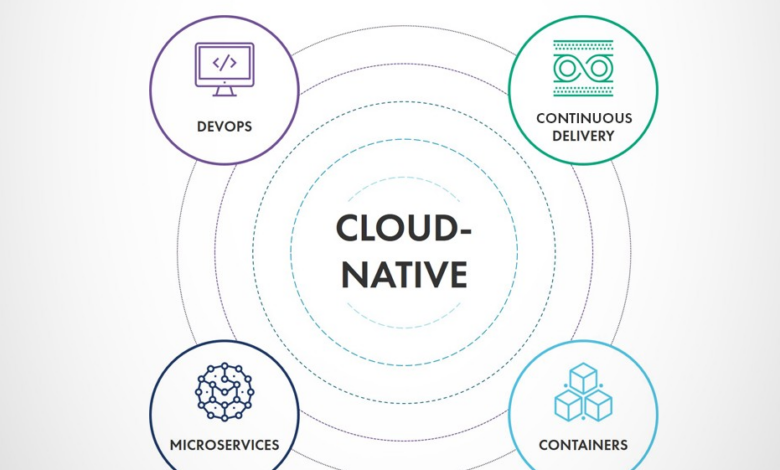
Three Cloud Native Must-Haves for Your Enterprise Software Portfolio
Three cloud native must haves for your enterprise software portfolio – Three Cloud Native Must-Haves for Your Enterprise Software Portfolio: Ready to supercharge your enterprise software? This isn’t just about moving to the cloud; it’s about building a truly modern, scalable, and resilient system. We’ll dive into the three essential pillars: microservices architecture, containerization and orchestration (with a focus on Kubernetes), and robust DevOps and CI/CD pipelines. Get ready to learn how these elements will transform your development process and deliver unparalleled value.
Think of your software as a finely tuned machine. Microservices act as individual, specialized parts, each working independently yet harmoniously. Containerization ensures these parts are packaged and deployed consistently, regardless of the environment. Finally, DevOps and CI/CD are the engine, automating the build, test, and deployment processes for speed and reliability. Mastering these three elements will position your enterprise for success in the increasingly competitive digital landscape.
Microservices Architecture
Microservices architecture is a crucial component of any successful cloud-native strategy. It involves breaking down a large application into smaller, independent services that communicate with each other over a network. This approach offers significant advantages over traditional monolithic architectures, particularly in the context of cloud deployment and scalability.Microservices offer several key benefits for cloud-native applications. Smaller, independent services are easier to develop, test, and deploy, leading to faster iteration cycles and quicker time to market.
Individual services can be scaled independently based on demand, optimizing resource utilization and cost-effectiveness. The use of different technologies for different services becomes feasible, allowing teams to choose the best tools for each specific task. Finally, improved fault isolation means that failures in one service are less likely to bring down the entire application.
Challenges of Managing Microservices
Managing a large number of microservices presents unique challenges. The increased complexity requires robust monitoring and logging systems to track the health and performance of each service. Service discovery and inter-service communication need careful consideration to ensure reliable interactions. Data consistency across multiple services can be difficult to maintain, requiring careful design of data models and communication protocols.
Deployment and orchestration become more complex, necessitating the use of tools like Kubernetes to manage the lifecycle of numerous services. Finally, ensuring consistent security across all services requires a comprehensive security strategy.
Examples of Successful Microservices Implementations
Netflix is a prime example of a company that successfully adopted a microservices architecture. Their streaming service is composed of hundreds of independent services, each responsible for a specific function, such as user authentication, video encoding, or recommendations. This allows them to scale individual services based on demand and deploy new features quickly. Similarly, Amazon, with its vast e-commerce platform, leverages microservices extensively to manage its various functionalities, from product catalogs and shopping carts to order processing and payment gateways.
These examples highlight the scalability and flexibility offered by a microservices approach.
Monolithic vs. Microservices Architecture
The following table compares monolithic and microservices architectures, highlighting key differences:
| Feature | Monolithic Architecture | Microservices Architecture |
|---|---|---|
| Scalability | Difficult to scale individual components; requires scaling the entire application. | Easy to scale individual services independently based on demand. |
| Deployment | Requires deploying the entire application as a single unit. Slow and risky. | Allows for independent deployment of individual services, leading to faster and less risky deployments. |
| Maintainability | Difficult to maintain and update as the application grows. Changes often require redeploying the entire application. | Easier to maintain and update individual services independently. Changes to one service do not necessitate redeployment of the entire application. |
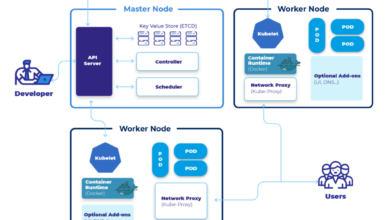
Containerization and Orchestration
Containerization and orchestration are fundamental pillars of modern cloud-native architectures. They provide a powerful mechanism for packaging, deploying, and managing applications across diverse environments, significantly improving scalability, efficiency, and resilience. This section delves into the best practices, key technologies, and security considerations surrounding containerization and orchestration in enterprise settings.
