
Exploring the Threat of Data Poisoning in Cybersecurity
Exploring the threat of data poisoning in cybersecurity, we delve into a stealthy attack vector that silently undermines the integrity of our digital world. Data poisoning, a sophisticated attack that corrupts the very foundation of machine learning models and data-driven systems, is a growing concern. Imagine a self-driving car suddenly veering off course, or a medical diagnosis system providing a completely wrong result – these are the chilling possibilities of a successful data poisoning attack.
This insidious threat targets the data used to train AI and other algorithms, subtly manipulating it to produce incorrect, biased, or even malicious outputs.
From subtle label flipping to more aggressive injection attacks, the methods used are diverse and constantly evolving. We’ll explore various techniques, examine real-world examples of data poisoning in action, and dissect the vulnerabilities that make systems susceptible to this attack. We’ll also discuss the devastating consequences, ranging from financial losses and reputational damage to compromised security and even life-threatening outcomes.
Get ready to uncover the dark side of data manipulation and discover how to defend against this emerging threat.
Introduction to Data Poisoning
Data poisoning, a sneaky and increasingly prevalent cybersecurity threat, involves manipulating the training data used to build machine learning models. This malicious act undermines the integrity and accuracy of these models, leading to flawed predictions and potentially disastrous consequences. Essentially, attackers subtly corrupt the data used to train AI systems, causing these systems to make incorrect or biased decisions, which can be exploited for various malicious purposes.
Understanding the methods and impact of data poisoning is crucial for building robust and secure AI systems.Data poisoning attacks are particularly dangerous because they are often subtle and difficult to detect. The poisoned data blends seamlessly with legitimate data, making it challenging to identify the malicious insertions. The consequences can range from minor inconveniences to significant security breaches, depending on the target and the sophistication of the attack.
Types of Data Poisoning Attacks
Several methods exist for carrying out data poisoning attacks. These methods vary in their complexity and the level of access required by the attacker. Two prominent types are label flipping and injection attacks. Label flipping involves changing the class labels of existing data points, while injection attacks involve introducing entirely new, malicious data points into the training dataset.
Other sophisticated methods may combine these techniques or employ more advanced strategies.
Examples of Real-World Data Poisoning
While specific instances of data poisoning attacks are often kept confidential for security reasons, we can envision several realistic scenarios. Imagine a spam filter trained on a dataset subtly injected with legitimate emails labeled as spam. This would lead to legitimate emails being incorrectly flagged as spam, impacting communication and potentially harming businesses. Another example could involve a facial recognition system trained on a dataset containing images subtly altered to misrepresent individuals, leading to incorrect identifications with serious consequences in security or law enforcement applications.
A more subtle attack might involve poisoning a model used for fraud detection, leading to the system failing to identify fraudulent transactions.
Comparison of Data Poisoning Techniques, Exploring the threat of data poisoning in cybersecurity
The impact of a data poisoning attack significantly depends on the technique used and the target system. The following table summarizes some common techniques and their effects:
| Technique | Description | Impact | Detection Difficulty |
|---|---|---|---|
| Label Flipping | Altering the labels of existing data points. | Reduces model accuracy, introduces bias. | Moderate; anomalies in data distribution may be detectable. |
| Injection Attacks | Introducing new, malicious data points. | Can significantly alter model behavior, leading to specific vulnerabilities. | High; requires advanced anomaly detection techniques. |
| Backdoor Attacks | Introducing data that triggers a specific behavior under certain conditions. | Creates a hidden vulnerability, allowing attackers to control the model’s output. | Very High; requires specialized techniques to detect hidden triggers. |
| Adversarial Examples | Introducing slightly perturbed data points that mislead the model. | Causes misclassification of specific inputs, even with high overall accuracy. | High; subtle changes may be difficult to detect. |
Methods of Data Poisoning
Data poisoning attacks represent a significant threat to the integrity and reliability of machine learning models. Understanding the methods employed by attackers is crucial for developing effective defense mechanisms. This section delves into the techniques used to corrupt training data and bypass detection systems.
