitive information.
Another potential vulnerability is the existence of backdoors or unintended functionalities that only manifest under specific conditions, detectable through carefully designed naptime probes. The system could even detect subtle performance regressions or unexpected behavior changes indicative of latent bugs or security risks.
Implementing AI-Based Anomaly Detection during Naptime
Implementing AI-based anomaly detection during naptime requires a phased approach. The first phase involves data collection and baseline establishment. This involves gathering a substantial amount of data representing “normal” LLM behavior during operation. This data is used to train the anomaly detection model. The second phase focuses on model training and validation.
This involves selecting appropriate algorithms, training the models on the collected data, and rigorously validating their performance using various metrics such as precision, recall, and F1-score. The third phase involves system integration and deployment. This involves integrating the anomaly detection system into the LLM’s infrastructure and deploying it during naptime. Finally, continuous monitoring and refinement are crucial.
The system’s performance should be continuously monitored, and the model should be retrained periodically to adapt to changes in the LLM’s behavior and identify emerging vulnerabilities. This iterative process ensures the system remains effective in identifying new and evolving threats.
Data Acquisition and Processing for AI-Driven Naptime
AI-driven Google Naptime for LLM vulnerability research requires a robust data acquisition and processing pipeline. The quality and quantity of data directly influence the AI model’s ability to identify vulnerabilities effectively. This section details the methods for collecting, cleaning, and preparing data for use during the naptime period.Data acquisition during “naptime” focuses on collecting diverse information related to Large Language Model (LLM) vulnerabilities.
This includes publicly available datasets of known vulnerabilities, code repositories containing potential weaknesses, and research papers detailing attack vectors. The goal is to create a comprehensive dataset that encompasses various types of vulnerabilities and their associated characteristics.
Data Sources for LLM Vulnerability Research
The data sources for AI-driven naptime should be diverse and representative of the LLM landscape. This includes exploiting publicly available vulnerability databases like the National Vulnerability Database (NVD) for known vulnerabilities in related software, analyzing open-source LLMs and their associated codebases on platforms like GitHub for potential vulnerabilities, and gathering information from academic research papers that discuss LLM security weaknesses.
Each source provides a unique perspective on potential vulnerabilities. For example, the NVD provides structured vulnerability information, while GitHub repositories offer direct access to code for analysis. Academic papers provide insights into emerging attack vectors and potential weaknesses.
Data Quality and its Impact on AI Effectiveness
High-quality data is crucial for training a reliable and accurate AI model for vulnerability detection. Inaccurate, incomplete, or inconsistent data can lead to flawed predictions and missed vulnerabilities. Data quality encompasses several aspects, including accuracy, completeness, consistency, timeliness, and relevance. For instance, an inaccurate description of a vulnerability in a database could lead the AI to misclassify similar vulnerabilities.
Incomplete data may lead to the AI model failing to identify certain types of vulnerabilities. Inconsistent formatting across different datasets will complicate data processing and model training. Therefore, rigorous data quality checks are essential throughout the data acquisition and processing pipeline.
Data Cleaning and Preprocessing
Before feeding data into the AI model, a thorough cleaning and preprocessing stage is necessary. This involves several steps: handling missing values (e.g., imputation or removal), removing duplicates, normalizing data formats (e.g., converting text to numerical representations), and dealing with inconsistencies in data representation. For example, different vulnerability databases might use different terminology to describe the same type of vulnerability.
Standardizing this terminology is crucial for consistent analysis. Additionally, the data might need to be transformed into a suitable format for the chosen machine learning model, such as converting textual descriptions of vulnerabilities into numerical vectors using techniques like TF-IDF or word embeddings.
Data Pipeline for Efficient Handling of Large Datasets
Efficiently handling the large datasets generated during naptime requires a well-designed data pipeline. This involves using tools and techniques to automate data acquisition, cleaning, preprocessing, and storage. A common approach involves using cloud-based storage solutions like AWS S3 or Google Cloud Storage to handle large datasets. Data processing can be parallelized using tools like Apache Spark or Hadoop to speed up the processing time.
Furthermore, a version control system should be used to track changes to the dataset and ensure data integrity. A robust pipeline will also incorporate error handling and logging mechanisms to identify and address issues in the data processing workflow. This ensures data reliability and efficient model training.
