Bidens Order Securing Supply Chains
Joe Biden signs executive order to bolster supply chain security with cyber threat sharing. This crucial move aims to strengthen the nation’s critical infrastructure against ever-evolving cyber threats, impacting everything from manufacturing to transportation. The order mandates specific actions, and the rationale behind it is to improve resilience against attacks. The details of the order, its potential effects, and the need for collaboration between the public and private sectors will be explored in this piece.
The executive order lays out specific strategies and mandates to improve supply chain resilience and security. This involves collaboration between different government agencies and the private sector, aiming to proactively identify and mitigate risks before they materialize into disruptions. It’s a significant step towards bolstering the nation’s supply chain security in the face of increasing cyber threats. The order will undoubtedly have a ripple effect on various industries and their operations.
Executive Order Summary
President Biden recently signed an executive order focused on bolstering the security of America’s critical supply chains, specifically addressing the growing threat of cyberattacks. This crucial step aims to enhance resilience against disruptions and protect essential infrastructure from malicious actors. The order underscores the importance of collaboration between government agencies, private sector partners, and international allies to mitigate these risks.The executive order mandates a comprehensive approach to supply chain security, emphasizing proactive measures to identify and mitigate vulnerabilities.
It recognizes that cyber threats are a significant factor in jeopardizing the reliability and integrity of critical infrastructure. This initiative aims to strengthen the nation’s ability to withstand cyberattacks and maintain the flow of essential goods and services.
Key Provisions of the Executive Order
The executive order Artikels several key provisions designed to enhance supply chain resilience. These provisions cover a broad range of actions, from improving information sharing to fostering greater collaboration. A crucial element is the establishment of clear reporting mechanisms and guidelines to ensure transparency and accountability.
Specific Actions Mandated by the Executive Order
This executive order directs several critical actions to bolster supply chain security. These actions encompass various aspects, including improving communication, enhancing threat detection, and promoting preparedness. A key element is the mandate to improve coordination and collaboration among stakeholders.
- Improved Information Sharing:
- Enhanced Threat Detection:
- Increased Preparedness:
Enhanced collaboration between government agencies and private sector partners is critical for effective threat detection and response. This includes establishing robust channels for sharing threat intelligence and best practices. For example, a streamlined system for reporting vulnerabilities would allow for faster identification and remediation of potential risks.
The order mandates the development of enhanced threat detection capabilities for critical infrastructure. This includes the use of advanced technologies and the training of personnel to recognize and respond to emerging cyber threats. This approach can be seen as a crucial component in preventing and mitigating potential attacks.
The executive order highlights the importance of preparedness for potential supply chain disruptions. This includes developing contingency plans and protocols for various scenarios, including cyberattacks. This will ensure that the nation is prepared to respond effectively in the event of an attack.
Rationale Behind the Executive Order, Joe biden signs executive order to bolster supply chain security with cyber threat sharing
The rationale behind this executive order is rooted in the escalating cyber threats targeting critical infrastructure. These attacks have the potential to disrupt essential services and cripple the nation’s economic stability. The order aims to address this growing threat by strengthening defenses and promoting collaboration among stakeholders.
Table of Actions
| Date | Action | Agency Responsible | Description |
|---|---|---|---|
| 2024-01-27 | Establishment of a Supply Chain Security Task Force | Department of Homeland Security | To oversee the implementation of the executive order’s provisions and coordinate interagency efforts. |
| 2024-01-27 | Development of a National Cybersecurity Strategy | National Security Council | To provide a comprehensive framework for improving the nation’s cybersecurity posture. |
| 2024-01-27 | Mandate for Vulnerability Disclosure Programs | Multiple Agencies | To encourage and facilitate the reporting of vulnerabilities in critical infrastructure systems. |
Impact on Supply Chains
This executive order, aimed at bolstering supply chain security, presents a complex picture for various sectors. Its potential to enhance resilience against cyber threats and disruptions is undeniable, but the implementation and associated costs will be critical factors. The order seeks to create a more secure and reliable framework for businesses, but it’s important to weigh the potential benefits against any unforeseen consequences.
