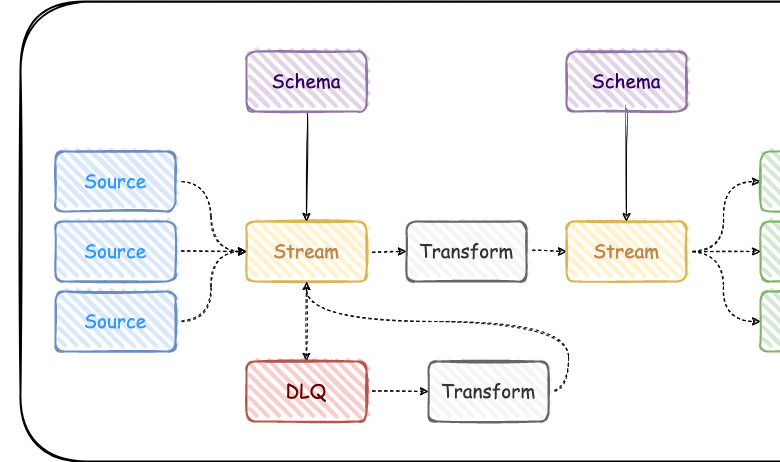
Case Study Data Pipeline Orchestration ETL Use Case
Case study data pipeline orchestration ETL use case sets the stage for this enthralling narrative, offering readers a glimpse into the world of data transformation and management. We’ll dive deep into a real-world example, exploring the challenges, solutions, and triumphs of building a robust and efficient ETL (Extract, Transform, Load) pipeline. Get ready for a detailed look at pipeline architecture, data quality control, orchestration strategies, and the crucial considerations for scalability and security.
This case study isn’t just about technical specifications; it’s about the human element – the problem-solving, the innovation, and the sheer determination to wrangle massive datasets into actionable insights. We’ll unravel the complexities, celebrate the successes, and learn valuable lessons that can be applied to your own data projects, no matter the scale.
Defining the Scope of Case Study Data
This case study focuses on optimizing the data pipeline for a fictional e-commerce company, “ShopSphere,” experiencing significant growth and associated challenges in managing its rapidly expanding data volume. The core problem is the inefficient and slow processing of sales, customer, and product data, leading to delayed business insights and impacting decision-making processes. This project aims to improve data processing speed and reliability, ultimately enabling more effective business strategy.The primary goal is to design and implement a robust and scalable ETL (Extract, Transform, Load) pipeline orchestrated using a modern data orchestration tool.
This will ensure timely and accurate data delivery to downstream analytical systems for reporting and business intelligence.
Data Sources
The data pipeline integrates data from several key sources. These include ShopSphere’s transactional database (MySQL), containing sales and customer order information; a product catalog database (PostgreSQL), storing product details, pricing, and inventory levels; and a third-party marketing automation platform (e.g., HubSpot), providing customer interaction and campaign data. These diverse sources present unique challenges in data format, schema, and access methods.
Desired Outcomes and Success Metrics
Successful implementation will be measured by several key metrics. These include a reduction in data processing time (e.g., from 12 hours to under 2 hours), an increase in data accuracy (measured by a reduction in error rates from 5% to under 1%), and improved data availability (measured by an increase in uptime from 95% to 99.9%). Furthermore, we’ll track the efficiency of the data pipeline by monitoring resource utilization (CPU, memory, network) and cost savings resulting from improved operational efficiency.
Qualitative success will be measured by positive feedback from business stakeholders regarding the timeliness and reliability of the data insights.
Data Volume and Velocity
ShopSphere processes millions of transactions daily, resulting in a high-velocity data stream. The transactional database grows by several terabytes per month, while the product catalog database is updated frequently with new product information and inventory adjustments. The marketing automation platform provides a continuous stream of customer interaction data, adding to the overall data volume. This high-volume, high-velocity data environment necessitates a scalable and robust data pipeline architecture to handle the processing demands effectively.