Best Practices for Containerizing Enterprise Applications
Effective containerization of enterprise applications requires careful planning and execution. A well-defined strategy ensures consistency, maintainability, and scalability. This includes adhering to established image building best practices, such as using multi-stage builds to minimize image size and employing automated security scanning tools to identify vulnerabilities. Furthermore, meticulous attention to resource allocation, including CPU, memory, and storage, is critical for optimal performance and resource utilization.
Proper logging and monitoring are essential for effective troubleshooting and performance analysis. Finally, adopting a standardized approach to container image tagging and versioning ensures seamless deployment and rollback capabilities.
Kubernetes’ Role in Managing Containerized Workloads
Kubernetes has emerged as the de facto standard for container orchestration. Its robust features simplify the complexities of managing containerized applications at scale. Kubernetes automates deployment, scaling, and management of containerized applications across a cluster of machines. It provides features like self-healing, automated rollouts and rollbacks, and service discovery, enabling developers to focus on application development rather than infrastructure management.
Its declarative configuration allows for consistent and reproducible deployments across various environments. Kubernetes also offers advanced features such as horizontal pod autoscaling, enabling applications to dynamically scale based on demand, and network policies for enhanced security and isolation.
Comparison of Container Orchestration Platforms
While Kubernetes dominates the market, other container orchestration platforms exist, each with its own strengths and weaknesses. Docker Swarm, for example, offers a simpler, more integrated solution within the Docker ecosystem, suitable for smaller deployments. OpenShift, a Kubernetes distribution from Red Hat, adds enterprise-grade features like enhanced security, monitoring, and management tools. Other platforms, such as Nomad and Rancher, offer alternative approaches with varying levels of complexity and features.
So, you’re thinking about those three cloud native must-haves for your enterprise software portfolio? Microservices, serverless functions, and robust APIs are usually top of the list, right? But to really nail that agile development, you need to consider your development approach too. Check out this insightful piece on domino app dev the low code and pro code future for some fresh perspectives.
Ultimately, choosing the right development methodology directly impacts how effectively you leverage those cloud native must-haves.
The choice of platform depends heavily on the specific needs and scale of the deployment, as well as the existing infrastructure and expertise within the organization. Factors to consider include scalability requirements, security features, ease of use, and integration with existing tools and workflows.
Security Considerations in Containerized Environments
Security is paramount in containerized environments. Vulnerabilities in container images, misconfigurations in Kubernetes deployments, and insecure network configurations can expose applications to significant risks. Implementing robust security practices is crucial. This includes regular security scanning of container images, employing least privilege principles for container processes, and implementing strong network policies within the Kubernetes cluster. Utilizing secrets management tools to securely store and manage sensitive information is also vital.
Regular security audits and penetration testing are essential to identify and mitigate potential vulnerabilities. Adopting a DevSecOps approach, integrating security practices throughout the entire software development lifecycle, is crucial for maintaining a secure containerized environment.
Deploying a Simple Application Using Docker and Kubernetes
This section Artikels a step-by-step guide to deploying a simple “Hello World” application using Docker and Kubernetes.
- Create a Dockerfile: A Dockerfile defines how to build a Docker image. For a simple “Hello World” application (e.g., a Node.js application), the Dockerfile might look like this:
FROM node:16WORKDIR /appCOPY package*.json ./RUN npm installCOPY . .CMD ["node", "server.js"]whereserver.jscontains the application code (e.g.,console.log("Hello World!");). - Build the Docker image: Build the image using the command
docker build -t my-hello-world . - Create a Kubernetes deployment YAML file: This file defines how the application should be deployed within the Kubernetes cluster. An example:
apiVersion: apps/v1kind: Deploymentmetadata: name: my-hello-world-deploymentspec: replicas: 3 selector: matchLabels: app: my-hello-world template: metadata: labels: app: my-hello-world spec: containers:name
my-hello-world-container image: my-hello-world ports:
containerPort
3000
- Create a Kubernetes service YAML file: This exposes the application to external access. Example:
apiVersion: v1kind: Servicemetadata: name: my-hello-world-servicespec: selector: app: my-hello-world ports:protocol
TCP port: 80 targetPort: 3000 type: LoadBalancer
- Deploy the application: Apply the YAML files to the Kubernetes cluster using the commands
kubectl apply -f deployment.yamlandkubectl apply -f service.yaml. - Verify the deployment: Use
kubectl get podsandkubectl get servicesto check the status of the deployment and service.