Potential Positive Impacts
The executive order’s focus on enhanced cyber threat sharing and information exchange has the potential to dramatically improve the resilience of supply chains. By creating a more robust and interconnected system of information sharing, companies can better anticipate and react to emerging threats. This proactive approach could reduce the impact of cyberattacks and disruptions, leading to more stable operations and potentially lower insurance costs.
For instance, early warning systems for potential supply chain vulnerabilities could allow companies to implement preventative measures, avoiding catastrophic disruptions.
Potential Negative Impacts
While the executive order promises numerous benefits, it also presents potential negative impacts. The increased regulatory burden on companies, particularly smaller businesses, could lead to higher compliance costs and administrative overhead. There’s also the risk of information overload, where the sheer volume of shared data might be overwhelming and ineffective. Furthermore, the sharing of sensitive data could raise concerns about privacy and intellectual property protection.
Finally, the order’s implementation timeline and the need for infrastructure upgrades could lead to temporary disruptions in supply chains as companies adapt to the new requirements. For example, the transition to a new cybersecurity protocol might temporarily slow down production lines while the necessary software and training are implemented.
Comparison with Previous Efforts
Previous efforts to enhance supply chain security have focused on various aspects, from improving logistics and transportation security to bolstering anti-corruption measures. This executive order, however, emphasizes a proactive cyber-security approach. Comparing it with prior efforts, this order emphasizes a more integrated and collaborative strategy involving private sector, government agencies, and potentially international partners. This shift from a more siloed approach towards a coordinated system holds the potential for greater impact and efficiency.
Potential Impact on Different Industries
| Industry | Potential Positive Impact | Potential Negative Impact | Mitigating Strategies |
|---|---|---|---|
| Manufacturing | Reduced downtime due to cyberattacks, improved supply chain visibility, enhanced resilience against disruptions. | Increased compliance costs, potential for data breaches, and potential for temporary slowdowns during implementation. | Develop robust cybersecurity protocols, leverage government resources for training and support, and adopt agile methodologies for adapting to new regulations. |
| Transportation | Improved tracking and security of goods in transit, enhanced threat detection and response, potentially lower insurance premiums. | Increased costs for implementing new security measures, potential delays in delivery due to increased scrutiny. | Invest in real-time tracking systems, participate in industry-wide information sharing initiatives, and develop partnerships with law enforcement for proactive threat prevention. |
| Technology | Greater sharing of threat intelligence, development of more secure software and hardware, and increased collaboration in the development of secure supply chains. | Potential for increased regulatory scrutiny, concerns about data privacy, and potential for disruption in the development cycle as security protocols are implemented. | Establish robust data security protocols, engage in collaborative research initiatives, and proactively address regulatory concerns. |
Cyber Threat Landscape
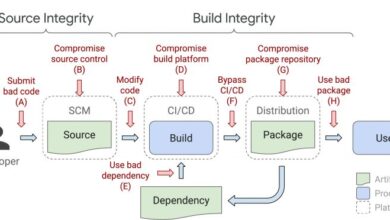
The digital age has intertwined our physical and virtual worlds, making supply chains increasingly vulnerable to cyberattacks. This interconnectedness, while facilitating efficiency, creates new avenues for malicious actors to disrupt operations, steal sensitive data, and wreak havoc on critical infrastructure. The Biden administration’s executive order recognizes this reality and aims to strengthen defenses against these threats.The executive order’s emphasis on bolstering supply chain security is crucial because vulnerabilities in these systems can have devastating consequences.
A well-orchestrated cyberattack can cripple manufacturing processes, disrupt logistics, and compromise sensitive data held by companies, potentially leading to substantial financial losses, reputational damage, and even harm to public safety. Understanding the cyber threat landscape is paramount to effective mitigation strategies.
