CompTIA Offers Certification to Evaluate Cyber Threats Detecting Skills
CompTIA offers certification to evaluate cyber threats detecting skills, a crucial aspect of today’s digital landscape. This certification isn’t just about memorizing facts; it’s about developing the practical skills needed to identify, analyze, and respond to real-world cyber threats. We’ll explore the different CompTIA certifications available, the skills they assess, and how they can boost your cybersecurity career.
Get ready to dive into the world of threat detection and discover how CompTIA can help you become a valuable asset in the fight against cybercrime.
This post will cover the various CompTIA certifications focused on cyber threat detection, comparing their strengths and weaknesses. We’ll delve into the exam formats, crucial skills assessed, effective study strategies, and ultimately, how these certifications translate into real-world career advantages. We’ll also touch upon how CompTIA stacks up against other prominent cybersecurity certifications.
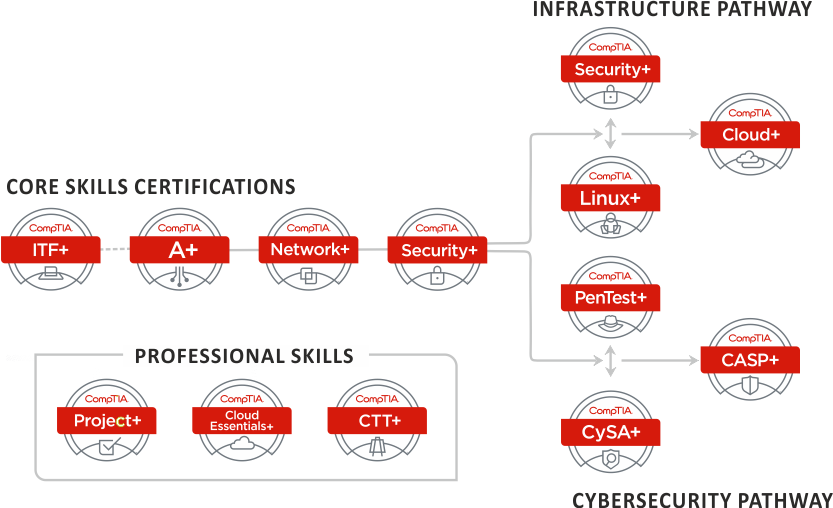
CompTIA Certifications Overview
CompTIA offers a range of certifications valuable for individuals seeking to establish or advance their careers in cybersecurity. These certifications are vendor-neutral, meaning they aren’t tied to specific products or technologies, making them widely applicable across various organizations and industries. This broad applicability is particularly beneficial in the field of cyber threat detection, where familiarity with diverse systems and approaches is crucial.CompTIA certifications relevant to cyber threat detection provide a structured pathway for professionals to demonstrate their knowledge and skills.
The certifications build upon each other, allowing individuals to progress from foundational concepts to more advanced and specialized areas. This progressive structure caters to both entry-level and experienced professionals aiming to enhance their threat detection capabilities.
CompTIA Certification Comparison for Threat Detection
Several CompTIA certifications focus on different aspects of cybersecurity, with varying degrees of emphasis on threat detection. Understanding these differences is key to choosing the right certification path. The core certifications relevant to threat detection are Security+, CySA+, and CASP+. Security+ provides a foundational understanding of cybersecurity concepts, while CySA+ delves deeper into security analysis, and CASP+ focuses on advanced security architecture and incident response.
CompTIA Certification Threat Detection Focus Areas, Comptia offers certification to evaluate cyber threats detecting skills
The following table compares these certifications and their respective threat detection focus areas:
| Certification | Level | Threat Detection Focus | Key Skills |
|---|---|---|---|
| Security+ | Foundational | Basic threat identification, security awareness, network security fundamentals. | Network security concepts, cryptography basics, risk management, incident response fundamentals. |
| CySA+ | Intermediate | Security analysis, threat hunting, incident response, security monitoring. | Security information and event management (SIEM), intrusion detection/prevention systems (IDS/IPS), malware analysis, vulnerability assessment. |
| CASP+ | Advanced | Advanced threat hunting, incident response management, risk mitigation, security architecture design. | Advanced security architecture, incident handling, cryptography, risk management, cloud security. |
Cyber Threat Detection Skillsets Assessed

CompTIA certifications, particularly those focused on cybersecurity, rigorously evaluate a candidate’s ability to identify, analyze, and respond to a wide range of cyber threats. These exams aren’t just about memorizing definitions; they demand practical application of knowledge and critical thinking skills vital in real-world security scenarios. The assessments focus on the skills needed to effectively protect systems and data from increasingly sophisticated attacks.The specific skills assessed vary slightly depending on the certification level (e.g., Security+, CySA+, CASP+), but common themes include understanding threat vectors, analyzing security logs, identifying malware, and implementing incident response procedures.
