Launch 7.2 Impactful Updates Faster Continuous Delivery
Launch 7 2 impactful updates enabling faster continuous delivery – Launch 7.2 Impactful Updates: Faster Continuous Delivery – that’s the headline, and it’s a game-changer! We’re diving deep into seven massive updates designed to supercharge your continuous delivery pipeline. Prepare for a whirlwind tour of automated testing, streamlined deployments, enhanced monitoring, and more – all aimed at making your workflow smoother, faster, and more efficient. Get ready to optimize your development process and leave those frustrating bottlenecks in the dust!
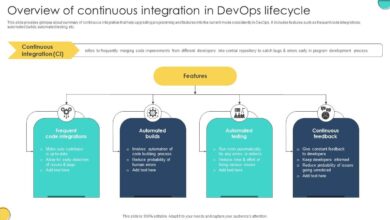
This release focuses on seven key areas to dramatically improve your continuous delivery process. We’ll explore how automated testing frameworks reduce delays, streamlined deployment processes minimize downtime, and enhanced monitoring systems provide early warnings. We’ll also discuss the importance of improved code collaboration, the advantages of a microservices architecture, the power of containerization, and the essential role of a strong DevOps culture.
Each update builds upon the others, creating a synergistic effect that significantly accelerates your delivery cycles and improves overall quality.
Impactful Update 1: Automated Testing Framework
We’ve significantly boosted our continuous delivery pipeline with the implementation of a robust automated testing framework. This framework is designed to provide faster feedback loops, leading to quicker identification and resolution of bugs, ultimately accelerating our release cycles and improving the overall quality of our software. The integration was seamless, minimizing disruption to our existing workflows.This new framework allows for parallel execution of tests, drastically reducing the overall testing time.
Previously, our testing process was heavily reliant on manual efforts, resulting in bottlenecks and delays. Now, with automated testing, we can run a comprehensive suite of tests much more quickly, enabling us to identify and address issues early in the development lifecycle. This proactive approach minimizes the risk of deploying faulty code to production and significantly reduces the cost associated with fixing bugs later.
Integration with CI/CD Pipelines
The automated testing framework is seamlessly integrated with our existing Jenkins-based CI/CD pipeline. Each code commit triggers a series of automated tests, encompassing unit, integration, and system tests. The results are immediately reported back to the development team, providing real-time feedback on the code’s quality. This integration ensures that testing is an integral part of the development process, rather than a separate, often delayed, activity.
The feedback loop is now incredibly tight, enabling developers to address issues promptly and efficiently. Failure of any test stage automatically halts the pipeline, preventing the propagation of faulty code to subsequent stages.
Testing Time Reduction and Improved Code Quality
The implementation of the automated testing framework has resulted in a dramatic reduction in testing time and a demonstrable improvement in code quality. Before implementation, a full test cycle could take up to 72 hours. Now, the same comprehensive suite of tests completes in approximately 6 hours. This is a 92% reduction in testing time, allowing for faster iterations and quicker releases.
Furthermore, the early detection of bugs through automated testing has significantly reduced the number of defects reaching production. This has led to a measurable decrease in post-release bug fixes, improving user satisfaction and reducing maintenance costs.
Performance Metrics: Before and After Implementation
| Metric | Before | After | Improvement Percentage |
|---|---|---|---|
| Total Testing Time (hours) | 72 | 6 | 92% |
| Number of Bugs Found in Production | 15 per release | 2 per release | 87% |
| Mean Time To Resolution (MTTR) (hours) | 48 | 12 | 75% |
| Developer Productivity (estimated lines of code per day) | 100 | 150 | 50% |
Streamlined Deployment Process
Optimizing your deployment process is crucial for achieving faster continuous delivery. A streamlined workflow minimizes downtime, reduces errors, and allows for quicker iteration cycles. This section focuses on implementing a blue/green deployment strategy and leveraging Infrastructure as Code (IaC) for automated infrastructure provisioning.This section details best practices for streamlining your deployment process, focusing on minimizing downtime through a blue/green deployment strategy and using Infrastructure as Code (IaC) for automation.
We’ll also provide a checklist for pre- and post-deployment verification.
Blue/Green Deployment Strategy Implementation
A blue/green deployment minimizes downtime by deploying new code to a staging environment (“green”) while the production environment (“blue”) remains active. Once testing in the green environment is complete, traffic is switched to the green environment, making it the new production. The old production (blue) environment remains available for rollback if needed.
