
The landscape of open-weights artificial intelligence underwent a significant transformation with Google’s recent unveiling of the Gemma 4 model family. This release represents a pivotal moment for developers and organizations seeking to deploy sophisticated, agentic AI systems within local environments. Unlike previous iterations of large language models (LLMs) that functioned primarily as isolated text generators, the Gemma 4 architecture is engineered from the ground up to support native tool calling. This capability allows the model to interact with external APIs, execute code, and retrieve real-time data, effectively bridging the gap between static internal knowledge and the dynamic, ever-changing digital world. By leveraging the Ollama inference engine alongside the lightweight Gemma 4:e2b variant, practitioners can now build high-performance, privacy-centric agents that operate entirely on consumer-grade hardware without the need for cloud-based subscriptions or data-sharing agreements.
The Evolution of the Gemma Ecosystem
The Gemma 4 family is built upon the same research and technology used to create Google’s Gemini models. This lineage provides the open-weights community with access to frontier-level capabilities under a permissive Apache 2.0 license. This licensing choice is a critical factor for the industry, as it grants machine learning engineers complete control over their infrastructure, data privacy, and fine-tuning processes.
The family is categorized into several distinct variants tailored for different use cases. At the top of the spectrum is the 31B parameter-dense model, designed for high-reasoning tasks and complex problem-solving. Alongside it sits the 26B Mixture of Experts (MoE) model, which utilizes a specialized architecture to activate only a fraction of its parameters during any given inference cycle, thereby optimizing computational efficiency without sacrificing intelligence. For the purposes of local deployment and edge computing, the 2B "Edge" variant (gemma4:e2b) has emerged as a standout performer. Despite its smaller footprint, it retains the multimodal properties and structured output capabilities of its larger siblings, making it an ideal candidate for responsive, local agents.
