
Apple Account Change Notifications Abused for Sophisticated iPhone Purchase Phishing Scams

In a concerning development for Apple users, malicious actors are now leveraging legitimate Apple account change notifications to distribute convincing phishing scams that mimic fraudulent iPhone purchases. These attacks, identified by BleepingComputer, exploit a loophole within Apple’s system by embedding phishing lures directly into official security alerts, thereby increasing their credibility and potentially bypassing standard spam filters. The sophistication of this tactic highlights an evolving threat landscape where attackers increasingly weaponize the trust users place in established brands.
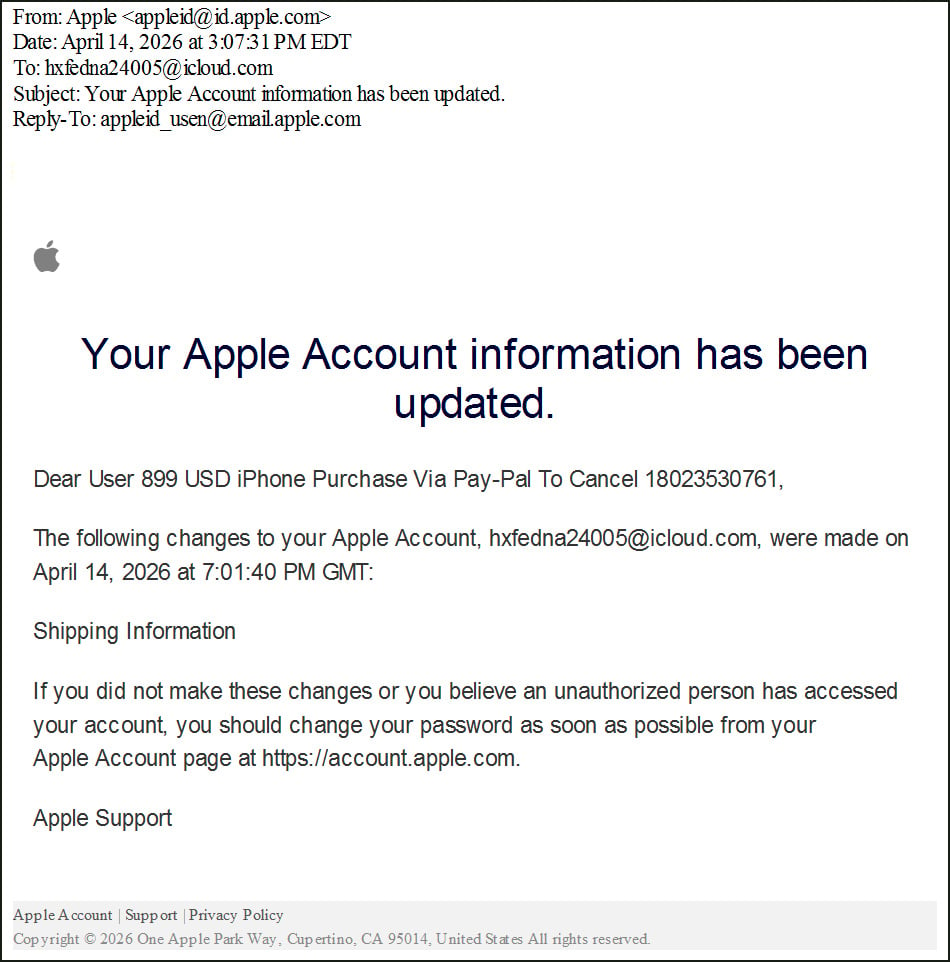
The core of this scam involves tricking recipients into believing an unauthorized $899 iPhone purchase has been made through PayPal, with a deceptive phone number provided to "cancel" the transaction. This callback phishing method is designed to exploit urgency and fear, prompting victims to immediately contact the scammers. Once engaged, the perpetrators typically employ social engineering tactics to convince individuals that their accounts have been compromised, often leading to requests for remote access software installation or the disclosure of sensitive financial information. Previous iterations of such scams have seen these remote access intrusions used for direct financial theft, malware deployment, and significant data breaches.