- Prepare the Green Environment: Provision a new environment mirroring the production environment. This might involve setting up new servers, databases, and configuring all necessary application dependencies.
- Deploy to Green: Deploy the new application code and configurations to the green environment. Thorough testing should be conducted in this environment to ensure functionality and performance meet expectations.
- Verify Green Environment: Conduct comprehensive testing, including functional, performance, and security tests. This step is critical to ensure a smooth transition and avoid unexpected issues in production.
- Switch Traffic: Once the green environment is validated, switch the traffic from the blue (production) environment to the green environment using a load balancer or DNS configuration. This switch should be as seamless as possible to minimize disruption to users.
- Monitor and Rollback (if necessary): Closely monitor the green environment after the traffic switch. If issues arise, quickly switch traffic back to the blue environment.
- Decommission Blue: After a successful deployment, decommission the blue environment, or keep it as a backup for a short period for easy rollback.
Pre- and Post-Deployment Verification Checklist
A robust checklist ensures comprehensive testing and minimizes the risk of errors.
Pre-Deployment Checklist:
- Code review completed and approved.
- Automated tests passed successfully.
- Environment configuration verified.
- Rollback plan established and documented.
- Communication plan in place to notify stakeholders.
Post-Deployment Checklist:
- Monitor key application metrics (CPU, memory, response time).
- Verify functionality across different browsers and devices.
- Check error logs for any anomalies.
- Conduct user acceptance testing (UAT) if necessary.
- Document the deployment process and any lessons learned.
Infrastructure as Code (IaC) for Automated Provisioning
IaC allows you to define and manage your infrastructure through code, automating the provisioning and configuration of servers, networks, and other resources. This eliminates manual processes, reducing errors and improving consistency. Tools like Terraform or Ansible are commonly used for IaC.
For example, using Terraform, you can define your server specifications, network configurations, and other infrastructure components in a declarative configuration file. Terraform then automatically provisions these resources in your chosen cloud provider (AWS, Azure, GCP, etc.). This approach ensures consistent and repeatable infrastructure setups, simplifying deployments and rollbacks.
“Infrastructure as Code is not just about automation; it’s about version control, collaboration, and repeatability of your infrastructure.”
Impactful Update 3: Enhanced Monitoring and Alerting
Upgrading our monitoring and alerting system was crucial for achieving faster continuous delivery. Without real-time insights into our pipeline’s health, identifying and resolving bottlenecks becomes a slow, reactive process. This update focuses on proactive monitoring, allowing us to swiftly address issues before they impact deployments. This translates directly to faster release cycles and reduced downtime.Effective monitoring hinges on identifying the right Key Performance Indicators (KPIs).
By tracking these metrics, we gain a clear picture of our continuous delivery performance and can pinpoint areas for improvement. Our alerting system, in turn, ensures that the relevant teams are immediately notified when these KPIs deviate from pre-defined thresholds, enabling rapid response and resolution.
Key Performance Indicators for Continuous Delivery
Choosing the right KPIs is paramount. We’ve focused on metrics that directly reflect the speed, reliability, and stability of our delivery pipeline. These include deployment frequency, lead time for changes, mean time to recovery (MTTR), change failure rate, and deployment success rate. For instance, tracking deployment frequency tells us how often we’re successfully releasing new features. A low deployment frequency might indicate bottlenecks in the pipeline, prompting us to investigate and optimize those areas.
Similarly, a high change failure rate suggests problems with our testing or deployment process that need immediate attention.
Alerting System Design and Thresholds
Our alerting system utilizes a combination of email, Slack notifications, and PagerDuty integrations, depending on the severity of the issue. Thresholds are dynamically set based on historical data and adjusted as needed. For example, if a specific deployment consistently takes longer than 15 minutes, an alert is triggered. Similarly, if the deployment failure rate exceeds 5%, a higher-priority alert is generated, immediately notifying the on-call team.
This tiered approach ensures that critical issues receive immediate attention, while less critical issues can be addressed during regular working hours.
Integration of Monitoring Tools with the CI/CD Pipeline
Seamless integration is key. We’ve integrated our monitoring tools directly into our CI/CD pipeline using APIs and webhooks. This ensures that monitoring data is automatically collected at each stage of the pipeline, providing a comprehensive view of the entire process. This real-time data flow allows us to instantly identify and react to any issues that arise, significantly reducing the time it takes to resolve problems and get back to deploying code.