A targeted data poisoning attack on a machine learning model typically involves strategically injecting malicious data points into the training dataset. The goal is to subtly influence the model’s learned parameters, causing it to misclassify or make incorrect predictions when presented with unseen data. This manipulation can be achieved through various techniques, depending on the attacker’s access level and knowledge of the target system.
Targeted Data Poisoning Attack Process
A targeted attack often begins with reconnaissance to identify vulnerabilities in the data pipeline. The attacker then crafts malicious data points designed to achieve a specific outcome, such as misclassifying a particular input or skewing the model’s overall performance in a desired way. This crafted data is then injected into the training dataset, either directly or indirectly, before the model is trained.
The attacker may need to overcome data validation or cleansing steps, which we will discuss further. Finally, the poisoned model is deployed, leading to compromised predictions.
Techniques to Bypass Detection Mechanisms
Several techniques help attackers evade detection. These often involve carefully crafting malicious data to blend seamlessly with legitimate data points. One common approach is to introduce only a small number of carefully selected poisoned samples, minimizing the overall impact on data statistics. This reduces the likelihood of triggering anomaly detection systems. Another method is to use adversarial examples, which are carefully perturbed data points designed to fool the model without significantly altering their appearance.
These subtle changes can be incredibly difficult to detect. Finally, attackers may exploit vulnerabilities in the data preprocessing pipeline to inject poison more effectively.
Vulnerabilities in Data Collection and Preprocessing
The data collection and preprocessing stages present several critical vulnerabilities. Insufficient data validation during collection allows malicious data to enter the system undetected. Similarly, inadequate data cleansing and sanitization techniques fail to remove or mitigate the impact of poisoned data points. Lack of data provenance and auditing mechanisms makes it difficult to track the origin and impact of poisoned data.
For instance, a poorly secured data collection API might be exploited to submit malicious data points.
Hypothetical Scenario: Data Poisoning of a Spam Filter
Imagine a spam filter trained on a dataset of emails labeled as spam or not spam. An attacker gains access to the training data pipeline. They inject a large number of carefully crafted emails labeled as “not spam” that contain subtle spam characteristics (e.g., slightly altered URLs, obfuscated s). These emails are designed to bypass basic spam filters but still contain spam indicators.
After training with this poisoned data, the spam filter will misclassify legitimate emails as “not spam,” allowing spam emails to reach users’ inboxes. The attacker might also introduce a few highly legitimate emails labeled as spam to create a false sense of security and make the poisoning less detectable. This subtle manipulation can significantly degrade the filter’s performance without raising immediate alarms.
Impact and Consequences of Data Poisoning: Exploring The Threat Of Data Poisoning In Cybersecurity

Data poisoning, the insidious act of corrupting datasets used to train machine learning models, has far-reaching consequences that extend beyond simple inaccuracies. Its impact reverberates through various systems, causing significant financial losses, reputational damage, and potentially even posing threats to public safety. Understanding these ramifications is crucial for developing robust defenses against this emerging threat.The consequences of successful data poisoning attacks are multifaceted and can severely compromise the integrity and reliability of numerous systems that rely on machine learning.
These systems, ranging from fraud detection algorithms in financial institutions to autonomous driving systems, become vulnerable to manipulation, leading to catastrophic outcomes.
Effects on Machine Learning Model Accuracy and Reliability
Data poisoning directly undermines the accuracy and reliability of machine learning models. By introducing subtly corrupted data points, attackers can manipulate the model’s learning process, causing it to produce biased or incorrect predictions. For example, a poisoned dataset used to train a spam filter might lead the filter to misclassify legitimate emails as spam, resulting in lost communication and potential business disruption.
Similarly, a poisoned dataset used to train a medical diagnosis system could lead to misdiagnosis, potentially with life-threatening consequences. The severity of the impact depends on the scale and sophistication of the poisoning attack, as well as the vulnerability of the targeted model. A small amount of carefully placed poisoned data can have a disproportionately large effect on the model’s performance, especially in models that are already prone to overfitting.