DevOps and CI/CD Pipelines

Adopting DevOps and implementing robust CI/CD pipelines are crucial for successfully deploying and managing cloud-native applications. A well-structured CI/CD process streamlines the software development lifecycle, enabling faster releases, improved collaboration, and enhanced quality. This approach is essential for maintaining a competitive edge in today’s rapidly evolving technological landscape.
Key Components of a Robust CI/CD Pipeline, Three cloud native must haves for your enterprise software portfolio
A robust CI/CD pipeline for cloud-native applications typically involves several key stages. These stages work together to automate the build, test, and deployment processes, minimizing manual intervention and maximizing efficiency. A breakdown of these components ensures a smooth and reliable delivery process.
- Source Code Management: Utilizing platforms like Git for version control, enabling collaborative development and efficient code management.
- Continuous Integration (CI): Automating the build process, running unit tests, and performing code analysis upon each code commit. This ensures early detection of integration issues.
- Continuous Delivery (CD): Automating the deployment process to various environments (development, testing, staging, production), allowing for frequent and reliable releases.
- Automated Testing: Incorporating various testing levels (unit, integration, system, end-to-end) to ensure software quality and identify bugs early in the development cycle.
- Deployment Automation: Utilizing tools and techniques to automate the deployment of applications to cloud environments, minimizing manual effort and ensuring consistency.
- Monitoring and Logging: Implementing comprehensive monitoring and logging to track application performance, identify issues, and facilitate debugging.
Implementing Automated Testing and Deployment
Automating testing and deployment is fundamental to a successful CI/CD pipeline. Tools facilitate this automation, improving efficiency and reducing the risk of human error. Consider the following approaches.Automated testing involves using frameworks like JUnit (Java), pytest (Python), or Selenium to write and execute tests automatically as part of the CI/CD process. Deployment automation relies on tools like Ansible, Chef, or Puppet for infrastructure management and configuration, and deployment tools like Jenkins, GitLab CI, or CircleCI to orchestrate the deployment process to various environments.
For example, a change to the codebase triggers automated tests; if successful, the application is automatically built and deployed to a testing environment. Subsequent approval triggers deployment to production.
Infrastructure as Code (IaC) Benefits
Infrastructure as Code (IaC) is the practice of managing and provisioning infrastructure through code, rather than manual processes. This approach offers several significant advantages in a cloud-native environment.
- Consistency and Repeatability: IaC ensures consistent infrastructure setups across different environments, simplifying deployments and reducing errors.
- Version Control: Tracking infrastructure changes using version control systems like Git allows for easy rollback to previous configurations if necessary.
- Automation: IaC automates the provisioning and management of infrastructure, significantly reducing manual effort and improving efficiency.
- Improved Collaboration: IaC facilitates collaboration among development and operations teams by providing a shared understanding and management of infrastructure.
Best Practices for Monitoring and Logging
Effective monitoring and logging are crucial for maintaining the health and performance of cloud-native applications. Implementing these best practices ensures proactive issue detection and resolution.
- Centralized Logging: Aggregate logs from various sources into a centralized logging system (e.g., Elasticsearch, Splunk, or the CloudWatch) for easier analysis and troubleshooting.
- Real-time Monitoring: Implement real-time monitoring dashboards to track key metrics (e.g., CPU usage, memory consumption, request latency) and proactively identify performance bottlenecks.
- Alerting: Set up alerts for critical events (e.g., high error rates, resource exhaustion) to enable timely intervention and prevent service disruptions.
- Traceability: Implement distributed tracing to track requests across multiple microservices and identify performance bottlenecks or errors.
Examples of CI/CD Tools and Their Capabilities
Several CI/CD tools are available, each offering a unique set of capabilities. The choice of tool depends on specific project needs and preferences.
- Jenkins: A widely used open-source automation server that supports a wide range of plugins and integrations.
- GitLab CI/CD: Integrated CI/CD capabilities within the GitLab platform, simplifying the workflow for Git-based projects.