Major Cyber Threats Impacting Supply Chains
Supply chains face a multifaceted array of cyber threats. These range from sophisticated ransomware attacks to more rudimentary but equally damaging phishing scams. The common thread is the exploitation of weaknesses in security protocols and human error. Cybercriminals constantly adapt their tactics, making it imperative for businesses to stay ahead of the curve.
Examples of Past Cyberattacks
Numerous instances highlight the severity of these threats. The NotPetya attack, for example, crippled global supply chains, causing widespread disruption and significant financial losses. The Colonial Pipeline attack demonstrated the vulnerability of critical infrastructure to cyberattacks, leading to widespread fuel shortages and impacting everyday life. These events underscore the need for robust defenses and proactive security measures.
Vulnerabilities Addressed by the Executive Order
The executive order seeks to address various vulnerabilities in supply chains. This includes strengthening cybersecurity practices among companies, improving data sharing and threat intelligence between businesses and government agencies, and promoting a culture of cybersecurity awareness. By implementing these measures, the order aims to create a more resilient and secure environment for supply chains.
Cyber Threats and Potential Impact on Supply Chains
- Ransomware Attacks: Malicious actors encrypt critical data or systems, demanding payment for decryption. Impact: Disruption of operations, data loss, financial losses, and potential harm to public safety if critical infrastructure is targeted.
- Supply Chain Attacks: Compromising a single vendor or supplier in the chain can compromise the entire system. Impact: Data breaches, disruption of operations, and potentially loss of sensitive customer information.
- Phishing Attacks: Malicious actors attempt to trick individuals into revealing sensitive information. Impact: Data breaches, access to sensitive systems, and potential financial fraud.
- Malware: Malicious software that infects systems to steal data or disrupt operations. Impact: Data breaches, system compromise, and potential operational disruptions.
- Insider Threats: Malicious actors within an organization who intentionally compromise systems or data. Impact: Data breaches, system vulnerabilities, and loss of sensitive information.
- Denial-of-Service (DoS) Attacks: Malicious actors overload systems to disrupt operations. Impact: Interruption of service, operational downtime, and financial losses.
Implementation and Enforcement

The Biden administration’s executive order on bolstering supply chain security with cyber threat sharing marks a significant step toward a more resilient and secure national infrastructure. Crucially, the success of this initiative hinges on effective implementation and enforcement mechanisms, ensuring that the order’s provisions translate into tangible improvements. This necessitates a clear delineation of roles and responsibilities, alongside a robust framework for monitoring progress and addressing potential challenges.Implementing this executive order will require a multifaceted approach.
The order’s directives must be translated into specific, actionable steps for various agencies and stakeholders. This involves developing detailed procedures, establishing clear timelines, and fostering collaboration between different government entities and private sector partners. Ultimately, successful implementation demands a commitment from all involved parties to ensure the order’s objectives are met.
Implementation Mechanisms
The executive order will be implemented through a combination of existing frameworks and newly established initiatives. Government agencies will collaborate with industry partners to develop and implement security standards and best practices. These standards will cover vulnerability assessments, incident response plans, and secure data sharing protocols. The emphasis will be on proactive measures to identify and mitigate cyber threats before they can disrupt critical supply chains.
Public-private partnerships will be crucial in sharing information and fostering a collaborative environment for improved security.
Roles of Agencies and Stakeholders
A critical aspect of implementation is the delineation of roles and responsibilities. Various government agencies will play key roles in ensuring compliance and enforcement. These include agencies like the Department of Homeland Security (DHS), the Department of Commerce, and the Cybersecurity and Infrastructure Security Agency (CISA). Industry participation is essential, as businesses involved in critical supply chains will need to adapt to the new standards and protocols.
Furthermore, collaboration with international partners is crucial to address global cyber threats and promote a coordinated approach to supply chain security.