Financial and Reputational Damage from Data Poisoning Incidents
The financial implications of data poisoning can be devastating. A compromised machine learning model used in a financial institution could lead to significant losses due to inaccurate fraud detection, faulty risk assessment, or manipulative trading strategies. Reputational damage can be equally severe. A company whose systems are compromised by a data poisoning attack may suffer a loss of customer trust, leading to decreased sales and market share.
The cost of investigating and remediating a data poisoning incident, including legal fees and public relations efforts, can also be substantial. The 2017 Equifax data breach, while not strictly a data poisoning attack, serves as a stark reminder of the immense financial and reputational costs associated with large-scale data breaches, highlighting the potential impact of similar attacks leveraging data poisoning.
Long-Term Effects of a Successful Data Poisoning Campaign
The long-term effects of a successful data poisoning campaign can be insidious and far-reaching. The compromised model may continue to make inaccurate predictions for an extended period, leading to ongoing financial losses and reputational damage. Moreover, the attacker might gain persistent access to the system, allowing them to continue manipulating the model or extract sensitive information. This can lead to a loss of trust in the affected system, impacting its usability and effectiveness for a prolonged period.
The difficulty in detecting and mitigating data poisoning further exacerbates the long-term consequences, making it a persistent and challenging security threat. In some cases, the damage caused by a successful data poisoning attack might be irreversible, requiring a complete overhaul of the affected system. The development of more resilient and robust machine learning models and data validation techniques is crucial in mitigating these long-term risks.
Detection and Mitigation Strategies
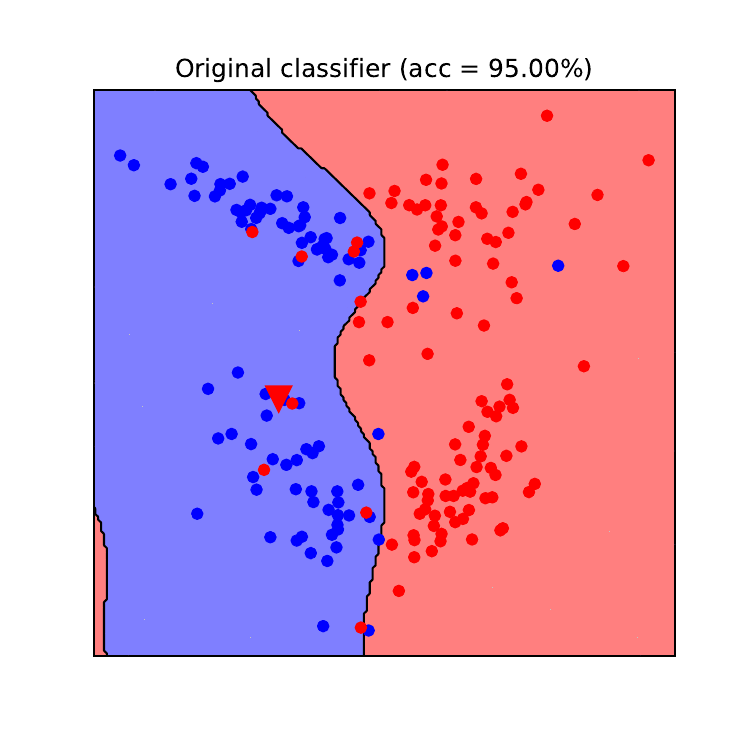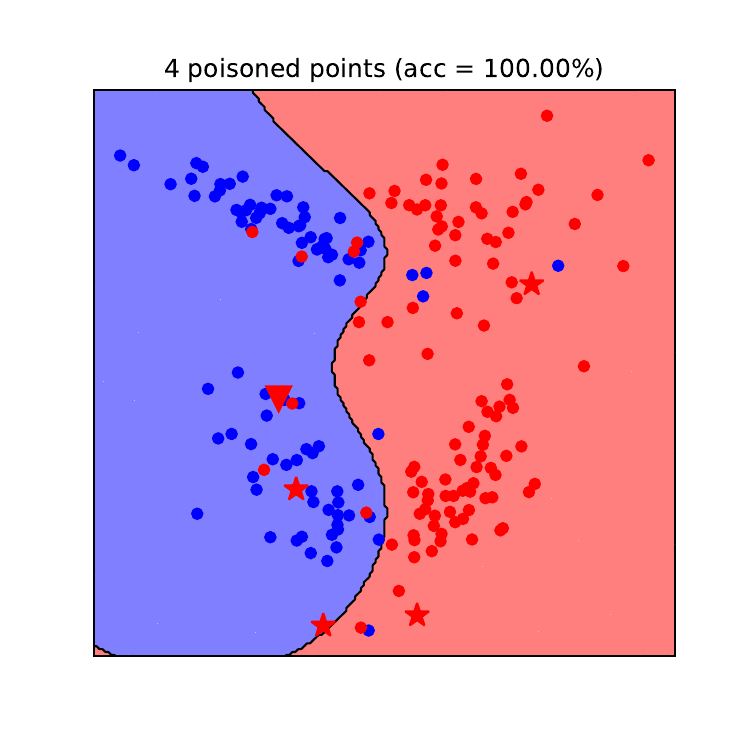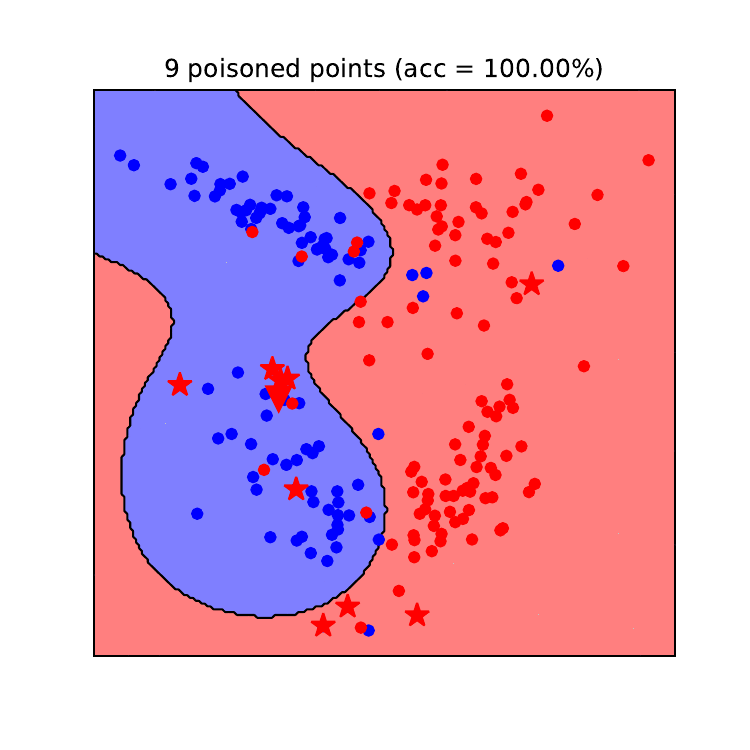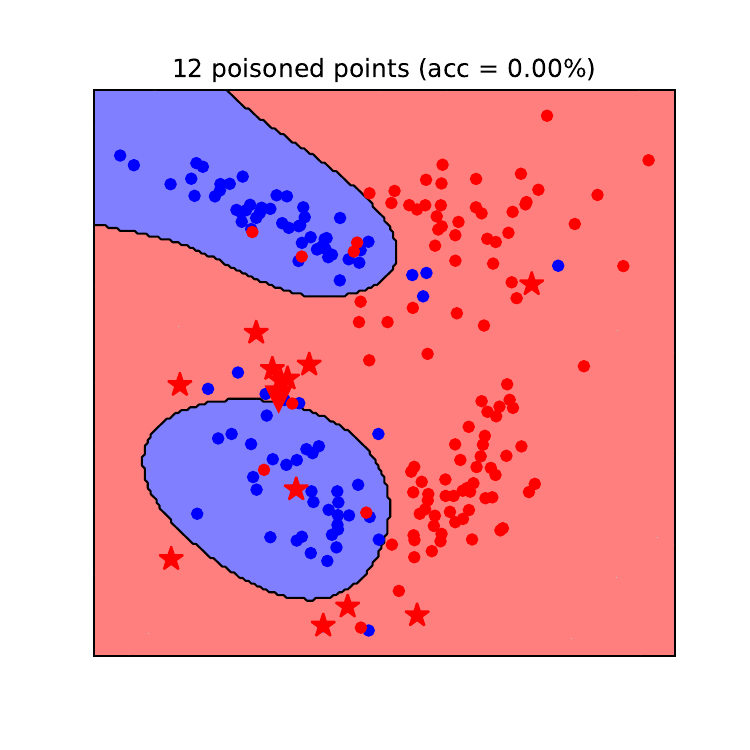
Data poisoning, a sneaky attack that corrupts machine learning models, requires equally clever defenses. Detecting and mitigating these attacks is crucial for maintaining the integrity and reliability of AI systems, especially in security-sensitive applications. Effective strategies combine robust data validation, advanced anomaly detection, and proactive model hardening techniques.
