
Alerts, Events, Incidents Where Should Your Security Team Focus?
Alerts events incidents where should your security team focus – Alerts, events, incidents: where should your security team focus? It’s a question every organization wrestles with, especially as the threat landscape evolves at breakneck speed. We’re constantly bombarded with alerts – some critical, some trivial. Sorting through the noise to pinpoint the genuine threats demands a strategic approach, a well-defined system for prioritization, and a team equipped to handle the pressure.
This post dives into the core elements of building that robust security posture.
Effective security isn’t just about reacting to incidents; it’s about proactively mitigating risks. We’ll explore how to build a tiered system for classifying alerts, develop a scoring mechanism for events, and create a clear escalation path for incidents. Crucially, we’ll discuss resource allocation, team training, and the vital role of threat intelligence in preventing future attacks. By the end, you’ll have a clearer picture of how to focus your security team’s efforts where they matter most.
Prioritization of Alerts, Events, and Incidents
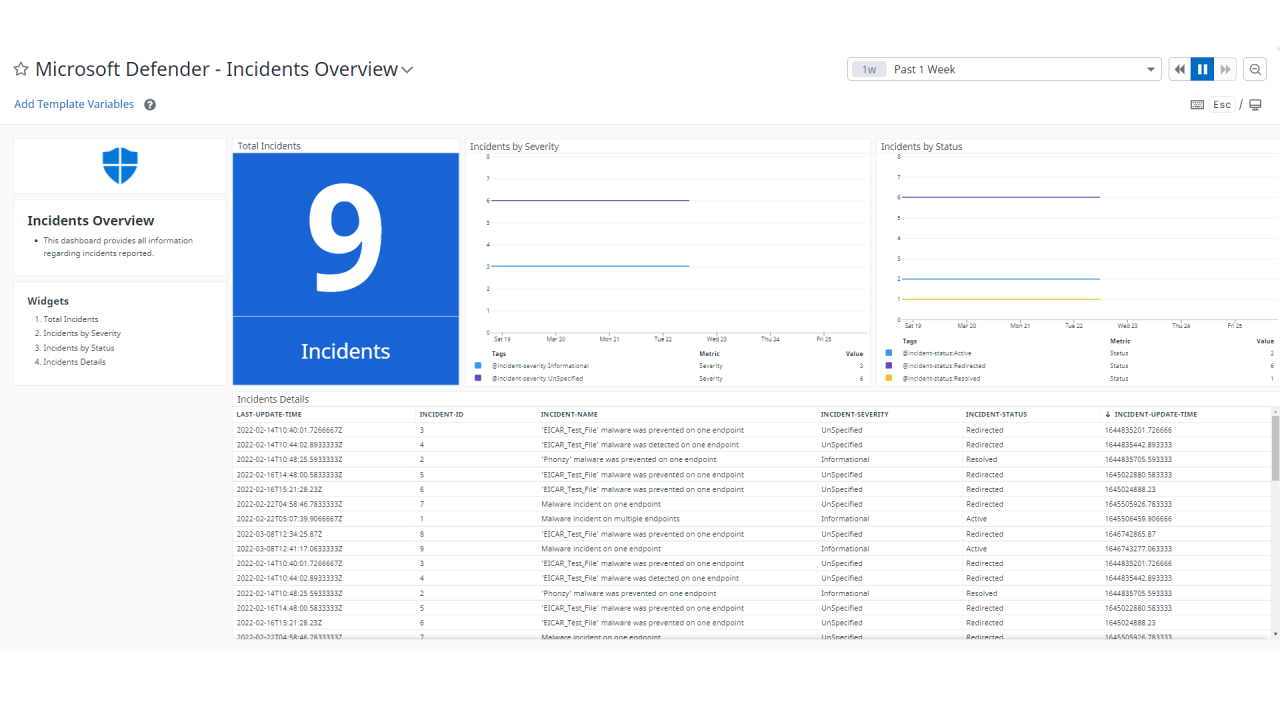
So, the security team’s been busy, and we’ve successfully addressed a number of alerts and incidents. But how do we ensure we’re focusing our efforts where they matter most? Effective prioritization is key to a proactive and efficient security posture. This means developing a robust system for classifying and responding to security events, ensuring that critical issues receive immediate attention while less urgent matters are handled appropriately.
