
Eguide Procuring Application Security A Comprehensive Guide
Eguide procuring application security – it sounds technical, right? But think about it: every time you use an online form to request a document or submit information for a purchase, you’re interacting with an application vulnerable to security breaches. This guide dives deep into the world of securing these applications, exploring the vulnerabilities, best practices, and crucial steps needed to protect sensitive data and maintain business integrity.
We’ll unpack the complexities, demystifying the jargon and providing practical advice for anyone involved in the process, from developers to end-users.
We’ll cover everything from defining the core concepts of eguide procurement security and identifying key stakeholders to tackling common vulnerabilities, implementing robust security measures, and building a comprehensive risk mitigation plan. We’ll also explore compliance requirements, user training strategies, and creating a solid incident response plan. Get ready to bolster your eguide procurement security knowledge!
Defining “Eguide Procuring Application Security”
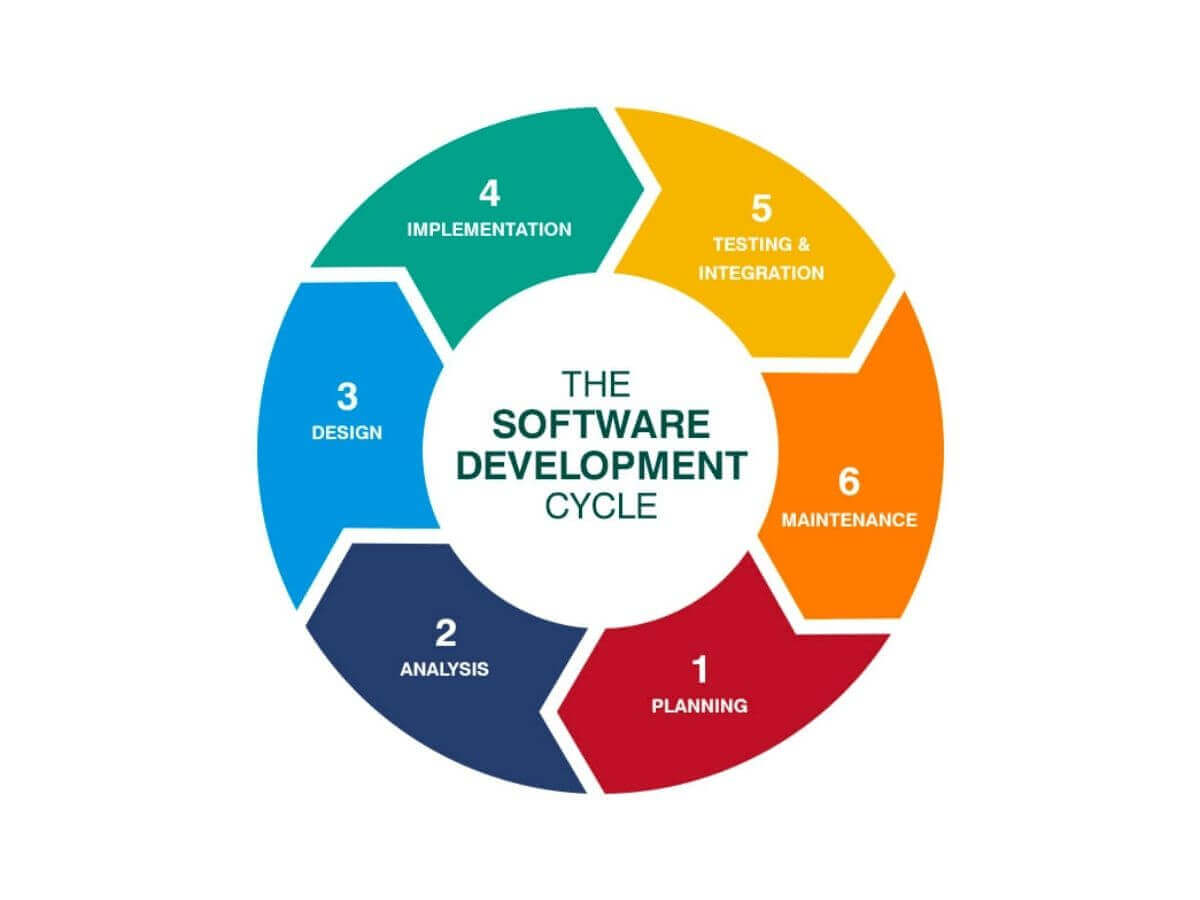
Eguide procurement, in the context of application security, refers to the process of acquiring and managing applications used to create, distribute, and manage electronic guides (eguides). This includes everything from the initial selection and implementation of the application to its ongoing maintenance and updates. Securing these applications is crucial, as they often contain sensitive information about products, services, and potentially even customer data.