Understanding the Mechanism of Tool Calling
Historically, language models have been "closed-loop" systems. Their responses were limited by their training data cutoff, leading to apologies or hallucinations when asked about current events, live market rates, or specific sensor data. Tool calling, also known as function calling, is the architectural solution to this limitation. It transforms a model from a conversationalist into an autonomous agent capable of logical reasoning followed by action.
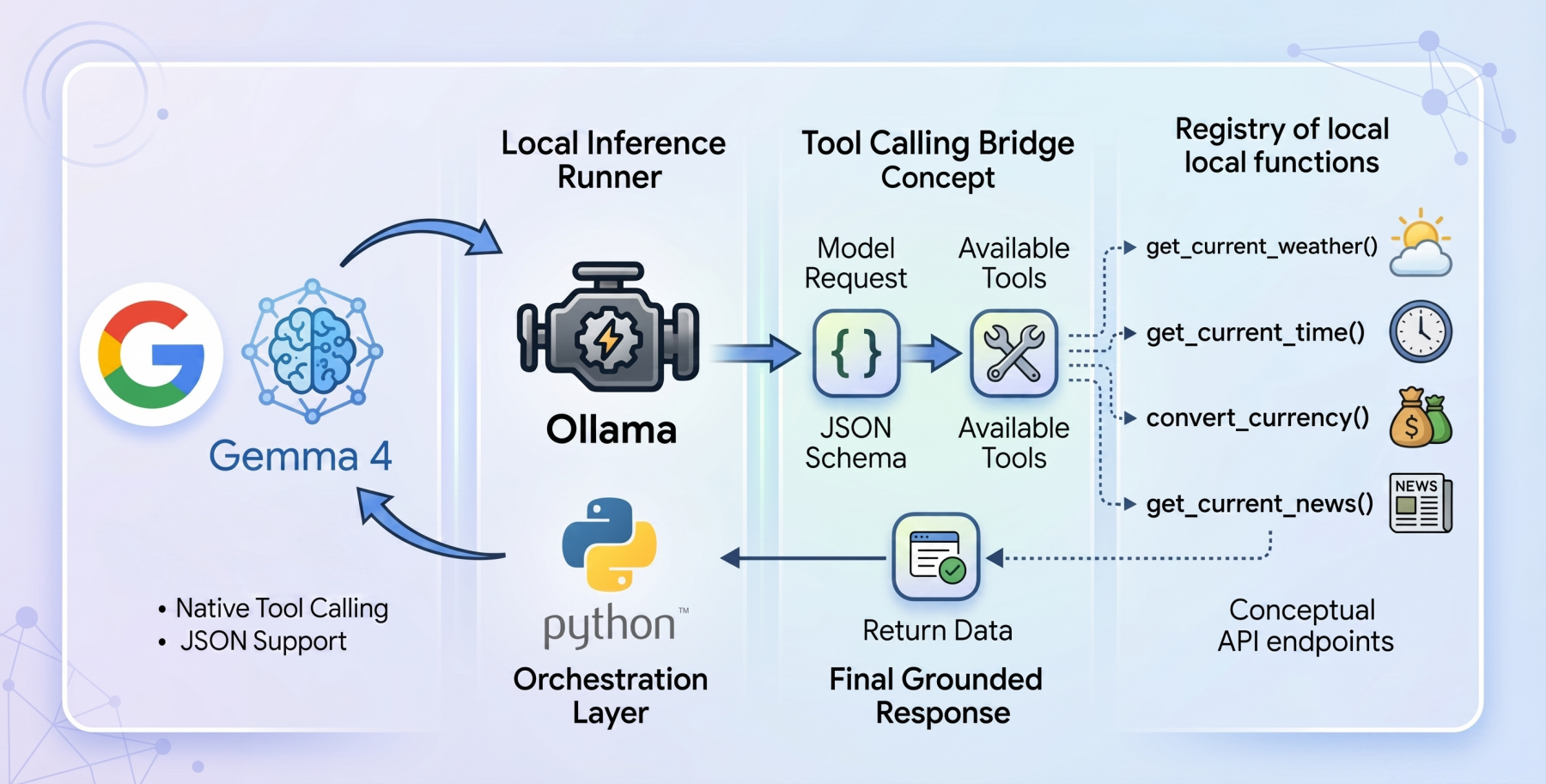
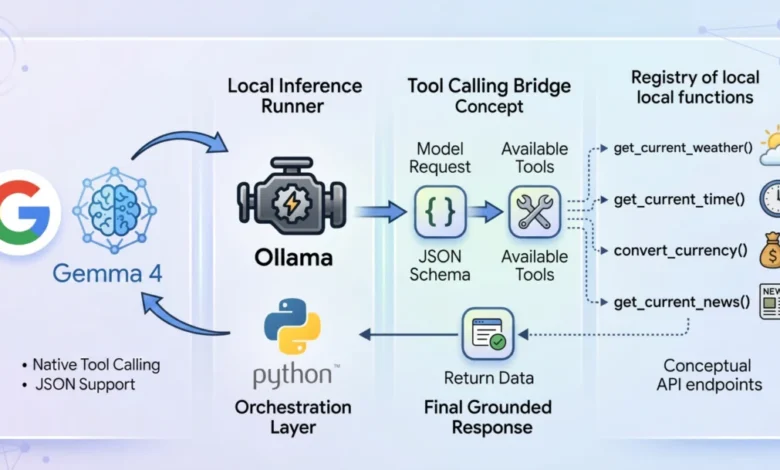
In a tool-calling workflow, the model is provided with a registry of available programmatic tools defined via JSON schemas. When a user issues a prompt, the model does not immediately generate a final answer. Instead, it evaluates whether any of the provided tools are necessary to fulfill the request. If a tool is required, the model pauses its standard inference process and generates a structured JSON object containing the function name and the necessary arguments. The host application intercepts this request, executes the actual code (such as a Python function or an API call), and returns the result to the model. Finally, the model synthesizes this new context to provide a grounded, accurate response to the user.
Technical Foundations: Ollama and Gemma 4:e2b
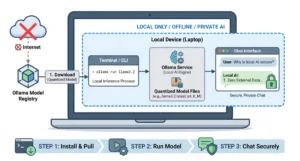
To implement a local tool-calling system, developers are increasingly turning to Ollama, an open-source tool that simplifies the deployment of LLMs on macOS, Linux, and Windows. Ollama handles the complexities of GPU acceleration and memory management, allowing users to run models with a single command.