Successful candidates demonstrate a comprehensive understanding of security concepts and the ability to apply that knowledge to practical problem-solving.
Threat Identification and Analysis
This section of the exams focuses on a candidate’s ability to identify various types of cyber threats. This goes beyond simply recognizing known malware signatures. Candidates are tested on their ability to analyze network traffic, identify suspicious patterns, and correlate seemingly disparate events to uncover a larger threat. For example, an exam question might present a series of network logs showing unusual outbound connections, failed login attempts, and unusual data transfers.
The candidate would need to analyze these logs, determine the potential threat, and explain the steps to further investigate. This involves understanding different attack vectors (e.g., phishing, malware, denial-of-service attacks), recognizing indicators of compromise (IOCs), and utilizing various security tools to investigate further.
Security Log Analysis and Interpretation
Analyzing security logs is a critical skill for any cybersecurity professional. CompTIA certifications assess a candidate’s ability to effectively sift through large volumes of log data to identify security incidents. This includes understanding different log formats (e.g., syslog, Windows Event Logs), identifying key events indicating malicious activity, and correlating events from multiple sources to reconstruct the timeline of an attack.
A typical scenario might involve examining web server logs to identify unauthorized access attempts, database logs to detect data breaches, and firewall logs to pinpoint suspicious network connections. The candidate needs to not only identify the suspicious activity but also understand the context and potential impact.
Malware Analysis and Response
Understanding malware and how to respond to an infection is another crucial area. CompTIA certifications evaluate a candidate’s knowledge of different malware types (viruses, worms, trojans, ransomware), their infection mechanisms, and the methods used to detect and remove them. This might involve analyzing malware samples in a sandboxed environment, identifying malicious code, and understanding the techniques used to evade detection.
A hypothetical exam scenario could present a situation where a system is infected with ransomware. The candidate would need to explain the steps to contain the infection, recover the affected data, and prevent future attacks. This includes understanding the importance of backups, incident response procedures, and the use of anti-malware tools.
Incident Response and Remediation
Effective incident response is paramount. CompTIA certifications assess the candidate’s ability to handle security incidents using established best practices and frameworks (e.g., NIST Cybersecurity Framework). This involves understanding the different phases of incident response (preparation, identification, containment, eradication, recovery, lessons learned), the importance of maintaining proper documentation, and the legal and ethical considerations involved. A scenario might involve a data breach where sensitive customer information has been compromised.
The candidate would need to explain the steps to contain the breach, notify affected parties, and implement measures to prevent future incidents. This includes understanding the importance of forensic analysis, legal requirements (e.g., data breach notification laws), and the need for effective communication.
Hypothetical Exam Scenario
Imagine a scenario where a company’s network experiences a sudden surge in network traffic, accompanied by multiple failed login attempts targeting administrative accounts. Security logs reveal unusual outbound connections to a known command-and-control server associated with a sophisticated botnet. The candidate would need to:
- Identify the potential threat (botnet infection).
- Analyze the security logs to pinpoint the compromised systems.
- Implement containment measures (e.g., isolating infected systems, blocking malicious network traffic).
- Eradicate the malware from the affected systems.
- Restore data from backups.
- Implement preventative measures to avoid future attacks.
This scenario tests multiple skillsets, including log analysis, threat identification, incident response, and malware remediation. The ability to systematically approach the problem and demonstrate a clear understanding of best practices is crucial.
Exam Format and Content
CompTIA’s cybersecurity certifications, particularly those focused on threat detection, are designed to rigorously assess a candidate’s practical skills and knowledge. The exams aren’t just theoretical; they aim to simulate real-world scenarios and challenge your ability to apply learned concepts effectively. Understanding the exam format and content is crucial for effective preparation.The CompTIA exams typically follow a multiple-choice format, although some may include performance-based questions.
These performance-based items often require you to actively solve problems within a simulated environment, mimicking the tasks you’d encounter in a real-world security role. This approach emphasizes practical application over rote memorization.
Question Types and Cognitive Skills
CompTIA exams utilize various question types to evaluate a broad range of cognitive skills. Multiple-choice questions assess your understanding of concepts and your ability to apply them. These questions might present a scenario and ask you to identify the most appropriate course of action, or they might test your knowledge of specific security protocols or technologies. Performance-based questions, on the other hand, evaluate your problem-solving skills and your ability to apply your knowledge in a practical context.