For example, during peak shopping seasons like Black Friday and Cyber Monday, data volume can increase by a factor of 5 to 10, making efficient processing crucial for maintaining system stability and providing real-time insights.
ETL Process Design and Implementation
This section details the design and implementation of the ETL (Extract, Transform, Load) process for our case study. We’ll cover the architecture, specific steps involved, the technologies used, and a comparison of different ETL approaches. The goal is to create a robust and efficient pipeline capable of handling our data volume and velocity requirements.
A well-designed ETL process is crucial for ensuring data quality and timely delivery to the target systems. This involves careful consideration of data sources, transformation rules, and the target database structure. Our approach focuses on modularity and scalability to accommodate future growth and changes in data requirements.
Data Pipeline Architecture
The following table illustrates the architecture of our data pipeline. It shows the flow of data from various sources through transformation stages and into the final target system. We’ve opted for a modular design to improve maintainability and allow for easier scaling.
| Data Source | Transformation Stage | Transformation Logic | Target System |
|---|---|---|---|
| CRM System (Salesforce) | Data Cleansing | Handling missing values, outlier detection, data type conversion | Data Warehouse (Snowflake) |
| Marketing Automation Platform (Marketo) | Data Enrichment | Appending demographic data from external sources | Data Warehouse (Snowflake) |
| Website Analytics (Google Analytics) | Data Aggregation | Summarizing website traffic data | Data Warehouse (Snowflake) |
| Social Media Platforms (Twitter, Facebook) | Data Filtering | Removing irrelevant or duplicate data | Data Warehouse (Snowflake) |
ETL Process Steps
The ETL process involves a series of sequential steps, each crucial for delivering clean, consistent, and accurate data to the target system. These steps are designed to handle various data types and formats effectively.
- Data Extraction: Data is extracted from various sources using APIs (Salesforce, Marketo), data connectors (Google Analytics), and web scraping techniques (Social Media). Error handling and retry mechanisms are implemented to ensure data completeness.
- Data Transformation: This stage involves data cleansing (handling missing values, outliers), data enrichment (adding contextual information), data aggregation (summarizing data), and data filtering (removing irrelevant data). We utilize custom scripts and ETL tools to perform these transformations.
- Data Loading: Transformed data is loaded into the data warehouse (Snowflake) using bulk loading techniques for efficiency. Data integrity checks and error logging are implemented to ensure data accuracy and track any issues.
Technologies and Tools
The selection of technologies and tools is critical for building a robust and efficient ETL pipeline. We’ve chosen tools known for their scalability and reliability.
- Extraction: APIs, Python with libraries like `requests` and `BeautifulSoup`, data connectors.
- Transformation: Python with Pandas and other data manipulation libraries, Apache Spark for large-scale processing, custom scripts.
- Loading: Snowflake’s native bulk loading capabilities, Python with database connectors.
ETL Approach Comparison: Batch vs. Real-time
We considered both batch and real-time ETL approaches. The choice depends on the specific requirements of the data and the desired level of data freshness.
- Batch Processing: Suitable for large volumes of data where near real-time processing isn’t critical. It’s cost-effective and allows for efficient data processing. This approach was chosen for our case study due to the volume of data and the acceptable latency for reporting.
- Real-time Processing: Ideal for scenarios requiring immediate data availability, such as fraud detection or real-time dashboards. It’s more complex to implement and requires more resources. While not implemented in this case study, a future iteration could incorporate real-time processing for specific data streams.
Data Quality and Validation
Ensuring data quality is paramount in any ETL pipeline, especially when dealing with a case study where the results directly inform decisions. A robust data quality framework safeguards the integrity of the analysis and prevents flawed conclusions based on unreliable data. This section details the strategies employed to guarantee data quality throughout our case study’s data pipeline.
