Digital Transformation Turning Corporate Dreams Real
Digital transformation turning corporate dreams into real outcomes isn’t just a buzzword; it’s a revolution reshaping how businesses operate and compete. We’re talking about a fundamental shift, moving beyond simple tech upgrades to a complete overhaul of processes, culture, and even the very definition of a company’s purpose. This isn’t about adding a new app; it’s about reimagining the entire business model to leverage the power of data, automation, and innovative technologies.
Get ready to explore how companies are making the leap from ambitious visions to tangible, measurable success.
This journey involves careful planning, strategic technology selection, and a commitment to fostering a digital-first culture. We’ll dissect the key elements—from defining SMART goals and choosing the right tech stack to managing change and measuring ROI. We’ll look at real-world examples of companies that have successfully navigated this transformation, highlighting their strategies and the lessons learned along the way.
Whether you’re a CEO charting a new course or a team member eager to understand the impact of digital transformation, this exploration is for you.
Defining Digital Transformation in the Corporate Context
Digital transformation is more than just adopting new technologies; it’s a fundamental shift in how a company operates, driven by the strategic use of digital technologies to create new business models, improve efficiency, and enhance customer experiences. It’s about leveraging data, automation, and connectivity to fundamentally reshape a business’s core processes and offerings. This isn’t a one-time project, but rather an ongoing journey of continuous improvement and adaptation.Digital transformation in large organizations necessitates a holistic approach, impacting every aspect from operations and marketing to human resources and customer service.
It requires a significant investment in both technology and people, with a focus on creating a culture of innovation and adaptability.
Core Components of Successful Digital Transformation Initiatives
Successful digital transformation initiatives hinge on several interconnected components. Firstly, a clear and well-defined strategy is crucial, outlining the desired outcomes and the steps needed to achieve them. This strategy should be aligned with the overall business goals and supported by strong leadership commitment. Secondly, robust data infrastructure and analytics capabilities are essential for understanding customer behavior, optimizing processes, and making data-driven decisions.
Digital transformation is all about making those ambitious corporate visions a reality. It’s about bridging the gap between idea and execution, and that’s where tools like low-code/no-code platforms become crucial. For a deep dive into how this is shaping the future of application development, check out this insightful article on domino app dev, the low-code and pro-code future.
Ultimately, faster, more efficient app development is key to making digital transformation dreams a tangible success for businesses of all sizes.
Thirdly, a focus on customer experience is paramount; digital transformation should enhance the customer journey and create personalized interactions. Finally, the organization must cultivate a culture of innovation and continuous learning, empowering employees to embrace new technologies and adapt to changing business needs. Without these elements working in harmony, digital transformation efforts are unlikely to deliver their full potential.
Digital Transformation vs. Simple Technology Upgrades
While both involve technological changes, digital transformation and simple technology upgrades are fundamentally different. Technology upgrades typically focus on replacing outdated systems or adding new features to existing ones, often with a limited scope. Digital transformation, however, is a much broader and more strategic initiative that aims to fundamentally change how the business operates and creates value. It involves rethinking processes, restructuring operations, and adopting new business models.
A simple technology upgrade might involve switching to a new CRM system, whereas digital transformation might involve using AI-powered analytics to personalize customer interactions and automate marketing campaigns, potentially resulting in the creation of entirely new revenue streams.
Examples of Successful Digital Transformation, Digital transformation turning corporate dreams into real outcomes
Several companies have successfully implemented digital transformation. Netflix, for instance, transitioned from a DVD rental service to a global streaming giant by leveraging data analytics to understand viewer preferences and investing heavily in original content. Their digital transformation involved a complete overhaul of their business model, enabling them to reach a far wider audience and establish a new industry standard.
Similarly, Amazon’s digital transformation involved building a sophisticated e-commerce platform and leveraging data to personalize customer experiences, creating a seamless and efficient shopping journey. Their continued investment in cloud computing, AI, and logistics has further cemented their position as a global leader in e-commerce.