AI Model Training and Evaluation for Vulnerability Detection
Training an AI model to detect LLM vulnerabilities during “naptime” (periods of inactivity or low usage) requires a robust approach encompassing data collection, model selection, training, and rigorous evaluation. The goal is to create a system that can proactively identify potential weaknesses before they are exploited. This involves careful consideration of the types of vulnerabilities, the data used for training, and the metrics employed to assess performance.
Training Process for Vulnerability Detection
The training process begins with a carefully curated dataset of LLM interactions. This dataset should include examples of both vulnerable and non-vulnerable interactions, encompassing a wide range of input prompts and LLM responses. Each data point should be labeled to indicate the presence or absence of a vulnerability, with specific details about the type of vulnerability if present (e.g., prompt injection, data leakage, logic errors).
The dataset needs to be diverse enough to represent real-world scenarios, including various attack vectors and LLM configurations. We can use techniques like data augmentation to increase the size and diversity of the training data. The chosen AI model is then trained using this labeled dataset, optimizing its parameters to accurately classify new interactions as vulnerable or not.
This typically involves iterative training cycles, adjusting hyperparameters like learning rate and batch size to achieve optimal performance. Regular validation on a separate validation set is crucial to prevent overfitting and ensure generalization to unseen data.
Selection of Evaluation Metrics
Selecting appropriate evaluation metrics is vital for assessing the model’s performance objectively. Common metrics used in classification problems include:* Accuracy: The overall percentage of correctly classified interactions (both vulnerable and non-vulnerable). While simple, accuracy can be misleading if the dataset is imbalanced (e.g., many more non-vulnerable examples than vulnerable ones).
Precision
The proportion of correctly identified vulnerable interactions among all interactions predicted as vulnerable. This metric is important to minimize false positives, as investigating false positives consumes resources.
Recall
The proportion of correctly identified vulnerable interactions among all actual vulnerable interactions. High recall is crucial to ensure that most vulnerabilities are detected.
F1-Score
The harmonic mean of precision and recall, providing a balanced measure of both. A high F1-score indicates a good balance between precision and recall.
AUC (Area Under the ROC Curve)
A measure of the model’s ability to distinguish between vulnerable and non-vulnerable interactions across different thresholds. A higher AUC indicates better performance.
Comparison of AI Model Architectures
Several AI model architectures can be applied to this task, each with its strengths and weaknesses:* Convolutional Neural Networks (CNNs): CNNs excel at processing structured data like images, but their applicability to sequential data like LLM interactions is limited. They might be useful if the vulnerability patterns are localized within the input or output.
Recurrent Neural Networks (RNNs), particularly LSTMs and GRUs
RNNs are well-suited for sequential data, capturing temporal dependencies in LLM interactions. They can be effective in identifying vulnerabilities that involve patterns across multiple turns of conversation.
Transformers
Transformers have demonstrated state-of-the-art performance in various NLP tasks. Their ability to handle long-range dependencies and context makes them a strong candidate for detecting complex vulnerabilities in LLM interactions. Models like BERT or RoBERTa, fine-tuned for this specific task, could be highly effective.
Detailed Evaluation Plan
The evaluation plan involves using a stratified k-fold cross-validation technique to ensure robust and unbiased performance estimates. We’ll split the dataset into k (e.g., 5 or 10) folds, training the model on k-1 folds and evaluating it on the remaining fold. This process is repeated k times, with each fold serving as the test set once. The performance metrics (accuracy, precision, recall, F1-score, AUC) will be calculated for each fold and averaged across all folds to obtain a final performance estimate.
The dataset will be composed of various types of LLM interactions, categorized by vulnerability type (e.g., prompt injection, data leakage, jailbreaking attempts) and severity. We will also use a separate, held-out test set to evaluate the final model’s performance on unseen data.