A well-defined prioritization system allows your security team to manage the inevitable deluge of alerts, focusing resources on the threats that pose the greatest risk to your organization. It’s not just about reacting to problems; it’s about proactively mitigating risks and improving overall security posture. Ignoring this aspect can lead to burnout, delayed responses to critical issues, and ultimately, increased vulnerabilities.
A Tiered System for Alert Classification
A tiered system for classifying alerts is essential for effective prioritization. This system should categorize alerts based on their severity and potential impact. For example, a three-tier system might include:
- Critical: Alerts indicating immediate threats with significant impact, such as ransomware attacks, data breaches, or system compromises. These require immediate action and escalation.
- High: Alerts suggesting potential threats that could lead to significant impact if not addressed promptly. Examples include suspicious login attempts from unusual locations or detection of known malware variants.
- Low: Alerts that represent minor issues or potential threats with minimal impact. These can be addressed according to a less urgent schedule, perhaps during routine maintenance or scheduled investigation periods.
A Scoring Mechanism for Event Ranking
To further refine prioritization, a scoring mechanism can be implemented to rank events based on likelihood and consequence. This involves assigning numerical scores to both the likelihood of an event occurring and the potential impact if it does. The total score provides a ranked order of events, guiding the team’s focus. For example:
Consider a scenario with two events: Event A (Likelihood: High, Consequence: Low) and Event B (Likelihood: Low, Consequence: High). A simple scoring system might assign scores as follows: Likelihood (High=3, Medium=2, Low=1) and Consequence (High=3, Medium=2, Low=1). Event A would score 4 (3+1), and Event B would score 4 (1+3). Further analysis, perhaps considering the specific context and available mitigations, might be needed to prioritize between equally scored events.
Incident Escalation Workflow
A clear escalation path is crucial for handling incidents effectively. This workflow diagram should define the steps involved in escalating incidents based on their severity. For instance, a critical incident might follow a path involving immediate notification of senior management, engagement of specialized incident response teams, and potentially external communication to affected parties. Lower-severity incidents might follow a more streamlined process, with internal teams handling resolution.
A visual representation (a flowchart) would be extremely useful here. Imagine a flowchart beginning with ‘Alert Received’, branching to ‘Critical’, ‘High’, and ‘Low’ based on initial assessment. Each branch then shows a separate path with actions such as ‘Immediate Response Team Notification’, ‘Scheduled Investigation’, or ‘Standard Procedure Implementation’. The flowchart should also indicate the involvement of different teams or individuals at each stage, and the expected timeframe for resolution at each level.
Examples of High-Priority Alerts
High-priority alerts warranting immediate attention include:
- Ransomware detection: Immediate action is required to contain the attack and prevent further spread.
- Data breach indicators: Swift response is crucial to minimize data loss and comply with regulations.
- Successful privilege escalation attempts: These need immediate remediation to prevent further unauthorized access.
- Significant Denial-of-Service (DoS) attacks: Mitigation strategies are required to restore service availability.
Comparison of Incident Response Methodologies, Alerts events incidents where should your security team focus
Different organizations employ various incident response methodologies. Some common approaches include NIST’s Cybersecurity Framework, ISO 27001, and various vendor-specific frameworks. Each methodology Artikels a structured approach to incident response, but they may differ in their specific processes and phases. For instance, while all methodologies emphasize containment, eradication, and recovery, the specifics of how these phases are executed may vary.
Prioritizing alerts and incidents is crucial for any security team. Focusing on high-impact events is key, especially those related to application vulnerabilities. This is especially relevant when considering the rapid development cycles enabled by tools like those discussed in this article on domino app dev the low code and pro code future , where security needs to be baked in from the start.