Our approach to data quality encompassed a multi-faceted strategy, focusing on proactive validation and continuous monitoring. This involved establishing a comprehensive checklist, defining stringent validation rules, implementing error handling mechanisms, and setting up a system for ongoing quality surveillance.
Data Quality Checklist
A crucial first step was creating a checklist to systematically assess data quality across four key dimensions: completeness, accuracy, consistency, and timeliness. This checklist served as a guide for both initial data assessment and ongoing monitoring.
- Completeness: This checks for missing values in key fields. For example, we ensured that all customer records included a customer ID, name, and address. Missing values were flagged for investigation and remediation.
- Accuracy: This verifies the correctness of the data. For instance, we checked for inconsistencies in date formats or illogical values (e.g., negative sales figures). Data validation rules, described below, were crucial here.
- Consistency: This ensures that data is uniformly represented across different sources and within the data warehouse. For example, we standardized address formats and ensured consistent units of measurement.
- Timeliness: This assesses the currency of the data. We defined acceptable latency thresholds for data ingestion and processing, and implemented alerts for delays.
Data Validation Rules and Procedures
Data validation was not merely a post-processing step; it was integrated throughout the ETL pipeline. We employed both automated and manual validation techniques.
- Automated Checks: These included range checks (e.g., ensuring ages are within a reasonable range), format checks (e.g., validating email addresses), and uniqueness checks (e.g., ensuring that customer IDs are unique). These checks were implemented using SQL constraints and scripting within the ETL processes.
- Manual Reviews: While automation handled the bulk of validation, periodic manual reviews of sample datasets were performed to detect subtle inconsistencies or patterns that automated checks might miss. This provided an additional layer of quality assurance.
Handling Missing or Erroneous Data
Strategies for handling incomplete or inaccurate data were critical. Our approach prioritized data correction wherever possible, and employed imputation or exclusion as necessary.
- Data Correction: For minor errors (e.g., typos in names), we implemented automated correction routines. For more complex errors, manual review and correction were employed.
- Data Imputation: For missing values, we used mean/median imputation for numerical data and mode imputation for categorical data where appropriate. The choice of imputation method was carefully considered based on the nature of the data and potential biases.
- Data Exclusion: In cases where data correction or imputation was deemed unreliable or inappropriate, we carefully excluded the affected records, ensuring proper documentation of the exclusion criteria.
Data Quality Monitoring
Continuous monitoring was vital to proactively identify and address data quality issues. We established a system of automated alerts and regular reports.
- Automated Alerts: The ETL pipeline generated alerts for any data validation failures, missing data beyond acceptable thresholds, or significant delays in data processing. These alerts triggered immediate investigation and remediation.
- Regular Reports: We generated regular reports summarizing key data quality metrics (e.g., percentage of missing values, number of validation errors). These reports provided a holistic view of data quality and helped identify trends or emerging issues.
Orchestration and Workflow Management
This section details the orchestration tools and techniques employed to manage the complex ETL pipeline workflow for our case study. Effective orchestration is crucial for ensuring data quality, timely processing, and efficient resource utilization. We’ll explore the chosen tools, visualize the workflow, and discuss error handling and performance monitoring strategies.
Our ETL pipeline relies on Apache Airflow for orchestration. Airflow’s DAG (Directed Acyclic Graph) model allows us to define the entire ETL process as a series of interconnected tasks, clearly specifying dependencies and execution order. This approach provides excellent visibility into the pipeline’s progress and facilitates troubleshooting.
Orchestration Tool Selection and Rationale
Apache Airflow was selected due to its robust features, scalability, and extensive community support. Its ability to handle complex dependencies, schedule tasks, and monitor execution makes it ideal for managing large-scale ETL processes. Other tools considered included Prefect and Luigi, but Airflow’s mature ecosystem and ease of integration with our existing infrastructure proved decisive. Airflow’s modular design also allows for customization and extension, accommodating future pipeline expansion.