For example, you might be asked to analyze network traffic logs to identify malicious activity or configure security settings within a virtual environment. These questions require a deeper level of understanding and the ability to apply learned concepts in a hands-on manner. In essence, the exams aim to gauge not only your theoretical knowledge but also your practical skills and analytical abilities.
Common Topics Covered
The specific topics covered vary slightly depending on the specific CompTIA certification, but several common themes consistently appear. A thorough understanding of these areas is essential for success.
- Network Security Fundamentals: This includes topics such as TCP/IP, subnetting, network topologies, and common network security protocols (e.g., IPsec, TLS/SSL).
- Security Concepts and Principles: A solid grasp of core security principles, including risk management, access control, cryptography, and incident response methodologies is vital.
- Threat Detection Techniques: Understanding various threat detection methods, such as signature-based detection, anomaly detection, and behavioral analysis, is key. This also includes knowledge of different security information and event management (SIEM) systems.
- Security Tools and Technologies: Familiarity with various security tools and technologies, including intrusion detection/prevention systems (IDS/IPS), firewalls, and endpoint detection and response (EDR) solutions, is essential.
- Incident Response and Forensics: The ability to handle security incidents effectively, including containment, eradication, recovery, and post-incident analysis, is a critical skill.
- Vulnerability Management: Understanding vulnerability assessment methodologies, penetration testing, and the importance of patching and remediation is crucial.
- Log Analysis and Threat Hunting: The ability to analyze security logs to identify malicious activity and proactively hunt for threats is a highly valued skill.
Preparing for CompTIA Cyber Threat Detection Certifications
Passing the CompTIA Cyber Threat Intelligence (CyTI) or other related certifications requires dedicated effort and a strategic approach. Success hinges on a solid understanding of core concepts, coupled with significant hands-on practice. This section Artikels effective study strategies and resources to help you prepare.Effective Study Strategies and ResourcesA multi-faceted approach is key to mastering the material. This includes leveraging official CompTIA resources, exploring supplementary learning materials, and engaging in practical exercises.
The official CompTIA study guides provide a structured learning path, covering all exam objectives. These guides often include practice questions and simulated exams to gauge your understanding. Supplementing this with online courses, such as those offered by Udemy, Coursera, or Cybrary, can provide alternative perspectives and additional practice. Remember to focus on understanding the underlying concepts, rather than just memorizing facts.
The Importance of Hands-on Experience and Practical Exercises
Theoretical knowledge alone is insufficient for success in cybersecurity certifications. The CompTIA Cyber Threat Detection exams emphasize practical skills. Hands-on experience is crucial for developing the intuition and problem-solving abilities needed to identify and analyze threats effectively. This practical experience can be gained through various avenues, including setting up virtual labs, participating in Capture The Flag (CTF) competitions, and working on personal cybersecurity projects.
So you’re looking to boost your cyber threat detection skills? CompTIA offers certifications to prove your expertise, which is super valuable in today’s landscape. Understanding cloud security is key, and that’s where bitglass and the rise of cloud security posture management becomes relevant; a solid grasp of cloud security tools and strategies complements your CompTIA cert, making you a much stronger candidate in the job market.
Ultimately, CompTIA’s certifications help validate your abilities to identify and mitigate threats, whether they originate from the cloud or elsewhere.
CTFs, for example, simulate real-world scenarios, forcing you to apply your knowledge to solve complex problems under pressure. Building a home lab allows for experimentation with different security tools and techniques in a safe environment, replicating the experience of a real-world network environment.
Sample Study Plan
A structured study plan is essential for efficient learning. The following is a sample plan, adaptable to individual needs and learning styles. Remember to adjust the time allocation based on your prior knowledge and learning pace.
| Week | Topic | Time Allocation |
|---|---|---|
| 1 | Network Fundamentals, TCP/IP, OSI Model | 10 hours |
| 2 | Threat Landscape, Attack Vectors, Malware Analysis | 12 hours |
| 3 | Security Information and Event Management (SIEM), Log Analysis | 10 hours |
| 4 | Incident Response, Forensics, Threat Hunting | 12 hours |
| 5 | Security Monitoring Tools, Cloud Security, Threat Intelligence | 10 hours |
| 6 | Practice Exams, Review Weak Areas | 15 hours |
This sample plan allocates approximately 60 hours of study time across six weeks. This is a guideline; adjust the schedule to fit your availability and learning pace. Consistent, focused study sessions are more effective than sporadic cramming. Regular breaks and sufficient rest are also vital for optimal learning and retention. Remember to incorporate hands-on practice throughout the study period, applying what you learn in practical scenarios.