Understanding the potential attack surface of these new applications is critical for effective incident response and proactive threat management.
The choice of methodology often depends on an organization’s size, industry, and specific security needs. A thorough understanding of these differences is critical for selecting the most suitable approach.
Resource Allocation for Security Team Focus
Effective resource allocation is crucial for a security team’s ability to respond efficiently and effectively to the ever-increasing volume and complexity of security alerts, events, and incidents. Ignoring this aspect can lead to burnout, delayed responses, and ultimately, increased security risks. This section details how to optimize resource allocation to ensure your security team is properly equipped and staffed to handle any situation.
Optimal Staffing Levels for Alert Volumes
The ideal staffing level directly correlates with the volume and severity of alerts a security team manages. A small organization with a low volume of relatively low-risk alerts might only require a small team, perhaps even a single security analyst handling basic monitoring and response. In contrast, large enterprises with complex systems and high alert volumes will necessitate a larger team, potentially with specialized roles like threat hunters, incident responders, and security engineers.
Consider implementing a tiered approach: a smaller team for routine monitoring and a larger, rapidly deployable team for critical incidents. A good starting point is to benchmark against similar organizations in your industry or use industry-standard staffing ratios based on the number of systems and users under protection. For example, a rule of thumb might be one security analyst for every 500-1000 endpoints, but this should be adjusted based on the complexity of your environment and threat landscape.
Regular review and adjustment of staffing levels are necessary to maintain optimal performance.
Required Skill Sets for Incident Response
A well-rounded security team requires a diverse skill set to address the various types of incidents. This includes expertise in areas such as network security, endpoint security, cloud security, application security, and security information and event management (SIEM). Specific roles might include:
- Security Analysts: Responsible for monitoring alerts, investigating security events, and performing incident response activities.
- Threat Hunters: Proactively search for threats within the network and systems, often utilizing advanced techniques and tools.
- Incident Responders: Lead the response to critical security incidents, coordinating with other teams and stakeholders.
- Security Engineers: Design, implement, and maintain security controls and infrastructure.
- Forensic Analysts: Investigate security breaches to determine the root cause, impact, and remediation steps.
The specific skill set needed will depend on the organization’s size, complexity, and risk profile. Smaller organizations might have generalist security analysts, while larger organizations might have specialized teams for each area.
Security Threat Training Plan
A comprehensive training plan is essential to ensure the security team remains up-to-date with the latest threats and technologies. This should include both technical and non-technical training, such as:
- Technical Training: Focus on specific technologies used in the organization’s security infrastructure (e.g., SIEM tools, endpoint detection and response (EDR) solutions, cloud security platforms). This could involve vendor-specific training, online courses, or workshops.
- Threat Intelligence Training: Educate the team on the latest threat actors, attack techniques, and vulnerabilities. This could involve subscribing to threat intelligence feeds, attending security conferences, or participating in threat hunting exercises.
- Incident Response Training: Conduct regular tabletop exercises and simulations to prepare the team for real-world incident response scenarios. This should include training on incident handling procedures, communication protocols, and forensic analysis techniques.
- Compliance and Regulatory Training: Ensure the team is aware of relevant security regulations and compliance standards (e.g., GDPR, HIPAA, PCI DSS).
Budget Proposal for Security Incident Response
A detailed budget proposal should justify the resource allocation for security incident response. This should include costs associated with:
- Staffing: Salaries and benefits for security personnel.
- Technology: Costs of security tools, software, and hardware (e.g., SIEM, EDR, SOAR).
- Training: Costs of training courses, workshops, and certifications.
- Incident Response Services: Costs of engaging external incident response providers if needed.
- Consulting: Costs of engaging external security consultants for specialized expertise.
The budget should be presented with clear justification for each expense, demonstrating the return on investment (ROI) in terms of reduced risk and improved security posture. For example, justify the cost of a new SIEM system by showing how it will improve threat detection, reduce incident response time, and minimize the financial impact of a potential breach.