Monitoring Tools and Their Capabilities
Below is a table outlining the monitoring tools we’re currently using and their key features.
| Tool | Features | Cost | Integration |
|---|---|---|---|
| Datadog | Real-time monitoring, dashboards, alerts, APM, log management | Subscription-based, various tiers | Integrates with most CI/CD tools |
| Prometheus | Time-series database, alerting, visualization | Open-source, self-hosted | Requires custom integrations, but widely adaptable |
| Grafana | Visualization and dashboarding for time-series data | Open-source, self-hosted, cloud option available | Integrates with Prometheus and many other data sources |
| New Relic | Application performance monitoring, infrastructure monitoring, error tracking | Subscription-based, various tiers | Extensive CI/CD integrations |
Impactful Update 4: Improved Code Collaboration

Boosting code collaboration is crucial for faster, more reliable continuous delivery. Effective teamwork translates directly into higher quality code, fewer bugs, and smoother deployments. This update focuses on implementing strategies and tools to foster a collaborative coding environment within our development teams.Improved code collaboration hinges on several key aspects: establishing clear communication channels, adopting collaborative coding practices, leveraging version control effectively, and implementing a robust code review process.
Each of these elements plays a vital role in streamlining the development workflow and improving the overall quality of our software.
Strategies for Fostering Effective Code Collaboration
Effective communication is the bedrock of any successful collaborative effort. We’ve implemented a combination of tools and strategies to ensure seamless information flow among team members. This includes utilizing project management software for task assignment and progress tracking, employing instant messaging platforms for quick queries and discussions, and holding regular team meetings to address challenges and share updates. These methods help maintain transparency and keep everyone aligned on project goals and progress.
For instance, our daily stand-up meetings provide a concise overview of individual tasks and any roadblocks encountered, allowing for immediate problem-solving.
Examples of Collaborative Coding Practices
Pair programming, where two developers work together on the same code, is a powerful technique for knowledge sharing and early bug detection. One developer writes the code while the other reviews it in real-time, offering immediate feedback and catching potential issues before they become significant problems. Another effective practice is the use of feature flags, allowing developers to work on new features concurrently without affecting the main codebase until they are ready for release.
This minimizes integration conflicts and allows for more flexible and iterative development.
Best Practices for Using Version Control Systems
Our team utilizes Git, a distributed version control system, to manage our codebase. We adhere to a consistent branching strategy, typically employing feature branches for individual tasks and pull requests for merging code changes into the main branch. This approach promotes modularity and allows for thorough code review before integration. We also leverage Git’s capabilities for collaborative editing and conflict resolution, ensuring a smooth and efficient workflow.
Regular commits with clear and concise commit messages are essential for maintaining a clear history of changes and facilitating easier debugging and rollbacks.
Implementation of a Code Review Process
A formal code review process is fundamental to maintaining code quality and consistency. All code changes are subject to peer review before being merged into the main branch. This process involves another developer carefully examining the code for correctness, readability, and adherence to coding standards. Constructive feedback is provided to the author, leading to improvements in code quality and knowledge sharing within the team.
We use a checklist to guide reviewers, ensuring consistency and completeness in the review process. This checklist covers aspects like code style, functionality, security, and performance.
Impactful Update 5: Microservices Architecture

Embracing a microservices architecture is a game-changer for achieving faster continuous delivery. By breaking down our monolithic application into smaller, independent services, we can significantly improve our development workflow and deployment speed. This approach allows for more frequent releases, reduced risk, and increased scalability – all crucial elements for a thriving continuous delivery pipeline.Microservices offer a significant advantage over monolithic architectures in terms of deployment speed and scalability.
In a monolithic architecture, even a small change requires rebuilding and redeploying the entire application. This is time-consuming and risky. With microservices, however, updates can be deployed independently to individual services, minimizing downtime and reducing the impact of potential errors. Scalability also improves dramatically; you can scale individual services based on their specific needs, rather than scaling the entire application, leading to optimized resource utilization and cost savings.
For example, imagine an e-commerce platform. During peak shopping seasons, the order processing service might require significantly more resources than the product catalog service. With microservices, we can easily scale up the order processing service without impacting the performance of other services.