Comparison of Traditional and Digitally Transformed Business Models
| Feature | Traditional Business Model | Digitally Transformed Business Model | Example |
|---|---|---|---|
| Customer Interaction | Primarily in-person or phone-based | Personalized and omnichannel (online, mobile, social media) | Brick-and-mortar store vs. e-commerce with personalized recommendations |
| Data Usage | Limited data collection and analysis | Extensive data collection and analysis for insights and decision-making | Sales reports vs. real-time customer analytics dashboards |
| Operations | Manual and often siloed processes | Automated and integrated processes, often leveraging cloud technologies | Paper-based inventory management vs. real-time inventory tracking and automated ordering |
| Innovation | Incremental improvements | Rapid innovation and agility through iterative development and experimentation | Annual product updates vs. continuous releases of new features and services |
Identifying Corporate Dreams and Translating Them into Measurable Goals
Digital transformation isn’t just about adopting new technologies; it’s about fundamentally reshaping your business to achieve ambitious goals. This requires moving beyond abstract corporate visions and translating them into concrete, actionable steps. This involves a clear understanding of your aspirations and a robust framework for measuring progress.The process of transforming vague aspirations into measurable results necessitates a structured approach.
It’s about bridging the gap between aspirational statements and tangible achievements, ensuring that every digital initiative contributes directly to the overarching business strategy. This involves a deep dive into your company’s strategic objectives, identifying the role digital technologies can play, and defining clear metrics for success.
Translating Abstract Visions into SMART Goals
Transforming abstract corporate visions into actionable plans requires utilizing the SMART framework. This framework ensures goals are Specific, Measurable, Achievable, Relevant, and Time-bound. For example, instead of a vague goal like “improve customer experience,” a SMART goal might be: “Increase customer satisfaction scores (measured by Net Promoter Score) by 15% within the next six months through the implementation of a new CRM system and improved online support channels.” This level of specificity provides clarity and direction for the entire team.
Aligning Digital Transformation Strategies with Business Objectives
Effective digital transformation isn’t a standalone initiative; it must be deeply integrated with the overall business strategy. This alignment requires a thorough understanding of the company’s strategic priorities, identifying areas where digital technologies can create the most significant impact. For example, a company aiming to increase market share might prioritize digital marketing and e-commerce initiatives. Conversely, a company focused on operational efficiency might concentrate on automating processes and improving data analytics.
Aligning strategies involves mapping specific digital projects to these strategic objectives, ensuring every effort contributes to the bigger picture.
Identifying Key Performance Indicators (KPIs) for Digital Transformation Success
Defining relevant KPIs is crucial for monitoring progress and demonstrating the value of digital transformation initiatives. KPIs should be chosen based on the specific goals and objectives. For example, if the goal is to improve website conversion rates, relevant KPIs might include bounce rate, average session duration, and conversion rate itself. If the objective is to enhance customer engagement, KPIs could include social media engagement metrics, customer satisfaction scores, and email open and click-through rates.
Regularly monitoring these KPIs allows for timely adjustments to the strategy and ensures the digital transformation remains on track. A well-defined dashboard, visualizing these key metrics, is essential for effective monitoring and decision-making.
Common Pitfalls to Avoid When Setting Goals for Digital Transformation
Setting ambitious yet achievable goals is key to successful digital transformation. Several common pitfalls can derail progress. One frequent mistake is setting overly ambitious goals that are unattainable within the given timeframe or resources. Another common issue is failing to align digital transformation goals with the overall business strategy, leading to disjointed initiatives that don’t contribute to the company’s overall success.
Finally, neglecting to define and track relevant KPIs can make it difficult to assess the effectiveness of the transformation efforts. Avoiding these pitfalls requires careful planning, realistic goal setting, and consistent monitoring of progress. A phased approach, breaking down the transformation into smaller, manageable projects, can also help mitigate risks and ensure sustainable progress.