Utilizing Automation Tools
Automation is crucial for reducing the manual workload on the security team and improving efficiency. Security orchestration, automation, and response (SOAR) tools can automate repetitive tasks such as alert triage, incident investigation, and remediation. This frees up security analysts to focus on more complex and strategic tasks. Examples include automating the analysis of security alerts, automatically blocking malicious IP addresses, and initiating automated incident response playbooks.
The selection of automation tools should align with the organization’s specific needs and budget. Investing in automation not only improves efficiency but also helps to reduce human error and improve consistency in incident response.
Threat Intelligence and Proactive Measures: Alerts Events Incidents Where Should Your Security Team Focus

Proactive security is no longer a luxury; it’s a necessity in today’s threat landscape. Reacting to incidents is costly and inefficient. A robust threat intelligence program, coupled with proactive measures, is the key to significantly reducing your organization’s attack surface and minimizing the impact of successful breaches. This involves understanding where threats originate, anticipating attacks, and implementing preventative measures before they can cause damage.Common Sources of Security Alerts and EventsOrganizations face a diverse range of threats.
Identifying common sources within your own infrastructure is the first step towards effective mitigation. This involves analyzing your existing security logs and correlating alerts from various security tools. Understanding the patterns and trends within these alerts allows for a more focused and effective security posture.
Common Alert Sources
Typical sources of security alerts and events often include failed login attempts, suspicious network activity (e.g., unusual traffic patterns or connections to malicious IPs), malware detections, vulnerability scans revealing exploitable weaknesses, and unauthorized access attempts to sensitive data. Analyzing these alerts reveals common attack vectors and allows for the prioritization of security controls. For example, a high volume of failed login attempts from a specific geographic location might indicate a brute-force attack, requiring immediate action such as account lockout policies and multi-factor authentication implementation.
Proactive Measures to Prevent Future Incidents
Proactive measures are crucial for preventing future incidents. These measures go beyond simply reacting to alerts; they focus on preventing threats from ever reaching your systems. A multi-layered approach is essential.
Examples of Proactive Measures
Implementing strong password policies, including password complexity requirements and regular password changes, is fundamental. Regular security awareness training for employees educates them about phishing scams, social engineering tactics, and safe browsing practices. Regular vulnerability scanning and penetration testing identify and address weaknesses in your systems before attackers can exploit them. Employing intrusion detection and prevention systems (IDPS) provides real-time monitoring and automated responses to suspicious network activity.
Regular patching and updating of software and operating systems is critical to address known vulnerabilities. Finally, employing robust data loss prevention (DLP) solutions helps prevent sensitive data from leaving the organization’s control.
The Importance of Threat Intelligence Feeds
Threat intelligence feeds provide valuable insights into emerging threats and vulnerabilities. These feeds, often obtained from commercial vendors or open-source intelligence (OSINT) communities, offer information on malware campaigns, attack techniques, and known malicious actors. By leveraging these feeds, organizations can proactively identify and mitigate potential risks before they materialize. For instance, if a threat intelligence feed reveals a new zero-day exploit targeting a specific software version, organizations can prioritize patching that software to prevent exploitation.
This proactive approach is far more effective and cost-efficient than reacting to an incident after exploitation has occurred.
Integrating Threat Intelligence into Incident Response
Threat intelligence shouldn’t be siloed; it needs to be integrated into the entire security lifecycle, especially incident response. When an incident occurs, threat intelligence can provide crucial context, such as the attacker’s tactics, techniques, and procedures (TTPs), enabling a faster and more effective response. For example, if an incident involves ransomware, threat intelligence can help identify the specific ransomware variant, its known encryption methods, and potential decryption techniques.
This information is critical for containing the incident and minimizing its impact.
Monitoring and Analyzing Security Logs
Security logs are a treasure trove of information. A robust system for monitoring and analyzing these logs is essential for identifying emerging threats. This system should include tools for log aggregation, correlation, and analysis. Sophisticated Security Information and Event Management (SIEM) systems are commonly used for this purpose. These systems can identify patterns and anomalies in log data that might indicate malicious activity, allowing security teams to proactively address potential threats.