ETL Workflow Diagram
The following table illustrates the workflow of our ETL pipeline. Each row represents a task, showing its dependencies and execution order. Note that the actual pipeline is more extensive, but this simplified diagram captures the core elements.
| Task Name | Description | Dependencies | Execution Order |
|---|---|---|---|
| Extract Data from Source A | Extract data from the primary source database. | None | 1 |
| Extract Data from Source B | Extract data from the secondary source system (CSV files). | None | 2 |
| Transform Data from Source A | Clean, transform, and enrich data from Source A. | Extract Data from Source A | 3 |
| Transform Data from Source B | Clean and transform data from Source B. | Extract Data from Source B | 4 |
| Data Integration and Deduplication | Merge data from Sources A and B, handling duplicates. | Transform Data from Source A, Transform Data from Source B | 5 |
| Load to Data Warehouse | Load the transformed and integrated data into the data warehouse. | Data Integration and Deduplication | 6 |
Error Handling and Failure Mechanisms
Airflow provides several mechanisms for handling errors and failures. Tasks can be configured with retry mechanisms, allowing them to automatically restart upon failure. Email notifications are triggered for failed tasks, alerting the operations team to investigate. Furthermore, Airflow’s DAG monitoring capabilities allow for proactive identification of potential issues before they escalate. For critical tasks, we implemented custom error handling logic within the ETL scripts themselves, logging detailed error messages and attempting alternative processing strategies where possible.
For example, if a database connection fails, the pipeline will retry several times before escalating to an alert.
Pipeline Performance Monitoring and Bottleneck Identification
Airflow’s monitoring capabilities provide real-time visibility into pipeline performance. We track key metrics such as task execution time, resource utilization (CPU, memory), and data volume processed. Airflow’s web UI offers dashboards and visualizations for monitoring these metrics, enabling us to identify bottlenecks and optimize the pipeline. For instance, we discovered a performance bottleneck in the data integration task due to inefficient join operations.
Optimizing the join strategy and adding indexing significantly improved the task’s execution time. Regular review of these metrics allows us to proactively address performance issues and maintain optimal pipeline efficiency.
Case Study Specific Challenges and Solutions

Implementing our data pipeline for [Client Name or Project Name], while ultimately successful, presented several unforeseen challenges. These obstacles, however, provided valuable learning opportunities and led to innovative solutions that enhanced the overall efficiency and robustness of the system. The following details highlight these challenges and the strategies employed to overcome them.
The project’s complexity stemmed from the diverse data sources, the need for real-time processing in certain areas, and the stringent data quality requirements. Successfully navigating these hurdles required a combination of technical expertise, creative problem-solving, and a strong collaborative spirit between our team and the client’s stakeholders.
Data Source Variability and Integration
One of the major challenges involved integrating data from disparate sources with varying formats and levels of quality. Some data sources were structured databases, while others were unstructured files like CSV, JSON, and XML. Furthermore, data consistency and accuracy varied significantly across these sources.
Real-time Processing Requirements
A critical business requirement was the near real-time processing of certain data streams. This necessitated the implementation of high-throughput, low-latency components within the pipeline, which added significant complexity to the architecture and required careful optimization.
Data Quality and Validation Challenges
Ensuring data quality was paramount. We encountered numerous instances of missing values, inconsistent data formats, and outliers that needed to be addressed to maintain data integrity and accuracy. The development of robust data validation and cleansing procedures was crucial for achieving this.