Technology Selection and Implementation Strategies
Choosing the right technologies and implementing them effectively are critical for successful digital transformation. A poorly chosen technology stack can lead to project delays, budget overruns, and ultimately, failure to achieve desired business outcomes. Strategic planning and a deep understanding of both business needs and technological capabilities are paramount.
Factors to Consider When Choosing Technologies
Selecting technologies for digital transformation requires a careful assessment of several key factors. These factors influence not only the immediate implementation but also the long-term scalability and maintainability of the chosen solutions. Ignoring these factors can lead to significant challenges down the line.
- Business Needs Alignment: Technology should directly support strategic business goals. For example, if a company aims to improve customer service, it might invest in a CRM system and AI-powered chatbots. The technology must demonstrably address a specific business problem or opportunity.
- Scalability and Flexibility: Chosen technologies must be able to handle increasing data volumes and user traffic as the business grows. Cloud-based solutions often offer better scalability compared to on-premise systems.
- Integration Capabilities: Seamless integration with existing systems is crucial. A new system that doesn’t integrate well with legacy systems can create data silos and hinder efficiency.
- Vendor Support and Expertise: Reliable vendor support and readily available expertise are essential for successful implementation and ongoing maintenance. Choosing a vendor with a strong track record and a proven support system is critical.
- Security and Privacy: Data security and privacy must be paramount considerations. Technologies should comply with relevant regulations (e.g., GDPR, CCPA) and offer robust security features to protect sensitive data.
- Cost and Return on Investment (ROI): A thorough cost-benefit analysis is necessary to ensure that the investment in new technologies aligns with the expected return. This includes not only the initial investment but also ongoing maintenance and operational costs.
Cloud Computing Models and Their Suitability
Cloud computing offers various models, each with its strengths and weaknesses. The choice of model depends on the specific business needs, budget, and risk tolerance.
- IaaS (Infrastructure as a Service): Provides virtualized computing resources, such as servers, storage, and networking. Suitable for businesses with significant IT expertise and a desire for maximum control over their infrastructure. Example: Amazon Web Services (AWS) EC2.
- PaaS (Platform as a Service): Offers a platform for developing, deploying, and managing applications. Reduces the burden of managing infrastructure, allowing developers to focus on application development. Example: Google App Engine.
- SaaS (Software as a Service): Provides ready-to-use software applications over the internet. Requires minimal IT expertise and is often the most cost-effective option for smaller businesses. Example: Salesforce CRM.
Data Security and Privacy in Digital Transformation
Data security and privacy are not merely compliance requirements; they are fundamental to maintaining trust with customers and partners. Breaches can lead to significant financial losses, reputational damage, and legal repercussions.
Implementing robust security measures throughout the digital transformation process is crucial. This includes encryption, access controls, regular security audits, and employee training on data security best practices. Compliance with relevant data privacy regulations, such as GDPR and CCPA, is also essential. A well-defined data governance framework should be established to manage data access, storage, and usage throughout the organization.
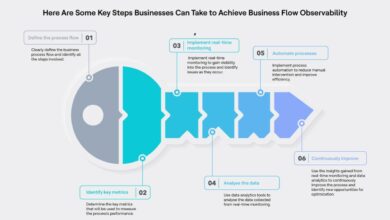
Technology Implementation Stages
Successful technology implementation follows a structured approach. A phased rollout minimizes disruption and allows for iterative improvements.
The following flowchart illustrates a typical process:
Flowchart:
[1] Planning & Assessment: Defining project scope, goals, and resources. This involves a thorough needs assessment and feasibility study.
[2] Design & Development: Designing the system architecture, selecting technologies, and developing or customizing software.
[3] Testing & Quality Assurance: Rigorous testing to identify and resolve bugs and ensure system stability and performance.
[4] Deployment & Migration: Deploying the new system, migrating data from existing systems, and training users.
[5] Monitoring & Optimization: Continuously monitoring system performance, identifying areas for improvement, and making necessary adjustments.