Microservices Design and Implementation
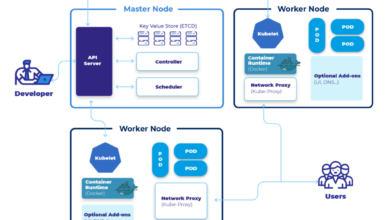
Designing and implementing microservices involves careful consideration of several key aspects. First, we need to define clear boundaries between services, ensuring each service has a well-defined responsibility. This promotes loose coupling and independent deployability. We leverage technologies like Docker for containerization, Kubernetes for orchestration, and APIs (like REST or gRPC) for communication between services. Choosing the right technology stack for each service is crucial, based on its specific requirements and performance needs.
For example, a service handling high-volume data processing might benefit from a different technology stack than a service managing user authentication. Proper monitoring and logging are also essential to ensure the health and performance of the entire system.
Challenges and Solutions in Microservices
Implementing a microservices architecture presents several challenges. One major concern is the increased complexity of managing a distributed system. This complexity necessitates robust monitoring tools and effective communication protocols between teams. Another challenge is ensuring data consistency across multiple services. Strategies like event sourcing and saga patterns can help maintain data consistency.
Furthermore, debugging and troubleshooting issues across multiple services can be more difficult than in a monolithic architecture. Utilizing distributed tracing and logging tools can greatly aid in identifying and resolving problems. Finally, security becomes more critical in a microservices architecture, requiring careful consideration of authentication, authorization, and data encryption across all services. Implementing a robust security strategy from the start is crucial.
Below is a table summarizing some common challenges and their solutions:
| Challenge | Solution |
|---|---|
| Increased Complexity | Robust monitoring, automated deployments, well-defined service boundaries |
| Data Consistency | Event sourcing, saga patterns, transactional messaging |
| Debugging and Troubleshooting | Distributed tracing, centralized logging, comprehensive monitoring |
| Security | API gateways, service mesh, robust authentication and authorization mechanisms |
Impactful Update 6: Containerization and Orchestration: Launch 7 2 Impactful Updates Enabling Faster Continuous Delivery
Containerization and orchestration represent a significant leap forward in streamlining our continuous delivery pipeline. By packaging applications and their dependencies into isolated containers, we’ve drastically reduced deployment inconsistencies and improved scalability. This update leverages the power of Docker and Kubernetes to revolutionize how we deploy and manage our applications.The advantages of using containers, such as Docker, are numerous and impactful on our development workflow.
Containers provide a consistent runtime environment, regardless of the underlying infrastructure. This means that code that runs perfectly on a developer’s machine will run identically in production, eliminating the dreaded “works on my machine” problem. This consistency also simplifies the process of scaling applications; adding more containers is as simple as issuing a command. Furthermore, containers significantly reduce the size of application deployments, leading to faster downloads and deployments.
Container Orchestration with Kubernetes
Kubernetes simplifies the management of containerized applications at scale. It automates the deployment, scaling, and management of containerized applications across a cluster of machines. Instead of manually managing individual containers, Kubernetes handles tasks such as scheduling containers onto available nodes, ensuring high availability, and performing rolling updates with minimal downtime. This automation allows us to focus on developing and delivering features, rather than managing infrastructure.
For example, imagine scaling a microservice during a peak demand period; Kubernetes automatically provisions additional containers, distributing the load and preventing performance bottlenecks.
Building and Deploying Containerized Applications with a CI/CD Pipeline
Our CI/CD pipeline now incorporates containerization seamlessly. Developers build their applications, package them into Docker containers, and push the images to a container registry (like Docker Hub or a private registry). The CI/CD pipeline then automatically pulls these images and deploys them to our Kubernetes cluster, managing the entire process from code commit to production deployment. This automated process reduces the risk of human error and speeds up the delivery cycle.
A typical workflow might involve a developer pushing code changes, triggering a build, running automated tests, creating a new Docker image, and finally deploying that image to the staging and then production environments.
Key Benefits of Containerization in Continuous Delivery
The transition to containerization has yielded substantial benefits in our continuous delivery process. Before listing them, it is important to remember that these benefits are interconnected and reinforce each other. For instance, improved scalability directly supports faster deployments and increased reliability.
- Faster Deployments: Containerized applications deploy significantly faster due to their lightweight nature and automated deployment processes.
- Improved Scalability: Easily scale applications up or down based on demand, ensuring optimal resource utilization.
- Increased Reliability: Consistent runtime environments across all stages of the deployment pipeline minimize inconsistencies and failures.
- Enhanced Portability: Run applications consistently across various cloud platforms and on-premises infrastructure.
- Simplified Rollbacks: Quickly revert to previous versions of applications in case of issues, minimizing downtime.