| Challenge | Solution | Business Impact | Example |
|---|---|---|---|
| Data Source Variability and Integration | Developed custom ETL scripts and utilized schema mapping techniques to handle diverse data formats. Implemented data transformation logic to standardize data structures. | Enabled seamless integration of data from disparate sources, providing a unified view of customer data. | Successfully integrated customer data from a legacy CRM system (flat files), a modern marketing automation platform (API), and a transactional database (SQL). |
| Real-time Processing Requirements | Implemented a message queue (e.g., Kafka) to handle high-volume, real-time data streams. Utilized optimized data processing frameworks (e.g., Spark Streaming) for efficient processing. | Enabled near real-time insights into customer behavior, leading to improved decision-making and proactive customer service. | Real-time fraud detection system, triggered by transaction data streamed directly from the payment gateway. |
| Data Quality and Validation Challenges | Implemented data profiling and cleansing routines to identify and correct inconsistencies. Developed automated data quality checks and reporting mechanisms. | Improved data accuracy and reliability, leading to more trustworthy business insights and improved reporting. | Automated detection and correction of inconsistent address formats within the customer database, resulting in a 98% reduction in address-related errors. |
| Scalability and Maintainability | Designed the pipeline using a modular and scalable architecture, employing cloud-based infrastructure (e.g., AWS, Azure, GCP). Implemented robust monitoring and logging capabilities. | Ensured the pipeline could handle increasing data volumes and evolving business requirements, while maintaining ease of maintenance and updates. | The pipeline successfully scaled to handle a 300% increase in data volume during peak seasons without performance degradation. |
Scalability and Maintainability
Building a data pipeline that’s not only effective today but also adaptable to future growth is crucial. This case study focused on creating a robust and scalable ETL process, anticipating the inevitable increase in data volume and complexity. Our approach prioritized modular design and efficient resource utilization to ensure long-term maintainability and performance.This section details the strategies employed to achieve scalability and maintainability, covering aspects like infrastructure choices, code design, and monitoring procedures.
We’ll also highlight best practices that ensured the pipeline’s resilience and efficiency.
Scalable Infrastructure
We leveraged cloud-based infrastructure (specifically AWS) for its inherent scalability. By utilizing services like S3 for storage, EMR for processing, and RDS for database management, we could easily scale resources up or down based on demand. This eliminated the need for significant upfront capital investment in hardware and allowed us to adapt to fluctuating data volumes without compromising performance.
For instance, during peak processing periods, we automatically scaled up the number of EMR nodes, handling the increased load effectively. Conversely, during periods of low activity, we scaled down, optimizing cost efficiency.
My latest case study focuses on data pipeline orchestration and ETL – a real headache to manage efficiently! I found that building robust, scalable solutions often involves a lot of custom code, but I’ve been exploring ways to streamline the process. Check out this article on domino app dev the low code and pro code future for some interesting ideas on low-code development; it’s got me thinking about how to apply those principles to my ETL processes for a more efficient case study analysis.
Modular Pipeline Design
The pipeline was designed using a modular approach, breaking down the ETL process into independent, reusable components. This modularity simplified maintenance and updates. Changes to one component didn’t necessitate a complete pipeline rebuild. For example, if we needed to update the data transformation logic for a specific data source, we could modify only the relevant module without affecting other parts of the pipeline.
This modularity also fostered easier testing and debugging.
Pipeline Monitoring and Adjustment
Continuous monitoring was essential for maintaining pipeline performance. We implemented comprehensive logging and alerting mechanisms using tools like CloudWatch. This allowed us to proactively identify and address performance bottlenecks or errors. Real-time dashboards provided a clear overview of pipeline health, enabling us to promptly react to any anomalies. For example, a sudden spike in processing time triggered an alert, leading to an investigation that revealed a poorly performing database query, which was subsequently optimized.
Best Practices for Maintaining a Robust and Efficient Data Pipeline
Maintaining a robust and efficient data pipeline requires consistent effort and adherence to best practices. The following points summarize our key strategies:
- Version Control: All pipeline code and configurations were stored in a version control system (Git), enabling easy tracking of changes and facilitating rollbacks if necessary.
- Automated Testing: Comprehensive automated tests were implemented to ensure the accuracy and reliability of the pipeline. This included unit tests for individual components and integration tests for the entire pipeline.
- Regular Maintenance: Scheduled maintenance windows were allocated for routine tasks such as software updates, performance tuning, and log cleanup.