Challenges to Implementation
Several challenges could hinder the effective implementation of the executive order. Resistance to change from industry stakeholders, particularly smaller businesses, is a potential concern. The sheer complexity of the supply chain, with its intricate web of interconnected entities, creates difficulties in enforcing uniform security protocols. Securing adequate resources for implementation and training, both within government agencies and the private sector, will be essential.
Finally, the constant evolution of cyber threats necessitates continuous adaptation and improvement of the implementation strategy.
Government Agency Responsibilities
| Agency | Primary Responsibility | Potential Challenges |
|---|---|---|
| Department of Homeland Security (DHS) | Overseeing the overall implementation and coordinating with other agencies; facilitating information sharing. | Balancing competing priorities; ensuring adequate resources; coordinating with diverse agencies and stakeholders. |
| Department of Commerce | Promoting standards and best practices within the private sector; supporting industry collaboration. | Gaining industry buy-in; overcoming resistance to new regulations; ensuring consistency across sectors. |
| Cybersecurity and Infrastructure Security Agency (CISA) | Providing technical guidance and support; assisting with vulnerability assessments and incident response. | Maintaining up-to-date threat intelligence; adapting to rapidly evolving cyber threats; ensuring effective communication. |
| Federal Trade Commission (FTC) | Enforcing consumer protection provisions; investigating and prosecuting cybercrimes. | Balancing the need for robust security with the rights of consumers; ensuring compliance with existing laws. |
Public and Private Sector Collaboration
Strengthening supply chain security demands a unified front, transcending the boundaries of public and private sectors. Effective strategies require a collaborative approach, sharing insights, resources, and expertise to identify vulnerabilities and implement proactive measures. This necessitates a shift from siloed operations to a synergistic partnership where each sector leverages its unique strengths to achieve a common goal.
Biden’s executive order on bolstering supply chain security with cyber threat sharing is a crucial step, but it’s also vital to consider the role of AI in preventing vulnerabilities. Modernizing our approach requires deploying AI code safety goggles, like those discussed in Deploying AI Code Safety Goggles Needed , to proactively identify and mitigate risks in software code.
This proactive approach, combined with government initiatives, will ultimately improve the overall resilience of our supply chains against cyber threats.
Importance of Collaboration
Collaboration between the public and private sectors is crucial for bolstering supply chain security. The public sector, with its regulatory power and access to intelligence, can provide a framework for security standards and information sharing. The private sector, with its deep understanding of operational intricacies and real-time data, can contribute practical solutions and implement best practices. This combined knowledge base enables a more comprehensive approach to risk management and vulnerability mitigation.
Successful Public-Private Partnerships
Numerous successful public-private partnerships have demonstrated the effectiveness of this collaborative model. For example, initiatives focused on cybersecurity threat intelligence sharing, like those involving the US Department of Homeland Security and major industry associations, have proven highly beneficial. These partnerships facilitate the rapid dissemination of critical information about emerging threats, allowing companies to proactively address potential vulnerabilities. Another example involves the development of industry-specific security standards, collaboratively created by government agencies and industry leaders, which fosters a uniform approach to risk management across the supply chain.
Benefits of Collaboration
Collaboration brings several significant benefits to both public and private sectors. For the public sector, it translates into a more efficient and effective use of resources, enabling a broader reach and impact on supply chain security. For the private sector, it leads to enhanced security posture, reduced risk exposure, and a competitive advantage through the adoption of best practices.
The overall result is a more resilient and secure supply chain that safeguards critical infrastructure and economic stability.