A breach in these systems could lead to significant financial losses, reputational damage, and legal repercussions.Eguide procurement application security encompasses all measures taken to protect the confidentiality, integrity, and availability of these applications and the data they handle. This involves a multi-layered approach, incorporating technical safeguards, security policies, and employee training.
Key Challenges in Securing Eguide Procurement Applications, Eguide procuring application security
Securing applications used for eguide procurement presents several unique challenges. One major challenge is the diverse range of technologies involved. Eguide applications might integrate with various systems, such as content management systems (CMS), learning management systems (LMS), and customer relationship management (CRM) systems, each with its own security vulnerabilities. Another challenge is the evolving threat landscape. New vulnerabilities are constantly being discovered, requiring continuous monitoring and patching.
Furthermore, the increasing reliance on cloud-based solutions introduces additional security concerns related to data privacy, access control, and vendor responsibility. Finally, ensuring compliance with relevant regulations and industry best practices, such as GDPR or HIPAA, adds another layer of complexity.
Stakeholders and Their Security Responsibilities
Several stakeholders play critical roles in ensuring the security of eguide procurement applications. These include:
- Application Developers: Responsible for building secure applications from the ground up, incorporating security best practices throughout the software development lifecycle (SDLC).
- Procurement Managers: Responsible for selecting secure applications and negotiating appropriate security clauses in vendor contracts.
- IT Security Teams: Responsible for implementing and maintaining security controls, monitoring for threats, and responding to incidents.
- End-Users: Responsible for following security policies and reporting any suspicious activity.
- Vendors: Responsible for providing secure applications and maintaining their security over time.
Comparison of Eguide Procurement Methods and Associated Security Risks
Different methods exist for procuring eguide applications, each with its own security implications. The following table compares some common methods:
| Procurement Method | Security Risks | Mitigation Strategies | Cost |
|---|---|---|---|
| In-house Development | Potential for security flaws due to limited expertise, higher initial development costs. | Thorough security testing, adherence to secure coding practices, continuous monitoring. | High |
| Off-the-Shelf Software | Vulnerabilities in existing code, reliance on vendor for security updates. | Careful vendor selection, regular security audits, patching and updates. | Medium |
| Cloud-Based Solution | Data breaches, vendor lock-in, reliance on third-party security. | Due diligence in vendor selection, robust access controls, data encryption. | Medium to High |
| Custom SaaS Solution | Similar to cloud-based solutions but with more tailored functionality, potentially reducing some risks if security is a primary focus in the development contract. | Strong service level agreements (SLAs) focusing on security, regular security assessments, data encryption. | High |
Vulnerabilities in Eguide Procurement Applications
E-guide procurement applications, while streamlining the purchasing process, introduce new security risks if not carefully designed and implemented. These systems often handle sensitive financial and contractual data, making them prime targets for malicious actors. Understanding the common vulnerabilities and their potential impact is crucial for building secure and resilient applications.
SQL Injection
SQL injection attacks exploit vulnerabilities in how applications handle user inputs. Malicious code inserted into input fields can manipulate database queries, potentially leading to data breaches, unauthorized access, or even complete system compromise. For example, an attacker might inject malicious SQL code into a search field, allowing them to retrieve sensitive pricing information or even modify purchase orders.
The impact could be significant, ranging from financial losses due to fraudulent orders to reputational damage from a data breach. Attackers leverage this by crafting malicious SQL statements that are then executed by the application’s database.
Cross-Site Scripting (XSS)
Cross-site scripting (XSS) vulnerabilities allow attackers to inject malicious scripts into web pages viewed by other users. In an e-guide procurement application, this could allow an attacker to steal session cookies, redirect users to phishing sites, or modify the application’s functionality. Imagine a scenario where an attacker injects a script into a product description field. When a user views that description, the script executes, potentially stealing their credentials.