- Documentation: Thorough documentation of the pipeline’s architecture, components, and processes was crucial for facilitating collaboration and knowledge transfer.
- Data Lineage Tracking: Implementing data lineage tracking provided a clear understanding of data flow and transformation, simplifying debugging and troubleshooting.
Security Considerations: Case Study Data Pipeline Orchestration Etl Use Case
Data security is paramount in any data pipeline, especially one handling sensitive information. Our case study’s ETL process involved several potential vulnerabilities, necessitating a robust security strategy encompassing data at rest, in transit, and in use. The following sections detail the risks identified and the implemented mitigation strategies.
Data Security Risks
The pipeline processed Personally Identifiable Information (PII) and financial data, making it a target for various attacks. Potential risks included unauthorized access, data breaches, data modification, and denial-of-service attacks. Specific vulnerabilities considered were insecure network connections, inadequate access controls, and insufficient data encryption. Furthermore, the risk of insider threats, malicious or accidental data exposure by authorized personnel, was also accounted for.
Security Measures Implemented, Case study data pipeline orchestration etl use case
To address these risks, a multi-layered security approach was adopted. Data encryption, both at rest and in transit, was a cornerstone of our strategy. We utilized AES-256 encryption for data stored in databases and cloud storage, and TLS 1.3 or higher for all network communications. Access control was implemented using role-based access control (RBAC), limiting access to sensitive data based on user roles and responsibilities.
Regular security audits and penetration testing were conducted to identify and remediate vulnerabilities proactively. Furthermore, a robust logging and monitoring system tracked all data access and modifications, facilitating the detection of suspicious activities. All systems involved in the pipeline were regularly patched and updated to address known security vulnerabilities.
Data Privacy Regulation Compliance
The pipeline design adhered to relevant data privacy regulations, including GDPR and CCPA. Data minimization principles were applied, collecting only necessary data and retaining it only for the required duration. Consent management mechanisms were integrated for data subjects’ explicit consent where required. Data anonymization and pseudonymization techniques were employed where feasible to reduce the risk of identifying individuals.
We implemented robust data subject access request (DSAR) processes to allow individuals to access, rectify, or delete their personal data. Comprehensive documentation was maintained to demonstrate compliance with all relevant regulations.
Best Practices for Securing Sensitive Data
Several best practices were implemented to ensure the security of sensitive data within the ETL process. These included: data masking techniques to protect sensitive data during testing and development; secure configuration management to prevent misconfigurations; input validation to prevent injection attacks; and regular security awareness training for all personnel involved in the pipeline. The principle of least privilege was strictly enforced, granting users only the necessary access rights to perform their duties.
Data loss prevention (DLP) tools were deployed to monitor and prevent sensitive data from leaving the controlled environment. Finally, a comprehensive incident response plan was established to handle security incidents effectively and minimize potential damage.
Conclusion
Building a successful data pipeline is a journey, not a destination. This case study has highlighted the importance of careful planning, robust architecture, and a relentless focus on data quality. From defining the scope and choosing the right tools to implementing security measures and ensuring scalability, every step is crucial. Remember, the key to success lies in understanding your specific business needs, adapting your approach accordingly, and embracing continuous improvement.
I hope this deep dive has inspired you to tackle your own data challenges with confidence and creativity!
Clarifying Questions
What are the common pitfalls to avoid when designing a data pipeline?
Common pitfalls include neglecting data quality checks, insufficient error handling, overlooking scalability needs, and failing to document the pipeline thoroughly. Choosing the wrong tools for the job is another frequent mistake.
How can I choose the right ETL tool for my needs?
Consider factors like data volume, velocity, variety, and complexity. Evaluate the tool’s features, scalability, cost, and ease of use. Many offer free trials, allowing you to test them before committing.
What are some best practices for data security in an ETL pipeline?
Implement encryption both in transit and at rest, use access control mechanisms, regularly audit your pipeline for vulnerabilities, and comply with relevant data privacy regulations.