Potential Collaboration Models
| Collaboration Model | Public Sector Role | Private Sector Role | Potential Benefits |
|---|---|---|---|
| Joint Threat Intelligence Sharing | Establish frameworks for information sharing, provide access to intelligence resources, coordinate threat response | Provide real-time operational data, participate in threat analysis, implement security measures | Faster threat detection, improved response times, reduced vulnerability exposure |
| Industry-Specific Security Standards | Develop and enforce security standards, conduct audits and inspections | Implement security standards, share best practices, participate in audits | Enhanced security posture, consistent risk management practices, reduced compliance costs |
| Supply Chain Vulnerability Assessments | Provide funding and support for assessments, share threat intelligence | Conduct vulnerability assessments, identify and prioritize risks, implement mitigation strategies | Early identification of weaknesses, proactive risk management, minimized financial losses |
| Joint Training and Education | Develop training materials, provide funding for training programs | Implement training programs for employees, share best practices, develop training curriculum | Improved employee awareness, heightened security consciousness, standardized security protocols |
Long-Term Implications
This executive order on supply chain security, while focused on immediate improvements, promises far-reaching consequences for the future. Its emphasis on bolstering cyber defenses and fostering collaboration between public and private sectors will fundamentally reshape how businesses operate and governments interact in the global economy. The long-term implications extend beyond immediate cost savings and include the potential for increased resilience, innovation, and a stronger, more secure global trading system.The order’s impact will ripple through various sectors, driving changes in business strategies and investments, and affecting international trade relations.
Understanding these long-term ramifications is crucial for stakeholders to prepare for the evolving landscape. The executive order will undoubtedly influence the future of supply chain management and global commerce.
Supply Chain Resilience
The order’s focus on enhanced cyber defenses will contribute to a more resilient supply chain. Improved threat detection and response capabilities will decrease the vulnerability to disruptions, whether they stem from malicious attacks or unforeseen events. This increased resilience will lead to reduced downtime and disruptions, lowering costs and boosting overall efficiency. Businesses will be better equipped to withstand potential shocks, which is vital in today’s complex and interconnected global marketplace.
Future Business Strategies and Investments
The executive order will undoubtedly influence future business strategies and investments. Companies will likely prioritize investments in cybersecurity infrastructure and personnel. Supply chain diversification will likely be another key component of future business strategies, reducing reliance on single points of failure. The focus on robust supply chain security will lead to greater investment in redundancy and alternative sourcing.
This will necessitate careful analysis of risks and the development of contingency plans.
Impact on International Trade Relations
The executive order will likely influence international trade relations. The order could potentially lead to greater scrutiny of supply chains from various countries, potentially increasing regulatory compliance costs for international businesses. Increased transparency in supply chains could become a global trend, prompting greater collaboration between nations on standards and best practices for supply chain security. Countries that fail to demonstrate adequate security measures may face trade restrictions or sanctions.
Biden’s executive order on supply chain security is a smart move, addressing the critical need for better cyber threat sharing. However, companies need to be aware of vulnerabilities like those found in Microsoft Azure Cosmos DB, detailed in Azure Cosmos DB Vulnerability Details. Understanding these weaknesses is crucial for bolstering overall security, aligning with the goals of the executive order.
This comprehensive approach to security is essential in today’s interconnected world.
Potential Long-Term Impact on the Global Economy
The executive order has the potential to significantly impact the global economy. Improved supply chain security can lead to increased trade volume and reduced transaction costs. Increased resilience can reduce the risk of global economic shocks, promoting stability and growth. A secure global trading system, fostered by shared responsibility, will promote global economic prosperity. However, the order’s implementation and enforcement will be crucial for its successful impact.
The success of the order hinges on effective cooperation and adherence to global standards.
Stakeholder Perspectives: Joe Biden Signs Executive Order To Bolster Supply Chain Security With Cyber Threat Sharing
The Biden administration’s executive order on bolstering supply chain security with cyber threat sharing has sparked diverse reactions across various stakeholder groups. Businesses, consumers, and government agencies all have unique perspectives shaped by their specific interests and concerns. Understanding these varied viewpoints is crucial for assessing the potential impact and success of this initiative.The executive order aims to enhance resilience in the face of cyberattacks, but its effectiveness depends heavily on how different stakeholders adapt and engage.
