
NAKIVO Backup & Replication v11.2 Elevates Data Protection with Real-Time Replication, Enhanced Hypervisor Support, and Robust Ransomware Defenses
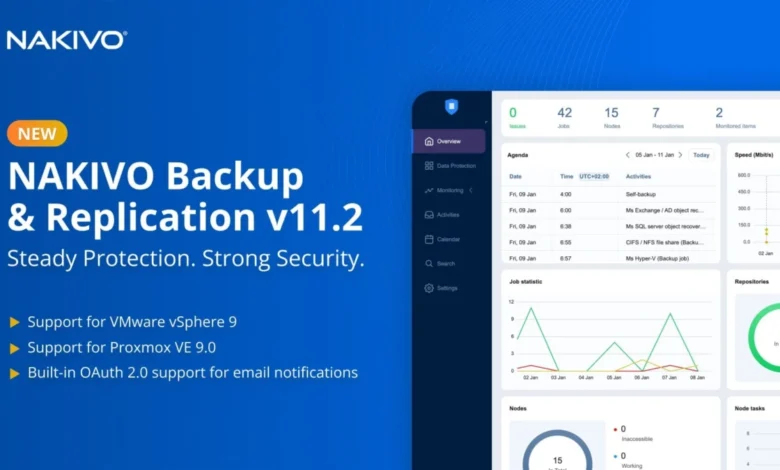
Sparks, Nevada – April 3rd, 2026 – NAKIVO Inc., a globally recognized provider of data protection solutions trusted by over 16,000 organizations across 191 countries, today announced the general availability of NAKIVO Backup & Replication v11.2. This latest iteration significantly bolsters its offerings for rapid, reliable, and proactive data protection, addressing the escalating challenges of evolving ransomware threats and rising downtime costs. The release introduces an automated real-time replication engine, expanded support for the latest VMware vSphere and Proxmox versions, and modern authentication protocols designed to expedite recovery processes and enhance data security without introducing undue complexity for IT teams.
In an era where cyberattacks are increasingly sophisticated and the financial repercussions of even brief operational interruptions are substantial, v11.2 equips IT departments with a more potent arsenal. The update is strategically designed to accelerate recovery times, ensure compatibility with next-generation infrastructure, and maintain stringent data protection standards. This proactive approach is crucial for businesses that cannot afford to be vulnerable to the widening gap between scheduled backups and potential data loss events.
Automated Real-Time Replication: Closing the Vulnerability Gap
Central to the advancements in v11.2 is the introduction of an automated real-time replication engine. This sophisticated technology continuously synchronizes replica virtual machines (VMs) with production workloads. In the event of hardware failures, ransomware incursions, or human errors, organizations can achieve failover to a recent, synchronized replica within minutes. This capability directly addresses a critical vulnerability inherent in traditional backup strategies: the time lag between the last backup job and the moment a failure occurs. For businesses where every minute of downtime translates into tangible financial losses or severe reputational damage, this feature provides an essential layer of resilience, minimizing the impact of unforeseen disruptions. The ability to recover to a near-instantaneous point in time significantly reduces the potential for data loss and operational paralysis, offering a crucial advantage in maintaining business continuity.

Comprehensive Support for Evolving Virtualization Platforms
A cornerstone of modern IT infrastructure is the continuous evolution of virtualization technologies. NAKIVO Backup & Replication v11.2 proactively aligns with these advancements by offering robust support for the latest versions of industry-leading hypervisors, ensuring seamless integration and uninterrupted protection for diverse environments.
Full VMware vSphere 9 Support: Ensuring Seamless Upgrades
For administrators managing VMware environments, v11.2 delivers production-ready support for VMware vSphere 9, including vCenter Server 9.0.1.0, ESXi 9.0.1.0, and the Virtual Disk Development Kit (VDDK) 9.0.1.0. While previous builds may have offered initial compatibility, v11.2 signifies full readiness, empowering VMware teams to confidently upgrade their infrastructure. This ensures that existing backup and recovery jobs continue to operate without disruption, a critical consideration for maintaining operational stability during platform transitions. All core NAKIVO functionalities, including backup, replication, recovery, and granular recovery, are fully operational under vSphere 9. This comprehensive support extends to organizations that are navigating VMware’s licensing shifts, moving away from standalone editions towards broader solutions like VMware vSphere Foundation 9.0, ensuring that NAKIVO remains a compatible and essential component of their evolving data protection strategy. The assurance of full compatibility alleviates a significant potential roadblock for organizations planning their vSphere 9 adoption roadmap, a process that often involves extensive planning and testing to mitigate risks.
Proxmox VE 9.0 and 9.1 Support: Maturing Open-Source Resilience
NAKIVO’s commitment to supporting open-source virtualization platforms continues with v11.2, which brings full compatibility with Proxmox VE 9.0. Furthermore, support for Proxmox VE 9.1 is already integrated, enabling organizations to upgrade their Proxmox environments without the fear of creating protection gaps. This is particularly beneficial for businesses utilizing Proxmox in edge deployments, cost-sensitive production environments, or as a strategic alternative to VMware. The full feature set available for Proxmox includes features such as VM backup and recovery, replication, and instant recovery, ensuring that these critical operations remain robust and efficient. For organizations managing hybrid environments that encompass both VMware and Proxmox platforms, NAKIVO’s unified management interface offers a consolidated workflow. This single pane of glass simplifies management and oversight as infrastructure complexity grows, providing a consistent and efficient approach to data protection across disparate environments. The ongoing development and support for Proxmox underscore NAKIVO’s dedication to providing comprehensive data protection solutions for a diverse range of IT infrastructures.