For example, a sudden spike in failed login attempts from a specific IP address, combined with unusual network traffic originating from the same IP, could indicate a potential intrusion attempt. This system allows for the identification of these patterns and alerts the security team to investigate.
Incident Response and Remediation Strategies
Effective incident response is crucial for minimizing damage and ensuring business continuity. A well-defined plan, clear roles, and a robust remediation process are essential components of a strong security posture. This section details a structured approach to incident response and remediation, emphasizing proactive measures and post-incident analysis for continuous improvement.
Incident Response Plan
A step-by-step incident response plan provides a structured approach to handling security incidents. This plan should be regularly tested and updated to reflect evolving threats and organizational changes. Each phase requires clear communication, collaboration, and a focus on containment and eradication. The following Artikels a typical incident response lifecycle:
- Preparation: This phase involves establishing the incident response team, defining roles and responsibilities, developing procedures, and conducting regular training exercises.
- Identification: This is the detection of a security incident, often through monitoring systems or user reports. Early identification is crucial for minimizing impact.
- Containment: This involves isolating the affected systems or networks to prevent further damage or spread of the threat. This might include disconnecting infected machines from the network or implementing network segmentation.
- Eradication: This phase focuses on removing the threat completely. This might involve removing malware, patching vulnerabilities, or restoring systems from backups.
- Recovery: This involves restoring systems and data to a functional state, validating the integrity of systems and data, and restoring services.
- Post-Incident Activity: This includes conducting a post-incident review to identify weaknesses and improve future responses, updating the incident response plan, and implementing necessary security controls.
Roles and Responsibilities During Incident Response
Clear roles and responsibilities are vital for efficient incident response. The following table Artikels key roles and their responsibilities:
| Role | Responsibility | Contact | Escalation Path |
|---|---|---|---|
| Incident Commander | Overall management of the incident response | [Contact Information] | [Escalation Path – e.g., CIO, CSO] |
| Security Analyst | Investigation, analysis, and containment of the incident | [Contact Information] | [Escalation Path – e.g., Incident Commander, Security Manager] |
| System Administrator | Restoration of systems and data | [Contact Information] | [Escalation Path – e.g., Incident Commander, IT Manager] |
| Public Relations | Communication with stakeholders and the public | [Contact Information] | [Escalation Path – e.g., CEO, Legal Counsel] |
Successful Incident Remediation Strategies
Successful remediation involves a combination of technical and procedural measures. For example, a ransomware attack might be remediated by restoring systems from clean backups, removing the malware, and patching vulnerabilities. A data breach might involve notifying affected individuals, implementing stronger access controls, and enhancing monitoring capabilities. The key is a swift, decisive response that minimizes impact and prevents recurrence.
Post-Incident Review Process
Post-incident reviews are critical for continuous improvement. These reviews should involve a thorough analysis of the incident, including root cause analysis, identification of weaknesses, and recommendations for improvement. Documentation of the entire process, including timelines and decisions made, is crucial for effective analysis. This information is then used to update the incident response plan, security policies, and training programs.
Malware Containment and Eradication
Containing and eradicating malware requires a multi-faceted approach. Initial steps often involve isolating the infected system from the network to prevent further spread. Next, a thorough scan is performed using updated anti-malware software. If the malware persists, more aggressive techniques may be necessary, such as reinstalling the operating system from a known clean image or using specialized malware removal tools.
Regular system backups and a robust patching strategy are essential for minimizing the impact of malware infections.
Communication and Collaboration during Incidents
Effective communication and collaboration are the cornerstones of a successful incident response. A well-defined communication plan ensures everyone stays informed, minimizing confusion and maximizing efficiency during a crisis. This is especially critical when dealing with security breaches, where swift action and coordinated efforts are paramount to mitigating damage and restoring normalcy.A breakdown in communication can lead to delays in containment, escalation, and remediation, potentially exacerbating the impact of a security incident.