For instance, after learning about SIEM, spend time analyzing sample logs from a virtual environment. After studying malware analysis techniques, practice analyzing benign and malicious samples in a sandbox environment. This active learning approach is significantly more effective than passive reading.
Career Implications and Industry Recognition

Earning a CompTIA Cybersecurity certification, particularly in threat detection, significantly boosts your career prospects in the ever-expanding cybersecurity field. These certifications demonstrate a validated skillset highly sought after by employers, providing a competitive edge in a rapidly evolving job market. The value extends beyond simply having a certificate; it represents a commitment to professional development and a proven understanding of critical security concepts.The value of CompTIA certifications to employers lies in their industry recognition and the standardized assessment of competency.
Unlike internal training programs or self-claimed expertise, a CompTIA certification offers a third-party validation of skills, reducing the risk associated with hiring. Employers can confidently rely on certified individuals to possess the necessary knowledge and abilities to contribute effectively to their security teams. This translates to increased efficiency, reduced security incidents, and improved overall organizational security posture.
Job Roles Valued by CompTIA Cyber Threat Detection Certifications
CompTIA certifications in cyber threat detection are highly valued across a range of cybersecurity roles. These certifications provide a solid foundation for entry-level positions and enhance the credentials of experienced professionals seeking advancement.The practical, hands-on skills assessed by the CompTIA exams are directly applicable to various job functions. This translates into a demonstrable return on investment for employers who prioritize hiring certified individuals.
So, CompTIA offers certifications to really test your mettle when it comes to spotting cyber threats. It’s a tough but rewarding path, especially considering how crucial cybersecurity is becoming in today’s world. Building secure applications is equally vital, which is why I’ve been researching domino app dev, the low-code and pro-code future , to see how development practices are evolving.
Ultimately, though, strong cybersecurity skills, as validated by CompTIA certifications, remain a cornerstone of any secure system.
The resulting improvement in security posture and reduced risk of breaches directly impacts the bottom line.
Examples of roles where these certifications are highly valued include:
- Security Analyst: A security analyst with a CompTIA Cyber Threat Detection certification is better positioned to identify, analyze, and respond to security incidents, reducing the impact of cyberattacks.
- Threat Hunter: The certification provides a strong foundation in the techniques and methodologies required for proactive threat hunting, allowing certified individuals to identify and mitigate threats before they cause damage.
- Incident Responder: A CompTIA certification demonstrates the skills needed to effectively handle security incidents, including containment, eradication, recovery, and post-incident analysis.
- Security Engineer: Security engineers benefit from the detailed understanding of network security and threat detection principles offered by the certification, allowing them to design and implement more robust security systems.
- SOC Analyst (Security Operations Center Analyst): The certification enhances the skills of SOC analysts in monitoring, detecting, and responding to security events, ensuring the effective operation of the organization’s security infrastructure.
Comparison with Other Cybersecurity Certifications
Choosing the right cybersecurity certification can feel overwhelming, given the sheer number of options available. CompTIA’s offerings, while valuable, aren’t the only game in town. This section compares CompTIA certifications with other prominent certifications from organizations like (ISC)² and SANS, highlighting their relative strengths and weaknesses to help you make an informed decision. Understanding these differences is crucial for aligning your certification path with your career goals and skill level.
Direct comparison is difficult because different certifications target different career stages and specializations. For example, a CompTIA Security+ is a foundational certification, while a SANS GIAC certification often represents advanced expertise in a specific area. This comparison focuses on general similarities and differences to provide a useful overview.
CompTIA vs. (ISC)² vs. SANS Certifications: A Comparative Overview
The following table provides a high-level comparison of CompTIA, (ISC)², and SANS certifications. Note that this is a simplified comparison and many variations exist within each organization’s certification portfolio.