- CircleCI: A cloud-based CI/CD platform known for its ease of use and scalability.
- GitHub Actions: A CI/CD platform integrated with GitHub, providing a seamless workflow for GitHub users.
- Azure DevOps: A comprehensive DevOps platform offered by Microsoft, providing a wide range of tools and services for software development and deployment.
Serverless Computing

Serverless computing represents a paradigm shift in application development, moving away from managing servers to focusing solely on code execution. Instead of provisioning and maintaining servers, developers deploy their code as functions that are triggered by events. This approach offers significant advantages in terms of scalability, cost-efficiency, and developer productivity, but also presents unique challenges regarding security and architecture design.
Let’s delve into the specifics.
Advantages and Disadvantages of Serverless Functions in Enterprise Applications
Serverless functions offer several compelling advantages for enterprise applications. The most significant is automatic scaling: functions scale automatically based on demand, eliminating the need for manual capacity planning and ensuring applications can handle traffic spikes without performance degradation. This scalability translates directly to cost savings, as you only pay for the compute time your functions consume. Furthermore, serverless simplifies deployment and maintenance, freeing developers from infrastructure management tasks and allowing them to focus on core business logic.
However, serverless also presents disadvantages. Cold starts, where the first invocation of a function can experience latency, can impact performance. Debugging and monitoring can be more complex than with traditional applications, requiring specialized tools and expertise. Vendor lock-in is also a potential concern, as migrating away from a specific serverless platform can be challenging.
Serverless Architectures and Workload Suitability
Various serverless architectures cater to different workload characteristics. A common approach involves using event-driven functions triggered by services like Amazon S3 (for file uploads) or AWS Lambda (for various event sources). This architecture is well-suited for asynchronous tasks and microservices that don’t require persistent connections. Another approach involves using serverless APIs, where functions handle incoming HTTP requests. This is ideal for building RESTful APIs or microservices requiring direct client interaction.
For computationally intensive tasks, serverless batch processing might be a better fit, leveraging serverless compute resources for large-scale data processing. The choice of architecture depends on factors like latency requirements, data processing needs, and the overall application design. For instance, a real-time chat application might require a different architecture than a batch image processing system.
Cost-Effectiveness of Serverless vs. Traditional Approaches
The cost-effectiveness of serverless depends on the specific application and usage patterns. In scenarios with unpredictable traffic or infrequent usage, serverless often proves more economical than traditional approaches, as you only pay for the compute time consumed. However, for applications with consistent, high-volume traffic, the cost difference might be less pronounced, and traditional approaches might even be more cost-effective.
Consider a scenario where a traditional application running on a dedicated server incurs fixed costs regardless of usage, while a serverless application only incurs costs when functions are invoked. If the application experiences periods of low activity, serverless will clearly be more cost-effective. Conversely, if the application consistently demands high compute resources, the cost savings might be less significant.
Security Implications of Serverless Technologies
Security in serverless environments requires a different approach than traditional infrastructure. Instead of securing servers, the focus shifts to securing functions, APIs, and data access. IAM roles and policies play a crucial role in controlling access to resources. Careful consideration must be given to function code security, including input validation and output sanitization to prevent vulnerabilities like SQL injection or cross-site scripting.
Data encryption both in transit and at rest is crucial for protecting sensitive information. Regular security audits and penetration testing are also essential to identify and mitigate potential weaknesses. A common security concern is the potential for unintended data exposure through improperly configured access controls.
Workflow of a Serverless Application
Imagine a diagram representing a user uploading an image to a website. The user’s action triggers an event (image upload). This event is detected by an event-driven function (e.g., an AWS Lambda function triggered by an Amazon S3 event). The function then processes the image (e.g., resizing, watermarking). Next, the processed image is stored in a cloud storage service (e.g., Amazon S3).
Finally, another function, possibly triggered by the image storage event, sends a notification to the user. This entire process happens without the user or developer explicitly managing servers. The functions execute automatically based on events, scaling up or down as needed. The system components interact through asynchronous messaging, ensuring loose coupling and high availability. The entire workflow is managed by the serverless platform, providing scalability and ease of management.
Observability and Monitoring
In the dynamic world of cloud-native applications, comprehensive monitoring and logging are no longer optional—they’re essential for survival. The ephemeral nature of containers and the distributed architecture of microservices demand a robust observability strategy. Without it, identifying and resolving issues becomes a nightmare, leading to downtime, frustrated users, and significant financial losses. This section delves into the crucial aspects of building a powerful observability system for your cloud-native applications.Observability in cloud-native systems goes beyond basic monitoring; it’s about gaining a deep understanding of your application’s behavior, performance, and health.