Anomaly Detection Techniques for Identifying Poisoned Data
Anomaly detection plays a vital role in identifying poisoned data points. These techniques aim to flag data instances that deviate significantly from the expected patterns or distributions within the dataset. Methods like clustering algorithms (e.g., k-means, DBSCAN) can group similar data points, highlighting outliers that might be poisoned samples. One-class SVM (Support Vector Machine) is particularly useful when you have a large amount of “normal” data and suspect a small number of poisoned examples.
Statistical methods, such as calculating Z-scores or using hypothesis testing, can also identify data points that fall outside acceptable confidence intervals. For example, if a sudden spike in a particular feature’s values is observed, compared to the historical data distribution, it could indicate a poisoning attempt. The effectiveness of these methods depends heavily on the characteristics of the dataset and the sophistication of the poisoning attack.
Robust Data Validation and Preprocessing
Preventing data poisoning begins with rigorous data validation and preprocessing. This involves implementing checks to ensure data integrity and consistency before it’s used to train a model. Data validation techniques such as schema validation, range checks, and data type checks can identify inconsistencies or anomalies that might indicate poisoning. Preprocessing steps, like outlier removal using techniques mentioned above, can help mitigate the impact of already poisoned data.
Furthermore, techniques like data sanitization, which involves removing or transforming sensitive information, can help reduce the impact of poisoning attacks that target specific features or data points. For instance, removing personally identifiable information (PII) can prevent attacks that manipulate data based on demographic biases.
Data poisoning attacks are a sneaky cybersecurity threat, silently corrupting datasets and undermining machine learning models. Understanding how to mitigate this risk is crucial, especially as we rely more on cloud services. That’s why exploring solutions like those offered by bitglass and the rise of cloud security posture management is so important; robust cloud security is key to preventing poisoned data from entering our systems in the first place and protecting our increasingly cloud-dependent world.
Ultimately, effective cloud security is a critical component of any comprehensive data poisoning defense strategy.
Defensive Strategies Against Data Poisoning: A Comparison
Several defensive strategies can be employed against data poisoning attacks. These strategies can be broadly categorized into data-centric and model-centric approaches. Data-centric approaches focus on improving the robustness of the data itself, while model-centric approaches focus on building models that are less susceptible to poisoning.Data-centric defenses, like those discussed above, emphasize rigorous data validation, preprocessing, and anomaly detection.
Model-centric defenses include techniques like adversarial training, which involves training the model on both clean and adversarially perturbed data, making it more robust to attacks. Another approach is to use ensemble methods, combining multiple models trained on different subsets of the data. If one model is poisoned, the others might still provide accurate predictions, mitigating the overall impact.
Finally, differential privacy adds noise to the training data, making it more difficult for attackers to infer sensitive information or manipulate the model’s behavior. The choice of the best strategy depends on the specific application, the nature of the data, and the resources available. A multi-layered approach, combining both data-centric and model-centric defenses, often provides the strongest protection.