| Certification Type | CompTIA | (ISC)² | SANS |
|---|---|---|---|
| Focus | Broad, vendor-neutral foundational and intermediate skills | In-depth knowledge and experience in specific security domains, often requiring experience | Advanced, specialized skills in specific security areas; often requires significant experience |
| Entry Level/Experience Required | Generally entry-level to mid-level; some certifications require prior experience | Usually requires several years of experience in the field; specific experience requirements vary per certification | Typically requires significant experience and advanced knowledge; specific experience requirements vary greatly |
| Cost | Generally more affordable | Moderately priced | Significantly more expensive, reflecting intensive training and advanced content |
| Exam Format | Multiple-choice, performance-based questions | Multiple-choice and potentially essay-style questions | Often includes hands-on labs and simulations, reflecting real-world scenarios |
| Renewal Requirements | Varies depending on the specific certification; often requires continuing education credits | Requires continuing professional development (CPD) credits and often re-certification exams | Varies greatly depending on the specific certification; often requires re-certification or renewal |
| Industry Recognition | Widely recognized, particularly for entry-level and foundational roles | Highly respected and recognized, particularly for senior roles | Extremely prestigious within the cybersecurity community, signifying deep expertise |
| Strengths | Accessibility, affordability, broad coverage of foundational concepts, vendor neutrality | Industry respect, rigorous standards, recognition for advanced expertise | Deep technical expertise, hands-on experience, respected by employers seeking specialized skills |
| Weaknesses | May not be sufficient for senior roles; less specialized than other certifications | Can be expensive and time-consuming to obtain; significant experience is often a prerequisite | High cost, intensive training, requires significant prior experience |
Illustrative Case Studies
Real-world examples showcase the practical application of CompTIA Cyber Threat Detection certifications and highlight the effectiveness of the skills acquired. These case studies demonstrate how certified professionals successfully identify, respond to, and mitigate cyber threats, protecting organizations from significant damage.
Let’s examine a scenario where a CompTIA-certified security analyst played a crucial role in thwarting a sophisticated attack.
Successful Mitigation of a Ransomware Attack
A mid-sized manufacturing company experienced a significant slowdown in their network. Initial investigation revealed unusual network activity, including a spike in outbound encrypted traffic. The CompTIA-certified analyst, leveraging their knowledge of network forensics and malware analysis (skills directly addressed in the CompTIA Cyber Threat Detection certification), identified the source of the problem: a ransomware attack. The analyst used their skills in log analysis to pinpoint the initial point of compromise – a phishing email that bypassed the company’s initial email security filters.
The analyst then immediately isolated the infected systems, preventing further spread of the ransomware. They used their understanding of incident response procedures to create a comprehensive recovery plan, including restoring data from backups and implementing stricter security protocols. This swift action minimized the downtime and data loss, saving the company significant financial and reputational damage. The analyst’s understanding of malware analysis, incident response, and threat hunting techniques, all covered in the CompTIA curriculum, were instrumental in the successful mitigation of this attack.
Phishing Attack Detection and Prevention
Phishing remains a pervasive threat, often the initial vector for more damaging attacks. A CompTIA Cyber Threat Detection certification equips individuals with the knowledge to recognize and counter phishing attempts. The training emphasizes the analysis of email headers, URLs, and the content of suspicious emails. A well-trained analyst can identify subtle clues such as inconsistencies in sender information, unusual links, and grammatical errors that signal a phishing attempt.
For example, an email claiming to be from a financial institution might have a slightly misspelled URL or a generic greeting instead of a personalized one. The CompTIA curriculum provides the framework for understanding these indicators of compromise (IOCs) and using security tools to analyze suspicious emails and URLs. Furthermore, the certification emphasizes the importance of security awareness training for employees, which is a critical layer of defense against phishing attacks.
By educating employees on identifying and reporting suspicious emails, organizations significantly reduce their vulnerability to these attacks. A successful response to a phishing attack often involves not just technical skills but also a strong understanding of human factors and social engineering techniques. This holistic approach is a cornerstone of the CompTIA Cyber Threat Detection certification.
Ultimate Conclusion: Comptia Offers Certification To Evaluate Cyber Threats Detecting Skills
In conclusion, CompTIA’s certifications provide a robust pathway to mastering cyber threat detection skills. By focusing on practical application and real-world scenarios, these certifications equip professionals with the knowledge and confidence to tackle today’s complex cyber threats. Whether you’re just starting your cybersecurity journey or looking to advance your career, investing in a CompTIA certification is a smart move that will undoubtedly pay off.
So, are you ready to bolster your cybersecurity expertise and become a force to be reckoned with in the fight against cybercrime?
Question & Answer Hub
What is the cost of CompTIA certifications?
The cost varies depending on the specific certification and the testing center. It’s best to check the official CompTIA website for the most up-to-date pricing.
How long are CompTIA certifications valid?
CompTIA certifications are generally valid for three years. You may need to renew them through continuing education or recertification exams.
Are CompTIA certifications globally recognized?
Yes, CompTIA certifications are widely recognized and respected by employers globally in the cybersecurity field.
What kind of jobs can I get with a CompTIA certification?
CompTIA certifications can open doors to roles like Security Analyst, Systems Administrator, IT Auditor, and Penetration Tester, among others. The specific role depends on the certification level and your experience.