
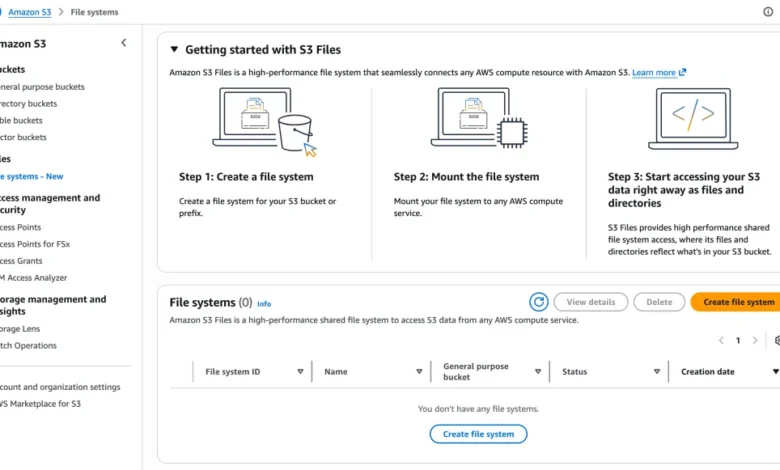
Amazon Web Services (AWS) has unveiled Amazon S3 Files, a groundbreaking new service that fundamentally alters the landscape of cloud storage by bridging the long-standing divide between object storage and traditional file systems. This innovative offering allows any AWS compute resource to seamlessly access data stored in Amazon Simple Storage Service (S3) as a fully-featured, high-performance file system. The announcement marks a significant step forward, eliminating the need for customers to choose between the cost-effectiveness and durability of S3 and the interactive capabilities of file systems.
Historically, cloud architects and developers have grappled with the distinct characteristics of object storage and file systems. Object storage, exemplified by S3, treats data as discrete units called objects, each with associated metadata, and is ideal for large-scale data lakes, backups, and archival. In contrast, file systems, familiar from operating systems like Windows and Linux, organize data into hierarchical directories and files, supporting in-place modifications and random access, crucial for many applications. The distinction, often explained with analogies such as comparing S3 objects to books in a library (requiring replacement of the entire book for any change) versus files on a local drive (allowing page-by-page editing), has historically necessitated complex data management strategies and architectural trade-offs.
Amazon S3 Files directly addresses this dichotomy. It transforms S3 buckets into accessible file systems, ensuring that modifications made at the file system level are automatically reflected in the S3 bucket, with fine-grained control over synchronization. A key advantage is the ability to attach a single S3 file system to multiple compute resources simultaneously. This enables efficient data sharing across clusters without the need for data duplication, a common bottleneck and cost driver in traditional cloud architectures.

Eliminating the Storage Trade-off
For over a decade, users have been compelled to make a critical decision: prioritize the cost-effectiveness, unparalleled durability, and broad service integration of Amazon S3, or opt for the interactive, byte-level manipulation capabilities of a file system. S3 Files effectively eliminates this trade-off. It positions Amazon S3 as the central, unified repository for an organization’s data, accessible directly from any AWS compute instance, whether it be Amazon Elastic Compute Cloud (EC2) instances, containers running on Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS), or serverless AWS Lambda functions. This unified approach is poised to accelerate workflows across a wide spectrum of applications, from high-volume production environments to the demanding computational needs of machine learning model training and the emergent field of agentic AI systems.
Technical Capabilities and Performance
Amazon S3 Files supports access to any general-purpose S3 bucket as a native file system. This functionality is available on EC2 instances, containers orchestrated by ECS and EKS, and even within Lambda functions. The file system presents S3 objects as standard files and directories, fully supporting all operations defined by the Network File System (NFS) v4.1 and later protocols. This includes fundamental file operations such as creating, reading, updating, and deleting files.
Under the hood, S3 Files leverages Amazon Elastic File System (EFS) technology to deliver high performance. Active data experiences latencies of approximately 1 millisecond, providing a responsive experience for interactive workloads. The system is designed for concurrent access from multiple compute resources, offering NFS close-to-open consistency. This makes it particularly well-suited for shared, data-mutating workloads, ranging from sophisticated agentic AI agents collaborating through file-based tools to large-scale machine learning training pipelines that continuously process vast datasets.