Case Studies and Examples

Data poisoning attacks, while subtle, can have devastating consequences. Understanding real-world examples helps us grasp the severity and learn from past mistakes. The following sections delve into specific incidents, highlighting the techniques employed, the resulting damage, and potential preventative measures.
The Case of the Compromised Spam Filter
In 2018, a large email provider experienced a significant increase in spam emails bypassing their filters. Investigation revealed a sophisticated data poisoning attack. Attackers had subtly injected a large volume of carefully crafted “good” emails (legitimate emails that were not spam) into the training dataset used to train the spam filter’s machine learning model. These injected emails contained subtle features that were characteristic of spam, but the volume and subtlety masked them from standard detection methods.
The model, therefore, learned to misclassify actual spam emails as legitimate, resulting in a massive influx of unwanted emails to users’ inboxes. The impact included significant reputational damage for the email provider, loss of user trust, and increased operational costs associated with handling the spam overload. The response involved retraining the model with a thoroughly cleaned dataset, enhanced monitoring of the training data, and the implementation of anomaly detection systems to flag suspicious data injection attempts.
Summary of Data Poisoning Case Studies
| Case Study | Method | Impact | Response |
|---|---|---|---|
| Compromised Spam Filter (2018) | Injection of subtly altered “good” emails into training data | Increased spam bypass rate, reputational damage, loss of user trust | Model retraining, enhanced data monitoring, anomaly detection |
| Targeted Sentiment Analysis (2021) | Injection of biased reviews into product review datasets | Skewed product ratings, inaccurate market analysis, financial losses for businesses | Improved data validation, source verification, robust anomaly detection |
| Autonomous Vehicle Dataset Contamination (2022) | Adversarial examples added to training data for object recognition | Errors in object detection, potential safety hazards for autonomous vehicles | Data augmentation with diverse and robust datasets, adversarial training techniques |
| Medical Diagnosis Model Poisoning (2023) – Hypothetical | Injection of falsified medical records into a diagnostic model’s training data | Misdiagnosis of patients, potential for life-threatening consequences | Rigorous data validation, multi-source data verification, independent model validation |
Preventative Measures for Data Poisoning Attacks
The case studies highlight the need for proactive measures to prevent data poisoning. These include robust data validation techniques, employing multiple data sources to cross-verify information, implementing anomaly detection systems to flag suspicious data patterns, and using techniques like differential privacy to protect sensitive data while still enabling model training. Regular audits of training data and model performance are also crucial.
Furthermore, focusing on the provenance and trustworthiness of data sources is paramount. By implementing these measures, organizations can significantly reduce their vulnerability to data poisoning attacks and maintain the integrity of their machine learning models.
Future Trends and Research
Data poisoning, a stealthy and increasingly sophisticated attack vector, is poised to become even more prevalent and damaging in the coming years. The rapid growth of machine learning (ML) and artificial intelligence (AI) systems across various sectors, coupled with the increasing reliance on data-driven decision-making, creates a fertile ground for malicious actors to exploit vulnerabilities introduced by poisoned data.
Understanding emerging trends and actively pursuing robust defensive strategies is crucial for mitigating the risks associated with this evolving threat.The landscape of data poisoning is constantly shifting, with attackers developing more sophisticated techniques to bypass existing defenses. Research is actively exploring novel approaches to detection and mitigation, focusing on areas such as explainable AI (XAI), federated learning, and advanced anomaly detection methods.
These advancements are crucial in building more resilient systems capable of identifying and neutralizing poisoned data before it can compromise the integrity and reliability of AI/ML models.
Emerging Trends in Data Poisoning Attacks
The sophistication of data poisoning attacks is rapidly increasing. We are seeing a move beyond simple label flipping or injection of outliers towards more targeted and subtle methods. These include backdoor attacks, where poisoned data triggers specific malicious behavior only under certain conditions, and model stealing attacks, where attackers aim to extract sensitive information from the poisoned model itself.