Biden’s executive order on strengthening supply chain security through cyber threat sharing is a crucial step. It’s all about making our systems more resilient, but the Department of Justice Offers Safe Harbor for MA Transactions ( Department of Justice Offers Safe Harbor for MA Transactions ) highlights another important angle. Ultimately, these measures work together to improve overall security, bolstering the nation’s resilience against various threats.
This section explores those perspectives, highlighting both support and criticism.
Business Perspectives
Businesses are a key part of the supply chain and have a vested interest in its security. Many businesses are likely to support the executive order, recognizing the potential for increased protection against cyberattacks and the related disruptions. However, concerns exist regarding the administrative burden and the potential for increased costs associated with implementing new security measures. Some businesses might be apprehensive about the sharing of sensitive data, fearing competitive disadvantage or breaches of confidentiality.
- Reports from industry associations often cite the need for stronger cybersecurity measures and express support for initiatives like this. They frequently highlight the financial and reputational risks associated with supply chain disruptions caused by cyberattacks.
- Conversely, some small and medium-sized enterprises (SMEs) may struggle to afford the necessary investments in cybersecurity infrastructure and personnel, potentially creating a disparity in the effectiveness of the order across different business sizes.
Consumer Perspectives
Consumers, as end-users of products and services, are indirectly impacted by supply chain security. Increased security measures can lead to potential price increases, but consumers generally benefit from the stability and availability of goods. Consumer confidence in the supply chain and the ability of the government to address cyber threats plays a role in their perception. The availability of information about the order’s impact on prices and product availability will shape consumer sentiment.
- Consumer reports may reflect concerns about potential price increases or product shortages if implementing stronger security measures adds costs or delays to the production process. These concerns, however, might be overshadowed by a desire for increased safety and reliability.
- Public awareness campaigns can significantly impact consumer perception by highlighting the benefits of the executive order in protecting consumers from potentially harmful products or disruptions to their daily lives.
Government Agency Perspectives
Government agencies, particularly those responsible for cybersecurity and economic security, are likely to support the executive order. Their perspectives focus on the broader national security implications of supply chain vulnerabilities. They are likely to emphasize the need for collaboration and information sharing between public and private sectors.
- Government agencies may express concerns about the complexities of implementing the order across various sectors and ensuring compliance with existing regulations.
- They might also highlight the importance of international cooperation in addressing global cyber threats affecting supply chains.
Diverse Stakeholder Perspectives
“Stakeholder perspectives on the executive order vary widely, with businesses emphasizing cost-effectiveness, consumers concerned about price increases, and government agencies prioritizing national security. The success of this initiative hinges on a balance between these often-conflicting priorities.”
Case Studies of Supply Chain Vulnerabilities

Supply chains, intricate networks of interconnected businesses, are increasingly vulnerable to disruptions. Understanding these vulnerabilities is critical to developing robust security measures. The following case studies highlight specific instances where weaknesses in supply chains have led to significant consequences, illustrating the need for proactive risk management.
Specific Examples of Supply Chain Vulnerabilities
Supply chain vulnerabilities manifest in various ways, from simple human error to sophisticated cyberattacks. These vulnerabilities can stem from inadequate security protocols, weak vendor management, or a lack of transparency in the supply chain itself. Understanding these different types of vulnerabilities is crucial for preventing similar disruptions in the future.
- The 2013 Sony PlayStation Network Breach: This incident highlighted the vulnerability of networked systems within a complex supply chain. The attack, originating from outside the company, leveraged weaknesses in security protocols and vendor management practices, leading to a massive data breach and substantial financial losses for Sony.
- The 2021 Colonial Pipeline Attack: This ransomware attack disrupted the US fuel supply chain, leading to widespread panic and gas shortages. The attack underscored the vulnerability of critical infrastructure to cyberattacks and the ripple effect such disruptions can have on the economy and daily life.