The choice of the gemma4:e2b model is particularly strategic for local applications. Engineered specifically for mobile devices and Internet of Things (IoT) integrations, this model achieves near-zero latency execution. In a local environment, latency is often the primary barrier to a seamless user experience. By utilizing a 2-billion parameter footprint, the system can provide instantaneous feedback while maintaining strict data privacy, as no information ever leaves the local machine. This "local-first" approach eliminates API costs and rate limits, which are common pain points when using proprietary models from providers like OpenAI or Anthropic.
Architectural Implementation and Workflow
A robust tool-calling agent requires a clean, modular architecture. A "zero-dependency" philosophy—using only standard Python libraries such as urllib and json—is often preferred for such implementations. This ensures maximum portability and transparency, avoiding the "black box" issues sometimes associated with heavy orchestration frameworks.
The process begins with the definition of the tools. For example, a weather retrieval tool involves a Python function that interacts with a service like the Open-Meteo API. Because most weather APIs require latitude and longitude rather than city names, the function must perform a two-stage resolution: first geocoding the city name into coordinates, and then fetching the meteorological data.
Crucially, the model must be "aware" of this function. This is achieved by creating a JSON schema that describes the function’s name, its purpose, and the specific parameters it requires (including data types and required fields). This schema acts as a guide for the Gemma 4 weights, ensuring that the model generates syntax-perfect calls that the Python environment can execute without error.
The Multi-Step Inference Cycle
The execution of a tool-calling request follows a specific chronology:
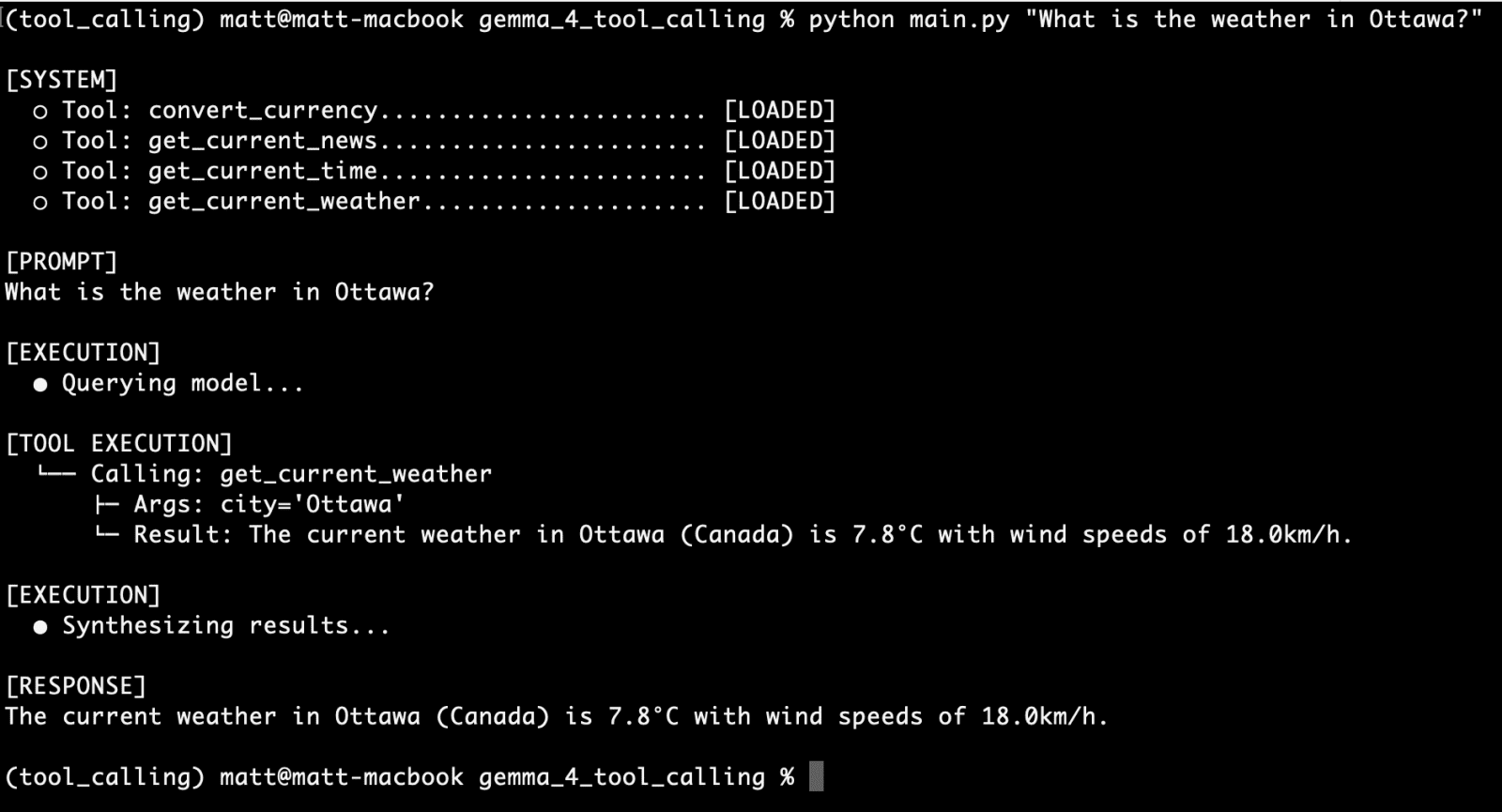