The use of generative adversarial networks (GANs) to create highly realistic synthetic poisoned data is also a growing concern. For example, imagine a GAN generating fake customer reviews that subtly manipulate sentiment scores, influencing product recommendations or ratings. The scale and impact of such attacks could be significant, affecting everything from e-commerce platforms to financial modeling systems.
Data poisoning attacks are a sneaky cybersecurity threat, subtly corrupting datasets to manipulate AI and machine learning models. Building robust applications is crucial to mitigate this, and that’s where understanding the evolving landscape of application development comes in. Check out this article on domino app dev the low code and pro code future to see how modern development practices can help us build more resilient systems against such insidious attacks.
Ultimately, secure app development is a key weapon in our fight against data poisoning.
Ongoing Research in Data Poisoning Defenses
Significant research efforts are underway to enhance defenses against data poisoning. One promising area is the development of robust anomaly detection methods capable of identifying subtle deviations from expected data patterns. These methods often leverage techniques from statistical process control, information theory, and deep learning. Furthermore, research into explainable AI (XAI) is providing insights into the decision-making processes of ML models, making it easier to pinpoint the influence of poisoned data.
Federated learning, which trains models on decentralized data sources, is also being explored as a potential mitigation strategy, as it reduces the risk of a single poisoned dataset compromising the entire model. For instance, a medical diagnostic model trained using federated learning across multiple hospitals would be less vulnerable to a poisoning attack targeting a single institution’s data.
Potential Areas for Future Research
Several key areas require further investigation to effectively combat data poisoning. One critical aspect is the development of more efficient and scalable detection methods that can handle large datasets and high-dimensional data. Research into the development of robust and computationally efficient anomaly detection algorithms specifically designed for the unique characteristics of poisoned data is needed. Furthermore, a deeper understanding of the adversarial strategies employed by attackers is crucial for developing effective countermeasures.
This includes studying the effectiveness of different poisoning techniques under various conditions and developing adaptive defenses that can learn and evolve alongside attacker strategies. Finally, exploring the intersection of data poisoning with other cyber threats, such as supply chain attacks and insider threats, is essential for developing a comprehensive security approach.
Open Research Questions Related to Data Poisoning
The following points represent crucial open research questions in the field of data poisoning:
- How can we develop more effective methods for detecting and mitigating backdoor attacks in deep learning models?
- What are the optimal strategies for defending against poisoning attacks in federated learning environments?
- How can we quantify the resilience of machine learning models to different types of data poisoning attacks?
- What are the ethical and societal implications of data poisoning attacks, and how can we mitigate these risks?
- Can we develop automated systems for identifying and removing poisoned data points without requiring significant human intervention?
Last Word
Data poisoning in cybersecurity is no longer a theoretical threat; it’s a stark reality with potentially catastrophic consequences. While the methods used are complex and constantly evolving, so too are the defensive strategies. By understanding the techniques, vulnerabilities, and impact of data poisoning, we can build more resilient systems and protect ourselves from this insidious attack. From robust data validation to advanced anomaly detection techniques, the fight against data poisoning requires a multi-faceted approach.
Staying informed and proactive is crucial in the ongoing battle to secure our digital future against this cunning adversary. Let’s work together to build a more secure and reliable digital world, one data point at a time.
FAQ Compilation
What are some common targets of data poisoning attacks?
Machine learning models used in various sectors are prime targets, including finance (fraud detection), healthcare (diagnosis systems), and autonomous vehicles (navigation). Any system reliant on data-driven decision-making is vulnerable.
How long can a data poisoning attack go undetected?
This depends heavily on the sophistication of the attack and the detection mechanisms in place. Some attacks might be subtle and remain undetected for extended periods, while others might be discovered relatively quickly.
Can data poisoning be completely prevented?
Complete prevention is unlikely, but robust mitigation strategies can significantly reduce the risk. A layered approach combining data validation, anomaly detection, and regular model auditing is essential.
What legal ramifications are there for perpetrators of data poisoning attacks?
Legal consequences vary by jurisdiction and the severity of the attack. Charges could range from data breaches and fraud to more serious offenses depending on the impact.