This leads to unauthorized access to sensitive data and potentially fraudulent activities. Attackers often use this to steal session tokens or deploy malware.
Broken Authentication and Session Management
Weak or improperly implemented authentication and session management mechanisms are frequent vulnerabilities. Attackers can exploit these weaknesses to gain unauthorized access to the system, potentially viewing, modifying, or deleting sensitive data. For example, a lack of robust password policies or the absence of multi-factor authentication could allow attackers to easily guess or brute-force passwords. The consequences include data theft, unauthorized purchases, and manipulation of contracts.
Attackers might use credential stuffing, brute-force attacks, or session hijacking techniques.
Insecure Data Storage
Storing sensitive data, such as financial information or contract details, without proper encryption or access controls poses significant risks. If an attacker gains access to the database, they could easily steal this information. For instance, storing credit card numbers without encryption makes them vulnerable to theft. This could lead to significant financial losses and legal liabilities for the organization.
Attackers could exploit vulnerabilities in the database or application to gain access to sensitive data.
Security Checklist for Developers
Before deploying an e-guide procurement application, developers should perform a thorough security review. A comprehensive checklist should include:
- Input Validation and Sanitization: Implement robust input validation and sanitization to prevent SQL injection and XSS attacks.
- Secure Authentication and Authorization: Use strong authentication mechanisms, including multi-factor authentication, and implement role-based access control.
- Data Encryption: Encrypt sensitive data both in transit and at rest.
- Regular Security Audits and Penetration Testing: Conduct regular security audits and penetration testing to identify and address vulnerabilities.
- Secure Coding Practices: Follow secure coding practices to minimize the risk of introducing vulnerabilities.
- Regular Software Updates: Keep all software components up-to-date with the latest security patches.
- Robust Logging and Monitoring: Implement robust logging and monitoring to detect and respond to security incidents.
Security Best Practices for Eguide Procurement
Securing eguide procurement applications requires a multi-layered approach encompassing robust authentication, authorization, data encryption, and secure coding practices. Ignoring these best practices can lead to significant financial losses, reputational damage, and legal repercussions. This section Artikels a practical guide to fortifying your eguide procurement system.
Authentication and Authorization Mechanisms
Implementing strong authentication is paramount. Weak passwords are a common entry point for attackers. We should enforce strong password policies, including minimum length requirements, complexity rules (uppercase, lowercase, numbers, symbols), and regular password changes. Multi-factor authentication (MFA), such as using one-time passwords (OTPs) or biometric verification, adds an extra layer of security, significantly reducing the risk of unauthorized access.
Authorization controls ensure that only authenticated users have access to the appropriate resources. The principle of least privilege should be strictly adhered to, granting users only the necessary permissions to perform their tasks. Role-based access control (RBAC) is a practical method to manage these permissions effectively.
Data Encryption at Rest and in Transit
Protecting sensitive data is crucial. All data, both at rest (stored on databases or servers) and in transit (being transmitted over a network), should be encrypted. For data at rest, strong encryption algorithms like AES-256 should be used. For data in transit, HTTPS should always be enabled, ensuring that all communication between the client and the server is encrypted using TLS/SSL protocols.
Regular security audits and penetration testing are necessary to identify and address vulnerabilities.
Secure Coding Practices
Secure coding is an essential aspect of application security. Developers should follow secure coding guidelines to prevent common vulnerabilities like SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF). Input validation is crucial; all user inputs should be sanitized and validated before being used in any database queries or other operations. Regular code reviews and security testing are necessary to identify and fix vulnerabilities early in the development process.
Using a secure coding framework or style guide can improve code quality and security.
Security Technologies and Frameworks
Several security technologies and frameworks can enhance the security of eguide procurement applications. Web Application Firewalls (WAFs) can filter malicious traffic and protect against common web attacks. Intrusion Detection/Prevention Systems (IDS/IPS) can monitor network traffic for suspicious activity. Security Information and Event Management (SIEM) systems can collect and analyze security logs from various sources, providing valuable insights into potential threats.