- Initial Prompt: The user asks a question, such as "What is the current weather in Tokyo?"
- Tool Evaluation: The application sends the user query and the tool registry to Gemma 4 via the Ollama API.
- Structured Request: The model recognizes the need for the
get_current_weathertool and outputs a JSON object:"function": "get_current_weather", "arguments": "city": "Tokyo". - Local Execution: The Python script parses this JSON, runs the corresponding function, and retrieves the real-time weather data.
- Context Injection: The tool’s output (e.g., "15°C and sunny") is appended to the conversation history with a "tool" role.
- Final Synthesis: The updated history is sent back to the model. Gemma 4 reads the real-time data and formulates a natural language response: "The current weather in Tokyo is 15°C and sunny."
This secondary interaction—sending the tool results back to the model—is what allows the agent to bridge the gap between raw data and human-readable information.
Expanding Agent Capabilities
Once the foundational architecture is in place, the utility of the agent can be expanded by adding modular functions. In recent testing and development cycles, several key tools have proven highly effective when paired with Gemma 4:
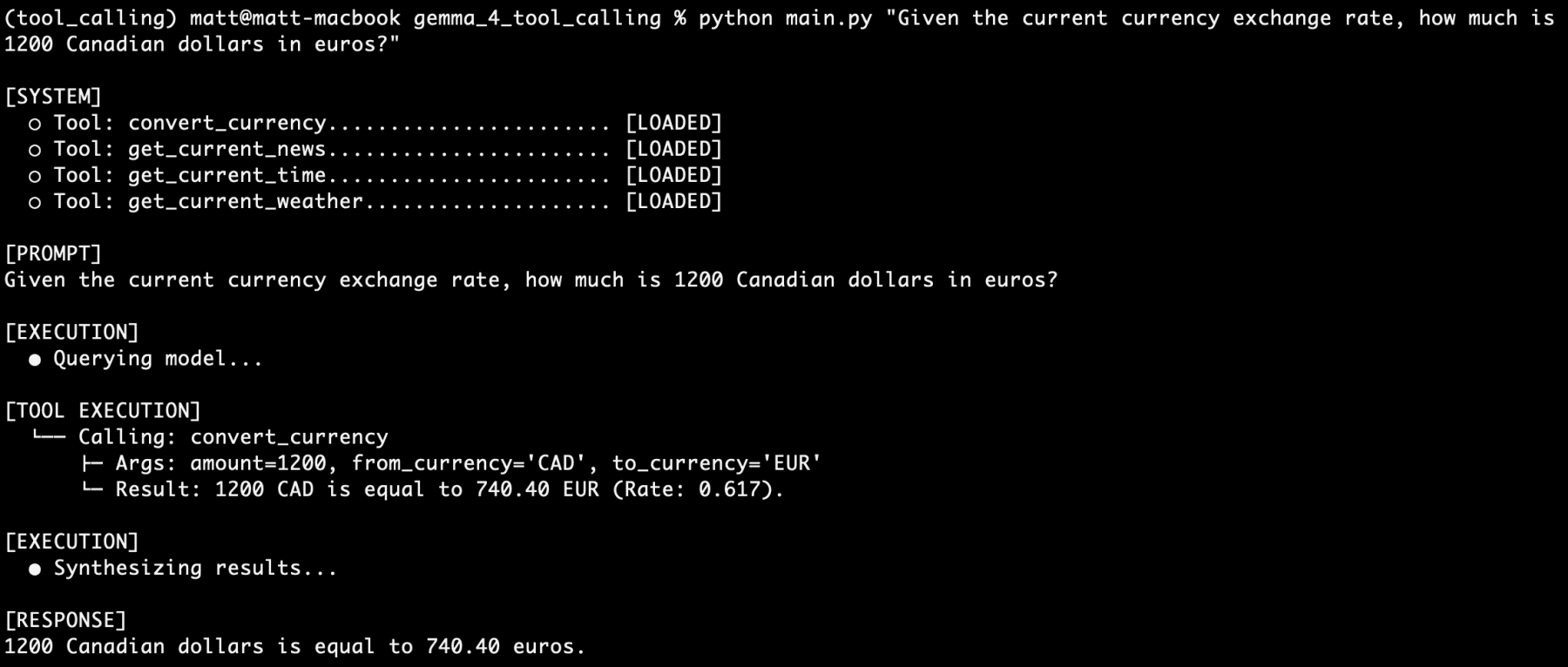
- Currency Conversion: By connecting to financial APIs, the agent can provide real-time exchange rates, allowing users to perform complex financial calculations within a natural language interface.
- Time Zone Management: A simple tool to retrieve the current time in any global city helps the agent assist with scheduling and international logistics.
- Live News Integration: By scraping or calling news aggregators, the model can provide summaries of the latest events, overcoming the static nature of its original training weights.