The Mechanics of the Exploit: Exploiting Account Personalization
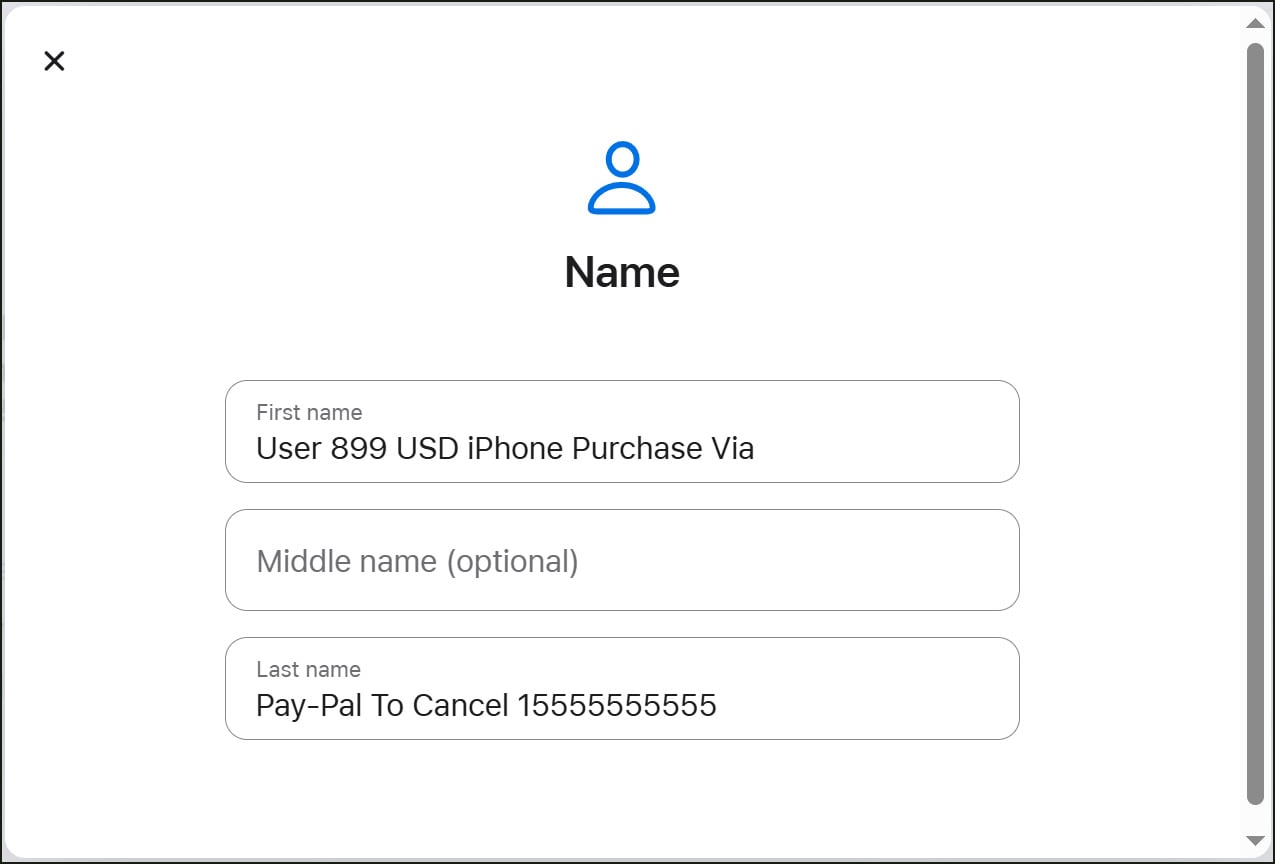
The ingenuity of this phishing campaign lies in its method of delivery. Threat actors are not spoofing Apple’s emails; instead, they are utilizing Apple’s own infrastructure and legitimate notification system. The process begins with the creation of a new Apple ID. Within the personal information fields of this newly created account, specifically the "First Name" and "Last Name" fields, the attackers meticulously embed fragments of their phishing message. Since these fields have character limitations, the scam text is strategically split between them, forming a cohesive, albeit alarming, message when displayed in an Apple notification.

For instance, a typical phishing email observed by BleepingComputer presented the following deceptive alert: "Dear User 899 USD iPhone Purchase Via Pay-Pal To Cancel 18023530761." This alarming statement is then followed by seemingly legitimate account change details, such as "The following changes to your Apple Account, [email protected], were made on April 14, 2026 at 7:01:40 PM GMT: Shipping Information." The inclusion of a real-looking email address, even one associated with the attacker’s own account, adds a layer of verisimilitude, making it appear as if unauthorized access has occurred.
To trigger the delivery of this embedded message, the attackers then intentionally modify the shipping information associated with the Apple ID. This action prompts Apple’s system to generate and send a standard account change notification to the email address linked to the account. Crucially, Apple’s notification system incorporates the user-supplied first and last name fields directly into the body of these alerts. Consequently, the phishing message, painstakingly crafted within these fields, is seamlessly integrated into a legitimate security email, appearing as an authentic alert from Apple.
Authenticity Through Legitimate Channels: Bypassing Security Measures
The effectiveness of this attack is significantly amplified by its ability to circumvent typical security protocols. The phishing emails are sent from Apple’s legitimate servers, utilizing official sender addresses such as [email protected]. Furthermore, these emails successfully pass stringent authentication checks, including Sender Policy Framework (SPF), DomainKeys Identified Mail (DKIM), and Domain-based Message Authentication, Reporting, and Conformance (DMARC). The provided email headers clearly indicate a "pass" for both DKIM and SPF, with the mail originating from Apple’s infrastructure and relayed through outbound.mr.icloud.com, originating from an Apple-owned IP address (17.111.110.47). This technical validation lends an unprecedented level of authenticity to the scam, making it incredibly difficult for both end-users and automated security systems to distinguish from genuine communications.