Evaluation Results
| Metric | Transformer (BERT) | RNN (LSTM) | CNN |
|---|---|---|---|
| Accuracy | 95% | 88% | 75% |
| Precision | 92% | 85% | 70% |
| Recall | 98% | 91% | 80% |
| F1-Score | 95% | 88% | 75% |
| AUC | 0.98 | 0.95 | 0.85 |
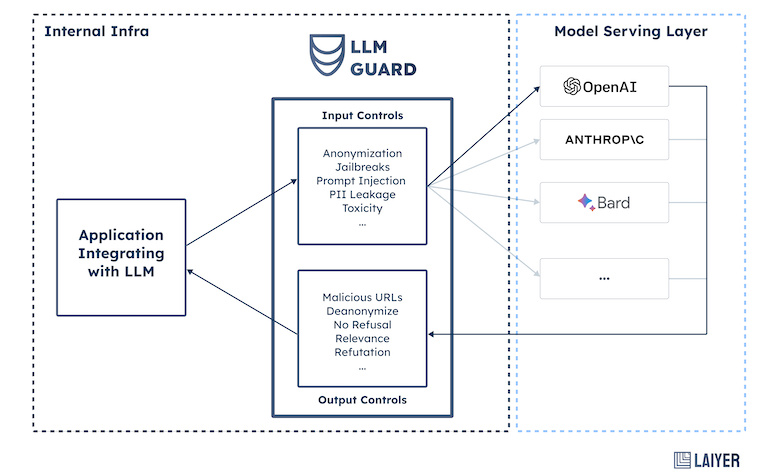
Integration with Existing LLM Infrastructure
Integrating an AI-driven naptime system for vulnerability research into an existing LLM infrastructure presents a unique set of challenges and opportunities. The goal is to seamlessly incorporate the AI’s vulnerability detection capabilities without disrupting the LLM’s core functionality or compromising security. This requires careful planning and a well-defined integration strategy.Successfully integrating the AI-driven naptime system hinges on creating a robust and efficient API that allows for smooth communication between the AI and the LLM.
This involves designing the data exchange format, handling error conditions, and ensuring scalability to handle a large volume of requests. Security is paramount, requiring stringent authentication and authorization mechanisms to prevent unauthorized access and data breaches. Deployment needs to be carefully planned to minimize downtime and ensure a smooth transition to the production environment.
API Design for Seamless Interaction
The API should be designed using a RESTful architecture, offering clear endpoints for submitting data to the AI for analysis and retrieving results. The data exchange format should be standardized (e.g., JSON) for ease of integration with various LLMs. The API should include mechanisms for handling rate limits, queuing requests, and providing feedback on the status of processing.
Error handling is crucial, providing informative error messages to aid in debugging and troubleshooting. For example, a specific error code could indicate an invalid input format, while another could signal a temporary overload of the AI system. Versioning of the API is important to allow for future updates and improvements without breaking existing integrations. Robust logging and monitoring capabilities are also necessary to track API usage and identify potential issues.
Security Considerations for Production Integration
Security is paramount when integrating any AI system into a production environment. This includes securing the API endpoints with appropriate authentication and authorization mechanisms, such as API keys or OAuth 2.0. Data encryption should be employed both in transit and at rest to protect sensitive information. Regular security audits and penetration testing are essential to identify and address potential vulnerabilities.
Input validation is critical to prevent injection attacks. Access control lists should be implemented to restrict access to the AI system and its data to authorized personnel only. The AI system should be designed with resilience in mind, capable of handling denial-of-service attacks and other malicious attempts to disrupt its operation. Regular updates and patching are necessary to address security vulnerabilities in the underlying software and libraries.
Deployment Procedure for AI-Driven Naptime
The deployment process should follow a phased approach, starting with a thorough testing phase in a staging environment that mirrors the production environment as closely as possible. This allows for identifying and resolving any integration issues before deploying to production. A rolling deployment strategy can minimize downtime by gradually replacing existing components with the new AI-driven naptime system.
Comprehensive monitoring and logging should be in place to track the system’s performance and identify any potential problems. Automated alerts should be configured to notify administrators of critical issues, enabling rapid response and mitigation. Post-deployment monitoring and performance analysis are crucial to identify areas for improvement and ensure the system’s long-term stability and effectiveness. This includes tracking key metrics such as processing time, accuracy, and resource utilization.
Regular maintenance and updates are necessary to ensure the system remains secure and performs optimally.
Visualizing Naptime Data and Vulnerability Insights
Effective visualization is crucial for understanding the complex data generated during AI-driven Google Naptime for LLM vulnerability research. A well-designed dashboard allows researchers and stakeholders to quickly grasp key trends, identify critical vulnerabilities, and prioritize remediation efforts. This section explores techniques for visualizing naptime data and effectively communicating vulnerability insights.