This process is iterative; feedback from each stage informs the next, ensuring continuous improvement and alignment with evolving business needs.
Managing Change and Building a Digital Culture

Digital transformation isn’t just about technology; it’s about people. Successfully navigating this shift requires a strategic approach to managing change and cultivating a digital-first culture. This involves understanding the inherent challenges, proactively addressing employee concerns, and fostering an environment where innovation thrives. Without a focus on people, even the most advanced technology will struggle to deliver its promised benefits.Successfully implementing digital transformation hinges on effectively managing the inevitable organizational changes it brings.
Resistance to change, fear of job displacement, and a lack of understanding about the new technologies and processes are common hurdles. Overcoming these requires a multifaceted strategy that prioritizes communication, training, and leadership buy-in. Failure to adequately address these challenges can lead to project delays, low adoption rates, and ultimately, the failure of the entire transformation initiative.
Challenges in Managing Organizational Change During Digital Transformation
Resistance to change is a predictable yet significant obstacle. Employees accustomed to established workflows and systems may be hesitant to embrace new technologies and processes. This resistance can manifest as passive resistance (slow adoption, lack of engagement) or active resistance (open opposition, sabotage). Furthermore, fear of job displacement due to automation is a very real concern that needs to be addressed directly and transparently.
A lack of clarity regarding the transformation’s purpose, goals, and impact on individual roles can further exacerbate anxieties and fuel resistance. Finally, insufficient training and support can leave employees feeling overwhelmed and unprepared, hindering their ability to effectively utilize new systems and processes. Addressing these challenges requires a combination of clear communication, comprehensive training, and a supportive leadership team that actively champions the change.
The Importance of Employee Training and Development
Employee training and development are not merely supplementary; they are essential components of successful digital transformation. Equipping employees with the necessary skills and knowledge to use new technologies and processes is crucial for maximizing the return on investment. This goes beyond basic technical training; it includes training on new workflows, collaboration tools, and data analysis techniques. Furthermore, upskilling and reskilling initiatives are vital for mitigating fears of job displacement.
By providing opportunities for employees to learn new skills, companies can demonstrate their commitment to their workforce’s future and foster a sense of security and engagement. A well-structured training program should be tailored to different roles and skill levels, utilizing a variety of methods, including online courses, workshops, and mentorship programs. Continuous learning and development should also be encouraged to ensure employees stay current with evolving technologies and best practices.
Strategies for Fostering a Culture of Innovation and Digital Fluency
Cultivating a culture of innovation and digital fluency requires a proactive and sustained effort. This starts with leadership commitment; senior management must actively champion the transformation and model the desired behaviors. Creating cross-functional teams that include representatives from different departments can facilitate collaboration and knowledge sharing. Establishing innovation hubs or dedicated spaces for experimentation and idea generation can provide a dedicated environment for employees to explore new ideas without fear of failure.
Regularly recognizing and rewarding innovative contributions can further incentivize creativity and experimentation. Encouraging employees to share their ideas and feedback through open forums and suggestion boxes can ensure that all voices are heard and valuable insights are incorporated into the transformation process. Finally, providing access to relevant resources and tools, such as online learning platforms and industry publications, can empower employees to continuously enhance their digital skills and knowledge.
Best Practices for Communicating the Value of Digital Transformation to Employees
Effective communication is paramount to securing employee buy-in and ensuring the success of a digital transformation initiative. Here are some best practices:
- Clearly articulate the “why”: Explain the strategic rationale behind the transformation, highlighting the benefits for the company and its employees.
- Transparency and open communication: Keep employees informed about the progress of the transformation, addressing concerns and providing regular updates.
- Tailor communication to different audiences: Use different communication channels and formats to reach employees at all levels, ensuring messages are relevant and easily understood.
- Showcase success stories: Highlight early wins and positive outcomes to build momentum and demonstrate the value of the transformation.
- Engage employees in the process: Seek employee feedback and input, creating a sense of ownership and collaboration.