When users interact with specific files and directories through the S3 Files interface, the associated metadata and content are intelligently managed. Data that benefits from low-latency access is automatically stored and served from the file system’s high-performance storage layer. For files requiring large sequential reads, S3 Files bypasses the high-performance storage and serves data directly from Amazon S3, optimizing for throughput. Furthermore, for byte-range reads, only the specific bytes requested are transferred, significantly minimizing data movement and associated costs.

The system also incorporates intelligent pre-fetching capabilities, designed to anticipate data access needs and proactively load relevant data. Users retain fine-grained control over which data is staged on the file system’s high-performance storage. Options to load full file data or metadata only allow for optimization tailored to specific access patterns, enhancing efficiency and cost management.
Getting Started: A Practical Demonstration
AWS has provided a straightforward path for users to begin utilizing S3 Files. The process involves creating an S3 file system and mounting it to an EC2 instance, enabling direct interaction with S3 data using familiar file system commands.
For a demonstration, an EC2 instance and a pre-existing general-purpose S3 bucket are required. The process can be initiated via the AWS Management Console, the AWS Command Line Interface (AWS CLI), or through infrastructure as code (IaC) tools.
Step 1: Create an S3 File System
Within the Amazon S3 section of the AWS Management Console, users navigate to "File systems" and select "Create file system." The user then specifies the name of the S3 bucket they wish to expose as a file system.
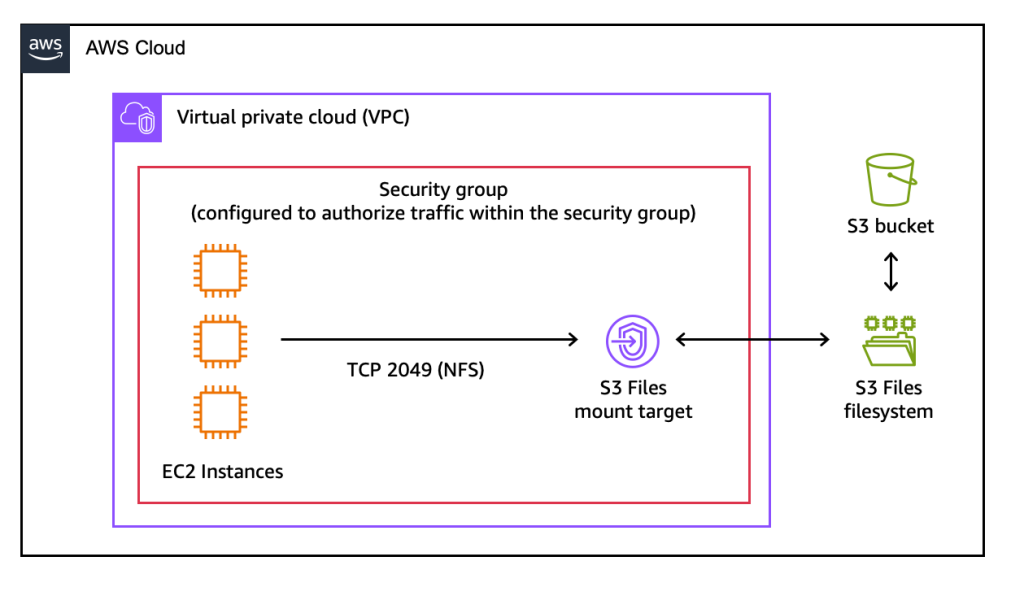
Step 2: Discover the Mount Target
A mount target is a network endpoint residing within the user’s Virtual Private Cloud (VPC) that facilitates access from EC2 instances to the S3 file system. The console automatically provisions these mount targets. Users can then note the "Mount target ID" from the "Mount targets" tab. For CLI users, creating the file system and its mount targets requires two distinct commands: create-file-system followed by create-mount-target.