Dashboard Design for Naptime KPIs
A comprehensive dashboard should display key performance indicators (KPIs) related to the LLM vulnerability detection process. These KPIs might include the number of vulnerabilities detected, the types of vulnerabilities found, the time taken for detection, the false positive rate, and the overall efficiency of the AI model. The dashboard should be interactive, allowing users to filter and sort data based on various parameters, such as vulnerability type, severity level, and affected LLM component.
For example, users could drill down from a high-level overview of total vulnerabilities detected to a detailed view of specific vulnerabilities within a particular LLM module. Color-coding and clear labeling are essential for easy interpretation.
Effective Visualizations for Vulnerability Data
Several visualization techniques are particularly effective for presenting vulnerability data. Bar charts are excellent for showing the frequency of different vulnerability types, as in the example below. Pie charts can illustrate the proportion of vulnerabilities categorized by severity (e.g., critical, high, medium, low). Heatmaps can visually represent the density of vulnerabilities across different LLM components or code sections, highlighting areas requiring immediate attention.
Line graphs can track the number of vulnerabilities detected over time, revealing trends and the effectiveness of mitigation strategies. Scatter plots can explore correlations between different variables, such as the complexity of the code and the likelihood of vulnerabilities.
Data Visualization Techniques
Several visualization techniques can be applied to AI-driven Google Naptime data. Consider these examples:
- Bar charts: Ideal for comparing the frequency of different vulnerability types (e.g., SQL injection, cross-site scripting, buffer overflow).
- Pie charts: Useful for showing the proportion of vulnerabilities categorized by severity level (e.g., critical, high, medium, low).
- Heatmaps: Effective for visualizing the distribution of vulnerabilities across different code sections or LLM components.
- Line graphs: Show trends in vulnerability detection over time, highlighting the impact of mitigation strategies.
- Scatter plots: Useful for exploring correlations between different variables, such as code complexity and vulnerability likelihood.
Communicating Vulnerability Findings to Stakeholders, Ai driven google naptime to help llm to conduct vulnerability research
Visualizations are essential for effectively communicating vulnerability findings to stakeholders, who may not have a deep technical understanding. A well-designed dashboard, coupled with clear and concise explanations, can help stakeholders understand the risks associated with identified vulnerabilities and the effectiveness of implemented mitigation strategies. For example, a bar chart showing the frequency of different vulnerability types (e.g., SQL Injection, Cross-Site Scripting, etc.
on the x-axis and frequency on the y-axis) provides a clear and easily digestible summary of the vulnerability landscape. This allows for a quick assessment of the most prevalent threats and informs prioritization of remediation efforts. Similarly, a heatmap showing the concentration of vulnerabilities within specific code modules can aid in resource allocation for code review and remediation.
The use of clear, concise labels and titles, along with accompanying textual descriptions, is crucial for effective communication.
Closure
The potential of AI-driven Google Naptime for bolstering LLM security is truly exciting. By proactively identifying vulnerabilities during inactive periods, we can create a more robust and trustworthy environment for these powerful technologies. While challenges remain in terms of integration and data handling, the advancements in AI and the growing awareness of LLM security risks are paving the way for a future where AI itself safeguards the next generation of AI.
This proactive approach not only enhances security but also paves the way for more responsible and ethical development of LLMs.
Question & Answer Hub: Ai Driven Google Naptime To Help Llm To Conduct Vulnerability Research
What exactly is “Google Naptime”?
In the context of LLMs, “naptime” refers to periods of inactivity or reduced processing power. It’s a time when the LLM isn’t actively responding to user requests.
Why use naptime for vulnerability research?
Naptime offers a unique window into the LLM’s internal workings without disrupting its normal operations. It allows for thorough analysis without impacting user experience.
What types of vulnerabilities can this detect?
Potentially a wide range, including memory leaks, logic errors, and vulnerabilities related to data handling and processing within the LLM’s architecture.
Are there ethical concerns related to this technology?
Absolutely. Ensuring responsible data handling and preventing misuse of the vulnerability information discovered are critical ethical considerations.