- Provide ongoing support and resources: Offer readily accessible help desks, training materials, and mentorship opportunities to support employees throughout the transformation.
- Celebrate milestones: Acknowledge and reward individual and team contributions to boost morale and reinforce positive behaviors.
Measuring and Evaluating the Outcomes of Digital Transformation
Successfully navigating a digital transformation isn’t just about implementing new technologies; it’s about demonstrably improving business outcomes. Measuring and evaluating the impact of your initiatives is crucial for justifying the investment, identifying areas for improvement, and ensuring continued success. This involves a strategic approach that combines both quantitative and qualitative data to paint a complete picture of your transformation’s effectiveness.
Tracking progress against pre-defined goals requires a robust measurement framework established at the outset of your transformation. This framework should align with your overall business objectives and incorporate key performance indicators (KPIs) that reflect the specific changes you’re aiming for. Regular monitoring and analysis of these KPIs are essential for identifying successes, addressing challenges, and making data-driven adjustments to your strategy.
Without this ongoing evaluation, it’s difficult to determine whether your investments are truly yielding the desired results.
Data Analytics for Monitoring Business Performance
Data analytics provides the critical insights needed to understand the impact of digital transformation on key business functions. By analyzing data from various sources – such as CRM systems, sales platforms, and operational databases – organizations can gain a clear understanding of how their digital initiatives are affecting efficiency, productivity, customer satisfaction, and ultimately, profitability. For example, analyzing website traffic data can reveal the effectiveness of new digital marketing campaigns, while analyzing operational data can highlight improvements in process automation and cost reduction.
This data-driven approach enables informed decision-making and facilitates continuous improvement.
Return on Investment (ROI) Metrics for Digital Transformation Projects
Demonstrating a clear return on investment is paramount for securing continued support for digital transformation initiatives. Several metrics can be used to evaluate the ROI of specific projects. These include:
- Cost Savings: Quantify reductions in operational expenses achieved through automation, process optimization, or reduced manual effort. For example, automating a previously manual process might reduce labor costs by 20%.
- Revenue Growth: Measure the increase in revenue generated as a direct result of the digital transformation project. Launching a new e-commerce platform, for example, might lead to a 15% increase in sales.
- Improved Efficiency: Calculate the percentage increase in efficiency resulting from streamlined processes or improved workflows. Implementing a new project management system might improve team efficiency by 25%.
- Enhanced Customer Satisfaction: Track changes in customer satisfaction metrics, such as Net Promoter Score (NPS) or customer churn rate, to assess the impact of improved customer experience initiatives. A new customer support chatbot might result in a 10% increase in NPS.
Examples of Qualitative and Quantitative Metrics
The following table summarizes examples of both qualitative and quantitative metrics used to evaluate the success of digital transformation initiatives. A balanced approach, incorporating both types of metrics, provides a comprehensive view of the transformation’s impact.
| Metric Type | Metric Example | Measurement Method | Example Value/Result |
|---|---|---|---|
| Quantitative | Website Conversion Rate | Analyze website analytics data | Increased from 2% to 5% |
| Quantitative | Customer Acquisition Cost (CAC) | Track marketing spend and new customer acquisition | Reduced from $100 to $75 |
| Quantitative | Employee Productivity (measured in units produced per hour) | Track output and working hours | Increased by 15% |
| Qualitative | Employee Satisfaction (measured through surveys) | Conduct employee surveys | Improved employee morale and engagement |
| Qualitative | Customer Feedback (gathered through surveys and reviews) | Analyze customer reviews and feedback forms | Positive feedback on improved website usability |
| Qualitative | Improved Collaboration (measured through observation and feedback) | Observe team dynamics and collect feedback | Increased cross-functional collaboration |
Overcoming Barriers and Challenges in Digital Transformation
Digital transformation, while promising immense benefits, is rarely a smooth journey. Organizations often encounter significant hurdles that can derail even the most well-intentioned initiatives. Understanding these barriers and developing proactive strategies to overcome them is crucial for successful implementation. This section explores common challenges and offers practical solutions to navigate them effectively.Successful digital transformation requires addressing various interconnected challenges.