Enhanced Ransomware Defenses: A Multi-Layered Approach
In response to the escalating threat of ransomware, v11.2 integrates robust ransomware protection directly into its architecture, rather than treating it as an isolated feature. This comprehensive approach ensures that data is protected at multiple levels. Immutability is a key component, supported across a broad spectrum of storage targets, including cloud object storage services like AWS S3, Wasabi, Azure Blob, and Backblaze B2, as well as on-premises solutions such as HPE StoreOnce, NEC HYDRAstor, and Dell EMC Data Domain. This immutability ensures that backup data cannot be altered or deleted by ransomware, providing a secure, unchangeable copy for recovery.
Beyond immutability, v11.2 incorporates pre-recovery malware scanning. This feature proactively identifies and quarantines threats before they can re-enter production environments during the recovery process, significantly reducing the risk of reinfection. For an ultimate last line of defense, NAKIVO offers air-gapped backup options. These include traditional methods like tape backups, detached USB drives, and offline NAS storage, which are physically isolated from the network and therefore immune to online threats. This multi-layered ransomware defense strategy provides organizations with a formidable shield against one of the most pervasive and damaging cyber threats. The continuous evolution of ransomware tactics necessitates equally dynamic and robust defenses, a challenge that NAKIVO’s latest release aims to meet head-on.
Bruce Talley, CEO of NAKIVO, emphasized the company’s strategic focus: "Our priority is to give customers a smooth and secure path forward as their environments evolve. v11.2 focuses on compatibility, security, and consistent performance as virtualization platforms advance." This statement highlights NAKIVO’s commitment to anticipating and addressing the needs of its user base in a rapidly changing technological landscape.
Matt Mitchell, Web Developer at SEHD at the University of Colorado Denver, shared his positive experience: "With NAKIVO Backup & Replication, I can recover VMware VMs within 10 minutes. With data deduplication, we were able to decrease storage space by 80%." This testimonial underscores the tangible benefits of NAKIVO’s solutions, particularly concerning recovery speed and storage efficiency.
Modern Authentication for Enhanced Security and Compliance
In a significant security upgrade, v11.2 introduces native OAuth 2.0 authentication for email notifications. This modern, token-based authentication protocol replaces the deprecated basic authentication methods, which are being actively phased out by major email providers such as Google Workspace and Microsoft 365. By eliminating the need to store plain-text credentials, OAuth 2.0 significantly enhances compliance and security posture, especially for organizations operating under strict regulatory requirements. This shift is not merely a technical upgrade but a crucial step towards fortifying the communication channels used for critical alerts and notifications, ensuring they remain secure and reliable.
Further enhancing integration with enterprise storage solutions, HPE StoreOnce users will benefit from full support for VSA Gen 5. This improves deduplication appliance integration and repository performance. The platform’s underlying technology stack has also been updated to Java SE 24 and the latest Spring Framework. These updates deliver substantial stability improvements, crucial security patches, and incremental gains in backup and restore throughput. In environments that rely on frequent backup operations, these compounding performance benefits can lead to significant operational efficiencies over time.
Streamlined Management for Managed Service Providers (MSPs)
Managed Service Providers (MSPs) operating in multi-tenant environments will experience enhanced operational efficiency through improvements to NAKIVO’s MSP Direct Connect feature. The updated interface provides a single, unified view across multiple tenants, significantly reducing administrative overhead and accelerating response times. For MSPs focused on scaling their service portfolios and expanding their client base, this enhancement directly supports business growth without necessitating a proportional increase in administrative resources. This streamlined management capability is vital for MSPs looking to deliver high-quality, cost-effective services while maintaining robust data protection for their diverse clientele.
The Broader Impact and Availability
NAKIVO Backup & Replication v11.2 represents a significant operational release, addressing key challenges faced by modern IT departments. By removing compatibility barriers that hinder infrastructure upgrades, strengthening resilience against ransomware, and tightening security across critical areas, v11.2 provides a robust foundation for operational stability. For VMware administrators preparing for vSphere 9 migrations, Proxmox environments nearing version upgrades, or any organization aiming to enhance its recovery capabilities, this release offers a compelling solution.
The implications of v11.2 are far-reaching. For enterprises, it means reduced risk of catastrophic data loss and prolonged downtime, which can translate into millions in saved revenue and preserved brand reputation. For SMBs, it offers enterprise-grade data protection capabilities at a more accessible level, democratizing access to advanced security features. The enhanced support for cloud storage and modern authentication also positions organizations for greater agility and compliance in increasingly cloud-centric IT landscapes.
NAKIVO Backup & Replication v11.2 is available now. Organizations can access a fully featured free trial of the latest version by visiting the official NAKIVO website. This allows potential customers to experience firsthand the advanced features and benefits of the updated platform.
About NAKIVO
NAKIVO is a US-based corporation dedicated to delivering the ultimate backup, ransomware protection, and disaster recovery solution for virtual, physical, cloud, and SaaS environments. With a global footprint, over 16,000 customers in 191 countries rely on NAKIVO to protect their data. This includes prominent global brands such as Coca-Cola, Honda, Siemens, and Cisco, attesting to the robustness and scalability of NAKIVO’s offerings.
Visit: www.nakivo.com









{kind=link}