Testing has shown that the Gemma 4:e2b model is remarkably resilient when handling "stacked" requests. In scenarios where a user asks four different questions involving four different tools in a single prompt (e.g., asking for the time, weather, currency rate, and news for a specific destination), the model successfully triggers all four tool calls in sequence or parallel, synthesizing the data into a single, cohesive response.
Performance Analysis and Industry Implications
The reliability of Gemma 4 in tool-calling tasks marks a significant milestone for small language models (SLMs). In extensive testing involving hundreds of prompts, the model’s reasoning engine demonstrated a near-zero failure rate for structured output. This reliability is essential for developers building production-ready applications where a single malformed JSON object can crash a workflow.
The implications for the broader AI industry are profound. As models become smaller and more efficient, the reliance on centralized cloud providers diminishes. This shift empowers individual developers and small enterprises to build sophisticated AI assistants that are cost-effective and secure. Furthermore, the ability to run these systems on edge devices opens new possibilities in sectors such as healthcare, where data privacy is paramount, and industrial IoT, where low latency is a requirement for real-time monitoring and control.
Conclusion
The release of the Gemma 4 model family, combined with the accessibility of Ollama, has democratized the creation of agentic AI systems. By moving beyond simple text generation and embracing native tool calling, Google has provided a blueprint for the next generation of local, private-first applications. As developers continue to enrich these models with diverse sets of tools—ranging from file system access to advanced data processing logic—the distinction between local AI and cloud-tier hardware will continue to blur. The era of the truly autonomous, local AI agent has arrived, driven by the efficiency and reasoning power of the Gemma 4 ecosystem.





{kind=link}