- The 2020 COVID-19 Pandemic’s Impact: The global pandemic dramatically exposed the fragility of supply chains reliant on specific regions or countries. Disruptions in manufacturing, transportation, and logistics created widespread shortages of essential goods, highlighting the need for diversified and resilient supply chains.
Nature and Consequences of Vulnerabilities
Vulnerabilities in supply chains often manifest as disruptions in the flow of goods and services. These disruptions can have severe consequences, impacting not only businesses but also consumers and the overall economy. The consequences can range from financial losses to reputational damage and even threats to public health and safety.
- Financial Losses: Disruptions can result in lost revenue, increased costs, and damage to brand reputation. The Sony PlayStation Network breach, for example, resulted in significant financial losses and a decline in consumer confidence.
- Reputational Damage: A major disruption can severely damage a company’s reputation. Consumers may lose trust in the company and its ability to deliver quality products or services reliably.
- Disruptions to Public Services: Disruptions to critical infrastructure, like the Colonial Pipeline attack, can have a significant impact on public services and daily life.
Measures to Mitigate Similar Risks
Proactive measures are crucial to mitigate the risk of supply chain disruptions. These measures involve a multifaceted approach, including improved security protocols, robust vendor management practices, and increased transparency throughout the supply chain.
- Strengthening Cybersecurity Measures: Implementing robust cybersecurity protocols, including regular security assessments, penetration testing, and employee training, is crucial to preventing cyberattacks. Regular audits and security updates can also help to prevent many issues.
- Enhanced Vendor Management: Carefully vetting and monitoring vendors is essential. Thorough background checks and security assessments can help identify and mitigate potential risks.
- Diversification of Supply Sources: Reducing reliance on a single supplier can enhance resilience. Diversifying sources minimizes the impact of disruptions in one location.
Impacts of Past Supply Chain Disruptions
The consequences of supply chain disruptions can be far-reaching and long-lasting. The 2020 COVID-19 pandemic highlighted the vulnerability of global supply chains to unforeseen events.
- Economic Instability: Disruptions can lead to economic instability, impacting businesses and consumers alike. Increased costs and shortages of goods can contribute to inflation and economic uncertainty.
- Consumer Impacts: Consumers face higher prices, reduced availability of goods, and potential shortages of essential products. This was clearly seen during the pandemic.
- Geopolitical Tensions: Supply chain disruptions can exacerbate geopolitical tensions, particularly when countries become reliant on specific suppliers.
Ultimate Conclusion

In conclusion, Biden’s executive order represents a critical step in fortifying the nation’s supply chains against cyber threats. It highlights the need for robust public-private partnerships, proactive risk mitigation, and a comprehensive approach to ensuring resilience. The order’s success hinges on effective implementation and continuous adaptation to the evolving cyber landscape. This is a significant moment in supply chain security, marking a shift toward a more proactive and collaborative approach.
Essential Questionnaire
What are some examples of past cyberattacks targeting critical infrastructure?
Several high-profile attacks have targeted critical infrastructure, demonstrating the severity of these threats. These incidents highlight the vulnerability of systems and the need for proactive security measures. Examples include attacks on power grids, water systems, and financial institutions.
What are the potential negative impacts of this executive order?
While the order aims to enhance security, there’s a potential for increased costs and regulatory burdens for businesses. The increased scrutiny and compliance requirements could impact operational efficiency and potentially slow down some supply chain processes.
How will this executive order impact international trade relations?
The executive order could potentially influence international trade relations by setting a precedent for supply chain security standards. This could lead to collaborations and agreements with other countries to address similar vulnerabilities.
What are some mitigating strategies for the potential negative impacts on different industries?
Mitigating strategies can include investments in robust cybersecurity systems, regular vulnerability assessments, and enhanced employee training. Implementing security protocols, developing incident response plans, and fostering collaboration among stakeholders are crucial in addressing potential disruptions.