Clear communication channels, pre-defined roles, and established procedures are crucial for a smooth and effective response.
Communication Plan for Stakeholders
A comprehensive communication plan should Artikel how information will be disseminated to various stakeholders during a security incident. This includes internal teams (security, IT, legal, PR), external partners (vendors, customers), and potentially regulatory bodies. The plan should specify communication channels (email, phone, SMS, dedicated communication platform), frequency of updates, and the designated communication points of contact for each stakeholder group.
For instance, a regular cadence of updates might be established, perhaps hourly during the initial phases of a major incident, tapering off as the situation stabilizes.
Templates for Internal and External Communications
Pre-prepared communication templates can save valuable time during a crisis. Internal templates can focus on providing technical details and action items to different teams, while external templates should be crafted to reassure customers and partners while minimizing the disclosure of sensitive information. Internal templates might include detailed technical information, whereas external communications would need to balance transparency with the need to avoid panic or exploitation.
These templates should be regularly reviewed and updated to reflect the evolving threat landscape and organizational policies. Examples might include email templates for initial incident notifications, updates on progress, and resolution announcements.
Communicating Technical Details to Non-Technical Audiences
Explaining complex technical details to non-technical stakeholders requires clear, concise language and the avoidance of jargon. Using analogies and metaphors can make abstract concepts more accessible. For example, instead of saying “a denial-of-service attack flooded our servers,” one might say “imagine a firehose constantly spraying water at a doorway – that’s what the attack did to our systems.” Visual aids, such as diagrams or charts, can also significantly improve comprehension.
Furthermore, tailoring the level of detail to the audience’s understanding is essential.
Key Personnel and Contact Information
Maintaining an up-to-date list of key personnel and their contact information is vital for efficient incident response. This list should include names, roles, phone numbers, email addresses, and on-call schedules. The list should be easily accessible to all members of the incident response team and regularly reviewed and updated to reflect changes in personnel or contact information. This contact list might be stored securely in a shared document or a dedicated incident management system.
Collaboration Among Different Teams
Effective collaboration requires clearly defined roles and responsibilities for each team involved in incident response. Regular training and exercises can enhance team coordination and communication. Establishing a central communication hub, such as a dedicated chat channel or collaboration platform, can facilitate real-time information sharing and collaboration. Furthermore, clear escalation paths and decision-making processes should be defined to ensure timely and effective responses.
For example, a matrix outlining responsibilities for different incident types and escalation procedures would ensure that every team member knows their role and who to contact in case of issues.
Final Summary
Ultimately, a successful security strategy hinges on a blend of proactive measures and reactive response. By implementing a robust system for prioritizing alerts, events, and incidents, allocating resources effectively, and fostering strong team collaboration, organizations can significantly reduce their vulnerability to cyber threats. Remember, it’s not just about
-what* your team focuses on, but
-how* they approach the challenge.
A proactive, well-trained, and strategically-focused security team is your strongest defense against the ever-evolving world of cyber threats. Stay vigilant, stay informed, and stay secure!
FAQ Compilation
What’s the difference between an alert, an event, and an incident?
An alert is a notification of a potential security issue. An event is a recorded occurrence, which may or may not be significant. An incident is a confirmed security breach or violation requiring response.
How often should my security team conduct training?
Regular training, ideally quarterly or bi-annually, is crucial to keep your team up-to-date on emerging threats and best practices. The frequency depends on your organization’s risk profile and the complexity of your systems.
What are some common automation tools for security incident response?
Popular tools include SIEM (Security Information and Event Management) systems, SOAR (Security Orchestration, Automation, and Response) platforms, and various threat intelligence platforms.
How do I measure the effectiveness of my security team’s response?
Key metrics include Mean Time To Detect (MTTD), Mean Time To Respond (MTTR), and the reduction in successful attacks. Post-incident reviews are essential for continuous improvement.