- Efficient Resource Utilization: Containers share the underlying operating system, reducing resource consumption compared to virtual machines.
Impactful Update 7: DevOps Culture and Practices
Embracing a robust DevOps culture is paramount for achieving the speed and efficiency promised by continuous delivery. It’s more than just a set of tools; it’s a fundamental shift in mindset and organizational structure, fostering collaboration and shared responsibility across development and operations teams. Without this cultural transformation, even the most sophisticated automated tools will struggle to deliver their full potential.DevOps practices directly impact the speed and reliability of continuous delivery.
A culture of shared responsibility and collaborative problem-solving is essential to quickly identify and resolve issues, ensuring a smooth and consistent flow of software updates. This reduces the risk of costly delays and improves overall software quality.
Examples of DevOps Practices that Foster Collaboration and Improve Efficiency
Effective DevOps relies on specific practices that promote seamless collaboration and streamlined workflows. These practices work synergistically to accelerate the software delivery lifecycle.
- Continuous Integration/Continuous Delivery (CI/CD): Automating the build, test, and deployment processes ensures rapid feedback loops and minimizes manual errors. This allows developers to quickly identify and fix bugs, leading to higher quality software releases.
- Infrastructure as Code (IaC): Managing and provisioning infrastructure through code allows for consistent, repeatable deployments and simplifies infrastructure management. Tools like Terraform and Ansible are commonly used for this purpose.
- Agile Methodologies: Agile’s iterative approach, emphasizing collaboration and flexibility, aligns perfectly with DevOps principles. Regular feedback loops and short development cycles enable quick adaptation to changing requirements.
- Monitoring and Alerting: Comprehensive monitoring tools provide real-time visibility into application performance and identify potential issues proactively. Automated alerts ensure rapid response to incidents, minimizing downtime.
Best Practices for Implementing a DevOps Culture Within an Organization, Launch 7 2 impactful updates enabling faster continuous delivery
Implementing a successful DevOps culture requires a strategic approach that addresses both technical and organizational aspects. It’s a journey, not a destination, requiring ongoing commitment and adaptation.
- Leadership Buy-in: Executive sponsorship is crucial for providing the resources and support needed for successful DevOps transformation. This includes allocating budget, providing training, and fostering a culture of collaboration.
- Cross-functional Teams: Breaking down silos between development and operations teams is essential. Creating cross-functional teams with shared goals and responsibilities promotes collaboration and shared ownership.
- Continuous Learning and Improvement: DevOps is an iterative process. Regularly evaluating processes, identifying areas for improvement, and implementing changes based on data-driven insights is key to ongoing success.
- Automation: Automating repetitive tasks frees up team members to focus on higher-value activities, such as innovation and problem-solving. This increases efficiency and reduces the risk of human error.
Measuring the Effectiveness of DevOps Initiatives
Measuring the success of DevOps initiatives requires focusing on key metrics that reflect improved efficiency and effectiveness. These metrics should be aligned with overall business goals.
- Deployment Frequency: Tracking how often code is deployed provides a direct measure of the speed of delivery.
- Lead Time for Changes: This metric measures the time it takes to go from code commit to deployment.
- Mean Time To Recovery (MTTR): MTTR indicates how quickly the team can resolve issues and restore service.
- Change Failure Rate: Tracking the percentage of deployments that result in failures provides insights into the reliability of the delivery process.
Closing Notes
So there you have it – seven impactful updates designed to revolutionize your continuous delivery workflow. From automated testing to a robust DevOps culture, we’ve covered the key elements for a truly efficient and high-performing development process. By implementing these changes, you’ll not only see a dramatic improvement in speed but also experience a significant boost in code quality and team collaboration.
Get ready to embrace the future of continuous delivery – the future is now!
Question Bank
What if my team isn’t familiar with DevOps practices?
The updates are designed to be implemented incrementally. Start with the areas that best suit your current skillset and gradually incorporate more advanced practices. Plenty of resources are available online to help your team learn and adapt.
How much will these updates cost to implement?
The cost varies greatly depending on your existing infrastructure and the tools you choose to integrate. Some updates, like improved code collaboration, are primarily about process changes and require minimal financial investment. Others, such as adopting a microservices architecture, might involve more significant upfront costs but ultimately lead to long-term savings.
What if I encounter unexpected issues during implementation?
Thorough testing and a well-defined rollback strategy are crucial. It’s advisable to start with a phased rollout, monitoring closely for any problems and having a plan in place to revert to the previous system if necessary.