Consider using established frameworks like OWASP (Open Web Application Security Project) and NIST (National Institute of Standards and Technology) guidelines to build secure applications.
Step-by-Step Implementation Guide
1. Conduct a thorough security assessment
Identify existing vulnerabilities and potential risks.
2. Implement strong authentication and authorization
Enforce strong password policies and use MFA. Implement RBAC.
3. Encrypt all sensitive data
Use AES-256 for data at rest and HTTPS for data in transit.
4. Implement secure coding practices
Validate all user inputs and follow secure coding guidelines.
5. Deploy security technologies
Use WAFs, IDS/IPS, and SIEM systems to enhance security.
6. Regularly monitor and update security
Conduct penetration testing and security audits. Keep software and security technologies updated.
7. Develop an incident response plan
Define procedures to handle security incidents effectively.
Risk Assessment and Mitigation Strategies
Protecting your eGuide procurement application requires a proactive approach to risk management. A thorough risk assessment identifies potential threats and vulnerabilities, allowing you to prioritize mitigation strategies and build a robust security posture. This process is crucial for minimizing financial losses, reputational damage, and legal liabilities.
Key Security Risks in Eguide Procurement Applications
Eguide procurement applications face a unique set of security risks. These risks stem from the application’s functionality, the data it handles, and the potential attack vectors it presents. Failing to adequately address these risks can lead to significant consequences.
- Data breaches: Unauthorized access to sensitive data, such as pricing information, contract details, and user credentials, can result in financial losses, legal repercussions, and reputational damage. A successful breach could expose confidential business strategies and compromise negotiations.
- Denial-of-service (DoS) attacks: Overwhelming the application with traffic can render it inaccessible to legitimate users, disrupting the procurement process and causing significant operational disruptions. This can halt eGuide purchasing and negatively impact business operations.
- Injection attacks (SQL injection, cross-site scripting): Malicious code injected into the application can compromise data integrity, steal sensitive information, or allow attackers to take control of the system. Successful injection attacks can lead to complete system compromise.
- Malware infections: Malicious software can infect the application or the underlying infrastructure, potentially stealing data, disrupting operations, or causing further damage. This could range from ransomware attacks to data exfiltration.
- Insider threats: Malicious or negligent insiders can compromise the security of the application by abusing their access privileges or failing to follow security protocols. Insider threats are often difficult to detect and mitigate.
Methods for Conducting a Thorough Risk Assessment
A robust risk assessment involves a systematic process of identifying, analyzing, and prioritizing potential threats and vulnerabilities. This process should be conducted regularly to account for evolving threats and changes in the application or its environment.
A common methodology involves using a combination of qualitative and quantitative methods. Qualitative methods, such as expert interviews and vulnerability assessments, provide a high-level understanding of potential risks. Quantitative methods, such as risk scoring and probability analysis, assign numerical values to risks, enabling prioritization based on their potential impact and likelihood.
The process should include:
- Asset identification: Catalog all valuable assets within the eGuide procurement application, including data, software, and hardware.
- Threat identification: Identify potential threats that could target these assets, considering both internal and external sources.
- Vulnerability identification: Determine vulnerabilities within the application and its infrastructure that could be exploited by identified threats.
- Risk analysis: Evaluate the likelihood and potential impact of each identified risk. This often involves assigning a risk score based on a combination of likelihood and impact.
- Risk prioritization: Rank risks based on their scores, focusing mitigation efforts on the highest-priority risks first.
Mitigation Strategies for Identified Risks
Once risks are identified and prioritized, appropriate mitigation strategies should be implemented. These strategies should aim to reduce the likelihood and/or impact of each risk.
The following mitigation strategies address the risks Artikeld above:
- Data breaches: Implement robust access controls, data encryption, and regular security audits. Employ multi-factor authentication and intrusion detection systems.
- Denial-of-service attacks: Implement DDoS mitigation techniques, such as rate limiting and content filtering. Utilize a cloud-based infrastructure for scalability and redundancy.
- Injection attacks: Use parameterized queries and input validation to prevent injection attacks. Regularly update the application and its underlying libraries.
- Malware infections: Implement antivirus and anti-malware solutions. Regularly patch the application and operating system. Conduct regular security scans and penetration testing.