These obstacles often stem from a combination of internal resistance, resource constraints, and leadership shortcomings. Overcoming these requires a multifaceted approach, combining technological solutions with robust change management strategies.
Resistance to Change
Resistance to change is a pervasive challenge in any organizational transformation. Employees accustomed to established workflows and systems may be hesitant to adopt new technologies or processes. This resistance can manifest in various forms, from passive non-compliance to active opposition. Strategies to overcome this include clear communication, comprehensive training programs, and actively involving employees in the transformation process.
Demonstrating the tangible benefits of the transformation, addressing concerns proactively, and providing adequate support are key to fostering acceptance and buy-in. For example, a company implementing a new CRM system should offer extensive training sessions, provide readily available support staff, and clearly demonstrate how the new system will streamline their daily tasks and reduce workload.
Lack of Resources
Digital transformation initiatives require significant investments in technology, talent, and time. A lack of resources, whether financial, human, or technological, can severely hamper progress. Careful planning and resource allocation are essential. Prioritization of projects, exploring cost-effective solutions, and building a strong business case to secure necessary funding are vital. For instance, a company might opt for a phased rollout of new software instead of a complete, immediate overhaul to manage costs and minimize disruption.
Inadequate Leadership
Effective leadership is paramount to successful digital transformation. Leaders must champion the initiative, create a compelling vision, and provide the necessary support and guidance. Without strong leadership, the transformation effort can lose momentum, encounter resistance, and ultimately fail. Leaders need to clearly articulate the strategic goals, actively communicate progress, and celebrate successes to maintain motivation and engagement.
A leader’s visible commitment and active participation are powerful catalysts for change.
Potential Risks and Mitigation Strategies
Effective risk management is crucial for successful digital transformation. Failing to address potential risks can lead to project delays, cost overruns, and even complete failure.
Below is a list of potential risks and corresponding mitigation strategies:
- Risk: Data security breaches. Mitigation: Implement robust cybersecurity measures, including data encryption, access controls, and regular security audits.
- Risk: Integration challenges with existing systems. Mitigation: Conduct thorough compatibility assessments before implementation, and develop a comprehensive integration plan.
- Risk: Lack of employee adoption. Mitigation: Provide comprehensive training, offer ongoing support, and actively solicit feedback from employees.
- Risk: Project delays and cost overruns. Mitigation: Develop a detailed project plan with realistic timelines and budgets, and regularly monitor progress.
- Risk: Failure to achieve desired outcomes. Mitigation: Establish clear KPIs, regularly monitor performance, and make adjustments as needed.
Case Studies of Successful Digital Transformation
Digital transformation isn’t a one-size-fits-all solution. Success hinges on a tailored approach that considers the unique circumstances of each organization. Examining successful case studies provides invaluable insights into effective strategies, common challenges, and measurable outcomes. The following examples illustrate diverse approaches to digital transformation and highlight the transformative power of embracing technology and adapting organizational culture.
Netflix’s Transition from DVD Rentals to Streaming
Netflix’s transformation from a DVD-by-mail service to a global streaming giant is a textbook example of successful digital adaptation. Pre-transformation, their process involved physical media handling, distribution, and customer service centered around mail-order logistics. A visual representation would show a complex flowchart with numerous steps: customer order, warehouse picking, packaging, shipping, return processing, and customer service interactions largely handled via phone.
This process was visually cluttered, with multiple manual handoffs and potential bottlenecks.Post-transformation, a simplified visual representation would depict a streamlined, digital-first process. The flowchart would be far less complex, showcasing a direct customer-to-server interaction. The visual would highlight the central role of the streaming platform, algorithms for content recommendation, and a robust digital customer service interface. Clean lines and minimal steps would convey the efficiency of the new system.