Step 3: Mount the File System on an EC2 Instance
Once the EC2 instance is configured, the file system can be mounted using standard Linux commands. For example:
sudo mkdir /home/ec2-user/s3files
sudo mount -t s3files fs-0aa860d05df9afdfe:/ /home/ec2-user/s3files
After mounting, users can interact with their S3 data directly within the mounted directory (~/s3files) using conventional file operations. Updates made to files within the mounted file system are automatically synchronized back to the S3 bucket as new objects or new versions of existing objects, typically within minutes. Conversely, changes made directly to objects in the S3 bucket are reflected in the mounted file system within seconds to a minute.
A practical example demonstrates this synchronization:
# Create a file on the EC2 file system
echo "Hello S3 Files" > s3files/hello.txt
# Verify its presence and metadata
ls -al s3files/hello.txt
# Output will show the file with correct permissions and size
# Confirm the file's existence in the S3 bucket
aws s3 ls s3://s3files-aws-news-blog/hello.txt
# Output will display the file's timestamp, size, and name
# Download the file from S3 and verify its content
aws s3 cp s3://s3files-aws-news-blog/hello.txt . && cat hello.txt
# Output will be "Hello S3 Files"Differentiating S3 Files from Other AWS File Services
AWS offers a suite of storage and file services, leading to common questions about selecting the appropriate solution for specific workloads. S3 Files is positioned to complement, rather than replace, existing services like Amazon EFS and Amazon FSx.
S3 Files is specifically designed for scenarios requiring interactive, shared access to data residing in Amazon S3 via a high-performance file system interface. It excels in environments where multiple compute resources need to read, write, and collaboratively mutate data. This includes production applications, agentic AI systems utilizing Python libraries and CLI tools, and machine learning training pipelines. The benefits include shared access across compute clusters without data duplication, low-latency access, and seamless synchronization with S3.
For organizations migrating from on-premises Network Attached Storage (NAS) environments, Amazon FSx provides a familiar set of features and compatibility. Amazon FSx is also the preferred choice for high-performance computing (HPC) and GPU cluster storage, particularly with Amazon FSx for Lustre. It further caters to specialized needs with options like Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS, and Amazon FSx for Windows File Server, offering distinct file system capabilities tailored to specific enterprise requirements. Amazon EFS, on the other hand, provides a fully managed, elastic NFS file system that scales to petabytes and can be accessed concurrently by thousands of EC2 instances, suitable for a broad range of cloud-native applications. S3 Files, by integrating directly with S3, offers a unique value proposition for workloads that have historically been constrained by the object-to-file interface.
Pricing and Availability
Amazon S3 Files is available immediately in all commercial AWS Regions. The pricing model is designed to be transparent and cost-effective. Customers will incur charges for the portion of data stored within their S3 file system, for read and write operations performed on the file system, and for S3 requests associated with data synchronization between the file system and the S3 bucket. Detailed pricing information can be found on the Amazon S3 pricing page.
Broader Implications and Future Outlook
The introduction of Amazon S3 Files represents a significant architectural shift, potentially simplifying cloud deployments by dismantling data silos, reducing synchronization complexities, and eliminating manual data movement between object and file formats. For developers building agentic AI systems that rely on file-based libraries and shell scripts, or for data scientists preparing datasets for machine learning, this new capability offers direct, interactive access to S3 data. It removes the friction of choosing between the robust durability and cost advantages of S3 and the interactive, hierarchical capabilities of a file system.
This development underscores AWS’s commitment to continuous innovation in cloud storage, aiming to provide customers with the flexibility and performance required to drive forward-thinking applications. By enabling Amazon S3 to function as a central, universally accessible data repository, AWS is empowering organizations to build more agile, efficient, and scalable solutions. The ability to access data directly from any AWS compute instance, container, or function, without compromising on durability or cost, is expected to accelerate adoption of cloud-native architectures and unlock new possibilities for data-intensive workloads.
For those looking to explore this new functionality, the S3 Files documentation provides comprehensive guidance. AWS encourages users to share their experiences and feedback on how this capability is transforming their cloud strategies.








{kind=link}