- Insider threats: Implement strong access controls, including least privilege access. Conduct regular security awareness training for employees. Monitor user activity for suspicious behavior.
Risk Mitigation Plan
A comprehensive risk mitigation plan Artikels the responsibilities and timelines for implementing the chosen mitigation strategies. This plan should be regularly reviewed and updated to reflect changes in the threat landscape and the application itself.
Example Risk Mitigation Plan:
| Risk | Mitigation Strategy | Responsible Party | Timeline |
|---|---|---|---|
| Data Breach | Implement data encryption and multi-factor authentication | IT Security Team | Within 3 months |
| DoS Attack | Implement DDoS mitigation service | Network Administrator | Within 6 months |
| SQL Injection | Conduct security code review and implement parameterized queries | Development Team | Within 1 month |
Compliance and Regulatory Requirements
Navigating the complex world of eGuide procurement application security necessitates a thorough understanding of relevant compliance standards and regulations. Failure to adhere to these guidelines can lead to significant legal and financial repercussions, damaging your organization’s reputation and potentially exposing sensitive data. This section Artikels key regulations, the consequences of non-compliance, and strategies for ensuring your eGuide procurement applications are compliant.
EGuide procurement applications often handle sensitive data, including personal information, financial details, and intellectual property. This makes them prime targets for cyberattacks, and stringent regulatory frameworks exist to protect this data. The severity of non-compliance penalties varies depending on the jurisdiction and the specific regulation violated, but they can range from hefty fines and legal action to reputational damage and loss of customer trust.
Proactive compliance is crucial for mitigating these risks.
Relevant Regulations and Standards
Compliance hinges on understanding and adhering to applicable regulations. For example, the General Data Protection Regulation (GDPR) in Europe dictates strict rules around the processing of personal data, including data security measures. In the United States, the Health Insurance Portability and Accountability Act (HIPAA) governs the security of protected health information (PHI) if your eGuide procurement system handles such data.
The California Consumer Privacy Act (CCPA) and similar state-level regulations impose specific requirements on the handling of consumer data. Payment Card Industry Data Security Standard (PCI DSS) applies if your system processes credit card information. Finally, industry-specific regulations may also apply, depending on your sector. Each of these regulations mandates specific security controls, data protection measures, and incident reporting procedures.
Implications of Non-Compliance
Non-compliance with these regulations can result in severe consequences. Financial penalties can be substantial, running into millions of dollars depending on the severity of the violation and the amount of data compromised. Legal action, including lawsuits from affected individuals or regulatory bodies, is a significant possibility. Reputational damage can severely impact your organization’s standing with customers, partners, and investors, leading to loss of business and decreased market value.
Furthermore, non-compliance can expose your organization to increased cyber risk, potentially leading to data breaches, system disruptions, and the theft of valuable intellectual property. A proactive approach to compliance is essential to mitigate these risks and protect your organization.
Ensuring Compliance in EGuide Procurement Applications
Achieving and maintaining compliance requires a multi-faceted approach. This involves implementing robust security controls throughout the application lifecycle, from design and development to deployment and maintenance. Regular security assessments, including vulnerability scanning and penetration testing, are crucial for identifying and addressing weaknesses. Employee training programs on security best practices and data protection are also vital. Furthermore, a comprehensive incident response plan is necessary to handle security breaches effectively and minimize their impact.
Establishing a formal data governance framework, including clear data retention policies and access controls, is critical for maintaining compliance. Finally, ongoing monitoring and auditing are essential to ensure the effectiveness of your security controls and your continued compliance with relevant regulations.
Security Audits and Penetration Testing Procedures
Regular security audits and penetration testing are indispensable components of a robust compliance program. Security audits provide an independent assessment of your security posture against established standards and regulations. These audits typically involve a review of your security policies, procedures, and controls, as well as an assessment of your infrastructure and applications. Penetration testing simulates real-world attacks to identify vulnerabilities in your eGuide procurement system.
This involves ethical hackers attempting to breach your system’s security, identifying weaknesses that could be exploited by malicious actors. Both security audits and penetration testing should be conducted regularly and by qualified professionals to ensure comprehensive coverage and accurate identification of potential vulnerabilities. The results of these assessments should be used to inform remediation efforts and strengthen your overall security posture.