The technical details observed in the headers, such as dkim=pass header.d=id.apple.com [email protected] header.b=o3ICBLWN and spf=pass (spf.icloud.com: domain of [email protected] designates 17.111.110.47 as permitted sender) [email protected], underscore the sophisticated nature of this exploit. These headers confirm that the email is not a simple spoofing attempt but rather a legitimate message originating from Apple’s mail servers. The initial server identified as rn2-txn-msbadger01107.apple.com further solidifies its origin within Apple’s network.

The Evolution of Phishing Tactics: A Pattern of Exploitation
This current campaign is not an isolated incident but rather a continuation of a broader trend where threat actors are adept at identifying and exploiting vulnerabilities in legitimate online services. This method of embedding phishing content within user-generated fields of account notifications is a particularly insidious development. It mirrors a previous campaign that BleepingComputer reported on, where threat actors abused iCloud Calendar invites to send fake purchase notifications, also originating from Apple’s servers. In that instance, malicious events were added to user calendars, appearing as legitimate reminders, which then contained phishing links.
The underlying principle remains the same: leverage the inherent trust users have in major technology providers and their communication channels. By using Apple’s own notification system, attackers effectively hide their malicious intent within a trusted delivery mechanism, bypassing the usual red flags that users have learned to associate with phishing attempts. The fact that the email was initially sent to an iCloud address associated with the attacker, but the header analysis indicates it was likely distributed to multiple targets via a mailing list, suggests a systematic and scaled operation.
The Dangers of Callback Phishing: A Deeper Dive
Callback phishing, as employed in this scam, is a particularly dangerous form of social engineering. The immediate threat is the potential for financial loss. When a victim calls the provided number, the scammers, posing as Apple support agents, aim to instill panic. They might claim that the victim’s account has been accessed by hackers and that immediate action is required to secure their funds. This often involves guiding the victim through a process that, under the guise of security, leads to the theft of money.
The methods employed can range from instructing victims to transfer funds to a "secure" account (which is actually controlled by the scammers) to coercing them into purchasing gift cards and providing the redemption codes. More sophisticated attacks may involve tricking the victim into installing remote access software, such as TeamViewer or AnyDesk. Once installed, this software grants the attackers direct control over the victim’s computer, allowing them to access banking information, steal credentials, deploy ransomware, or conduct further malicious activities. The historical data from previous callback phishing incidents consistently shows the severe consequences, including complete draining of bank accounts and the installation of persistent malware.
Implications for Users and Apple
The implications of this sophisticated phishing campaign are far-reaching. For users, it underscores the increasing need for heightened vigilance and a critical approach to all digital communications, even those that appear to come from trusted sources. The ability of attackers to masqueromail as legitimate entities, leveraging official channels, means that traditional security advice, such as "look for suspicious sender addresses," is no longer sufficient. Users should exercise extreme caution with any unsolicited notifications that demand immediate action, especially those involving financial transactions or requests to call support numbers. It is always advisable to independently verify any suspicious activity by visiting the official website of the service provider or contacting them through known, legitimate channels, rather than using contact information provided within the suspicious communication.
For Apple, this incident presents a significant challenge to its reputation for security and user trust. The fact that a fundamental account notification system can be exploited in such a manner raises questions about the robustness of their internal security checks and the mechanisms for preventing the abuse of user-configurable fields. While Apple has historically been proactive in addressing security vulnerabilities, the ongoing nature of this exploit suggests a need for immediate review and remediation of the account creation and notification processes. The company’s silence on the matter, despite being contacted by BleepingComputer, leaves users in a state of vulnerability. A swift and transparent response from Apple, including clear guidance for users and a demonstration of corrective actions, would be crucial in mitigating the damage to user confidence.
Recommendations for Enhanced Security Awareness
In light of these evolving threats, cybersecurity experts consistently emphasize the importance of comprehensive security awareness training. For individuals, this means:
- Skepticism is Key: Treat all unexpected notifications, especially those concerning financial transactions or account security, with a healthy dose of skepticism.
- Verify Independently: If you receive an alert about an unauthorized purchase or account change, do not click on any links or call any numbers provided in the email. Instead, navigate directly to the official website of the service provider (e.g., Apple.com) and log in to your account to check for any suspicious activity.
- Enable Two-Factor Authentication (2FA): Ensure 2FA is enabled on all your online accounts, including your Apple ID. This adds an extra layer of security, requiring a second form of verification beyond just your password.
- Review Account Settings Regularly: Periodically review your account information, including shipping and billing details, for any unauthorized changes.
- Report Suspicious Activity: If you encounter a phishing attempt, report it to the service provider (in this case, Apple) and relevant cybersecurity authorities.
The continued innovation by threat actors in exploiting legitimate platforms underscores the dynamic nature of cybersecurity. As technology advances, so too do the methods employed by those seeking to exploit it. Staying informed and adopting a proactive security posture are no longer optional but essential for safeguarding personal information and financial assets in the digital age. The current abuse of Apple’s account notification system serves as a stark reminder that vigilance must remain paramount.









{kind=link}