The color scheme could shift from muted browns and grays (representing the physical media) to vibrant blues and reds (symbolizing the dynamic digital experience). Key elements like user profiles, personalized recommendations, and seamless payment processing would be visually emphasized.Netflix faced challenges in transitioning its infrastructure, managing massive data volumes, and securing content rights. However, its proactive embrace of streaming technology, data-driven decision-making, and focus on customer experience resulted in exponential growth and market dominance.
Walmart’s Supply Chain Optimization Through Data Analytics
Before its digital transformation, Walmart’s supply chain relied heavily on manual processes and limited data visibility. A visual representation would depict a network of disparate systems with information silos. The illustration would use a muted color palette and show multiple disconnected boxes representing various departments (warehousing, logistics, retail stores) with limited data flow between them. Arrows representing information flow would be thin and scattered, reflecting inefficiencies.Post-transformation, Walmart leveraged data analytics to optimize its supply chain.
The visual representation would show a centralized, integrated system. The illustration would use a brighter color scheme, and the boxes representing different departments would be interconnected by thick, brightly colored arrows, indicating seamless data flow. The central focus would be a large, vibrant data hub, illustrating the power of centralized data analysis in predicting demand, optimizing inventory, and streamlining logistics.
Visual elements could include real-time dashboards showcasing key performance indicators (KPIs) like inventory levels and delivery times.Walmart faced challenges in integrating legacy systems, building a robust data infrastructure, and upskilling its workforce. However, the company’s investment in data analytics and automation significantly improved efficiency, reduced costs, and enhanced customer satisfaction.
Adobe’s Transition to a Subscription Model
Adobe’s shift from a perpetual license model to a subscription-based Creative Cloud is another compelling example. Pre-transformation, the visual representation would depict a complex, one-time purchase process. The illustration would emphasize individual product boxes (Photoshop, Illustrator, etc.) and the transactional nature of the sales process. The colors could be muted and the overall impression one of discrete, individual purchases.Post-transformation, the visual would highlight a seamless, subscription-based ecosystem.
The illustration would show a single, unified Creative Cloud platform with interconnected applications. The color scheme would be brighter and more unified, representing the integrated nature of the service. Key visual elements would include ongoing updates, collaborative features, and a consistent user experience across applications. The visual would emphasize the recurring revenue model and the value proposition of continuous access to updated software.Adobe faced challenges in convincing customers to adopt a subscription model, managing the transition of existing users, and maintaining the quality of its software.
However, the company’s strategic move towards a subscription model significantly increased its recurring revenue, fostered stronger customer relationships, and enabled faster innovation.
Final Wrap-Up

Ultimately, digital transformation turning corporate dreams into real outcomes requires a holistic approach. It’s about more than just technology; it’s about people, processes, and a clear vision of the future. By understanding the challenges, embracing innovation, and measuring success along the way, businesses can harness the power of digital transformation to achieve ambitious goals and create lasting value. The journey may be challenging, but the rewards are immense – a more agile, efficient, and competitive organization ready to thrive in the ever-evolving digital landscape.
Let’s embark on this transformative journey together!
Helpful Answers: Digital Transformation Turning Corporate Dreams Into Real Outcomes
What’s the biggest mistake companies make during digital transformation?
Underestimating the importance of change management and employee buy-in. Technology is only part of the equation; successfully integrating it requires a supportive culture and well-trained workforce.
How long does digital transformation typically take?
There’s no one-size-fits-all answer. It depends on the company’s size, complexity, and the scope of the transformation. It can range from a few months to several years.
What if we don’t have a large budget for digital transformation?
Start small and focus on high-impact areas. Prioritize projects with a clear ROI and phased implementation allows for adjustments based on learnings and available resources.
How do we measure the success of our digital transformation efforts?
Define key performance indicators (KPIs) aligned with your business objectives. Track metrics related to efficiency, customer satisfaction, revenue growth, and cost reduction. Regularly analyze data to assess progress and make necessary adjustments.