Examples of penetration testing methodologies include black-box testing (where testers have no prior knowledge of the system), white-box testing (where testers have full knowledge of the system), and grey-box testing (a combination of both).
Incident Response and Recovery
A robust incident response plan is crucial for minimizing the damage caused by security breaches in eguide procurement systems. Such a plan should Artikel clear procedures for identifying, containing, and remediating security incidents, ultimately leading to faster recovery and improved system resilience. Failing to prepare adequately can result in significant financial losses, reputational damage, and legal repercussions.
Incident Response Plan Development
Creating a comprehensive incident response plan requires a structured approach. This involves identifying potential threats and vulnerabilities specific to the eguide procurement system, defining roles and responsibilities for each team member involved in the response, and establishing clear communication channels. Regular testing and updates are essential to ensure the plan remains effective and relevant to evolving threats. The plan should detail specific procedures for different types of incidents, including data breaches, malware infections, and denial-of-service attacks.
It should also include a communication plan for notifying stakeholders, such as customers, regulatory bodies, and internal teams. Finally, the plan should Artikel a process for post-incident review and improvement.
Incident Identification, Containment, and Remediation
The process begins with the detection of a security incident, which may be triggered by security monitoring systems, user reports, or external notifications. Once an incident is identified, the immediate priority is containment, limiting the scope and impact of the breach. This might involve isolating affected systems, disabling user accounts, or blocking malicious traffic. Remediation follows containment and involves addressing the root cause of the incident.
This could involve patching vulnerabilities, removing malware, restoring data from backups, and implementing stronger security controls. Throughout this process, meticulous documentation is vital for tracking actions taken and lessons learned.
Post-Incident Review
A thorough post-incident review is critical for continuous improvement. This involves analyzing the incident to understand what happened, why it happened, and how it could have been prevented or mitigated more effectively. The review should identify gaps in existing security measures, evaluate the effectiveness of the incident response plan, and recommend improvements to security policies, procedures, and technologies. This iterative process helps organizations strengthen their security posture and reduce their vulnerability to future attacks.
For example, a post-incident review might reveal a weakness in password policies, leading to the implementation of stronger password requirements and multi-factor authentication.
Incident Response Process Flowchart
┌───────────────┐
│ Incident │
│ Detection │
└───────────────┘
│
▼
┌───────────────┐
│ Initial │
│ Assessment │
└───────────────┘
│
▼
┌───────────────┐
│ Containment │
│ & Isolation │
└───────────────┘
│
▼
┌───────────────┐
│ Eradication │
│ & Remediation │
└───────────────┘
│
▼
┌───────────────┐
│ Recovery │
│ & Restoration │
└───────────────┘
│
▼
┌───────────────┐
│ Post-Incident │
│ Review │
└───────────────┘
│
▼
┌───────────────┐
│ Lessons Learned│
│ & Improvements │
└───────────────┘
Closing Notes

Securing eguide procurement applications isn’t just about ticking boxes; it’s about building a robust, multi-layered defense against potential threats. By understanding the vulnerabilities, implementing best practices, and fostering a culture of security awareness, organizations can significantly reduce their risk exposure and protect valuable data. This guide provides a roadmap to achieve this, empowering you to navigate the complexities of eguide procurement security with confidence and create a safer digital environment for everyone involved.
Commonly Asked Questions: Eguide Procuring Application Security
What are the biggest risks associated with insecure eguide procurement applications?
Data breaches leading to financial loss, reputational damage, legal penalties, and disruption of business operations are major risks. Compromised systems can also expose sensitive personal information, violating privacy regulations.
How often should security audits and penetration testing be conducted?
The frequency depends on the criticality of the application and the regulatory requirements. However, annual penetration testing and regular security audits (at least semi-annually) are generally recommended.
What is the role of user training in eguide procurement security?
User training is crucial. Educated users are less likely to fall victim to phishing attacks or make security mistakes. Training should cover safe password practices, recognizing phishing emails, and reporting suspicious activity.
What are some examples of common eguide procurement application vulnerabilities?
SQL injection, cross-site scripting (XSS), cross-site request forgery (CSRF), insecure authentication mechanisms, and insufficient authorization are common vulnerabilities.