This involves collecting and analyzing various data streams, providing a holistic view of your system’s inner workings. Effective observability enables proactive identification of potential problems before they impact users, and allows for rapid diagnosis and resolution of existing issues.
Implementing Observability: Metrics, Logs, and Tracing
A comprehensive observability strategy leverages three key pillars: metrics, logs, and traces. Metrics provide high-level aggregated data points, offering a summary of system performance. Logs offer detailed contextual information about individual events, providing granular insights into specific operations. Traces follow individual requests as they propagate through the system, revealing the flow of data and identifying performance bottlenecks. Combining these three provides a complete picture.
For instance, a high error rate metric (metrics) might be investigated by examining the corresponding logs (logs) to find the root cause. Then, distributed tracing can show the specific path of the failing request, highlighting the component responsible for the error.
Monitoring Tools and Capabilities
The market offers a wide array of monitoring tools, each with its strengths and weaknesses. Popular choices include Prometheus, a widely-adopted open-source monitoring system known for its scalability and flexibility; Grafana, a powerful visualization tool that can integrate with various data sources including Prometheus; Jaeger, an open-source distributed tracing system; and Datadog, a comprehensive commercial platform offering a unified view of metrics, logs, and traces.
The choice depends on your specific needs, budget, and existing infrastructure. Open-source options like Prometheus and Jaeger provide cost-effective solutions, while commercial platforms like Datadog often offer more advanced features and support. Consider factors like scalability, integration with existing tools, and ease of use when making your selection.
Using Monitoring Data to Identify and Resolve Performance Bottlenecks
Effective use of monitoring data is crucial for identifying and resolving performance issues. By analyzing metrics, logs, and traces, you can pinpoint bottlenecks, resource constraints, and other problems affecting your application’s performance. For example, a sudden spike in request latency might indicate a database query issue, which can be further investigated by examining logs and traces to identify the slow query.
Similarly, high CPU utilization on a specific container can point to a code optimization problem. The process involves correlating data from different sources to create a comprehensive understanding of the issue and then implementing appropriate solutions, such as code optimization, database tuning, or infrastructure upgrades.
Key Metrics to Track for Cloud-Native Applications
Understanding which metrics to track is paramount. Focusing on the wrong metrics can lead to wasted effort and missed opportunities for optimization. A balanced approach is necessary, combining high-level metrics with more granular, application-specific data.
Here’s a list of key metrics to consider:
- Request latency: The time it takes to process a request.
- Error rate: The percentage of failed requests.
- Throughput: The number of requests processed per unit of time.
- Resource utilization (CPU, memory, network): The amount of resources consumed by your application.
- Database query performance: The time it takes to execute database queries.
- Application logs: Detailed information about application events and errors.
- Deployment frequency: The rate at which new code is deployed.
- Mean Time To Recovery (MTTR): The average time it takes to restore service after a failure.
- Uptime: The percentage of time the application is operational.
Final Conclusion
Building a truly cloud-native enterprise software portfolio requires a strategic approach. By embracing microservices, containerization, and streamlined DevOps, you’re not just modernizing your technology—you’re fundamentally changing how you develop, deploy, and manage your applications. This shift leads to increased agility, scalability, and reduced operational costs. The journey might seem daunting, but the rewards—in terms of efficiency, innovation, and competitive advantage—are well worth the effort.
So, are you ready to embark on this transformative journey?
FAQ Overview: Three Cloud Native Must Haves For Your Enterprise Software Portfolio
What are the biggest risks of migrating to a microservices architecture?
The biggest risks include increased complexity in managing a larger number of services, potential for increased latency due to inter-service communication, and the need for robust monitoring and tracing to identify issues.
How do I choose the right container orchestration platform?
Consider factors like scalability needs, existing infrastructure, team expertise, and the level of automation required. Kubernetes is a popular choice for its robustness and extensive community support, but other options exist depending on your specific needs.
What are some common CI/CD pipeline pitfalls to avoid?
Common pitfalls include insufficient testing, lack of automated rollback mechanisms, and neglecting security considerations throughout the pipeline. Prioritize robust testing, version control, and security scanning at every stage.
Is serverless computing always the most cost-effective solution?
Not necessarily. While serverless can reduce operational costs for infrequent or highly variable workloads, it might not be cost-effective for applications with consistently high resource demands.