
Bir Tawil: The Unclaimed Land at the Heart of a Geopolitical Paradox Between Egypt and Sudan
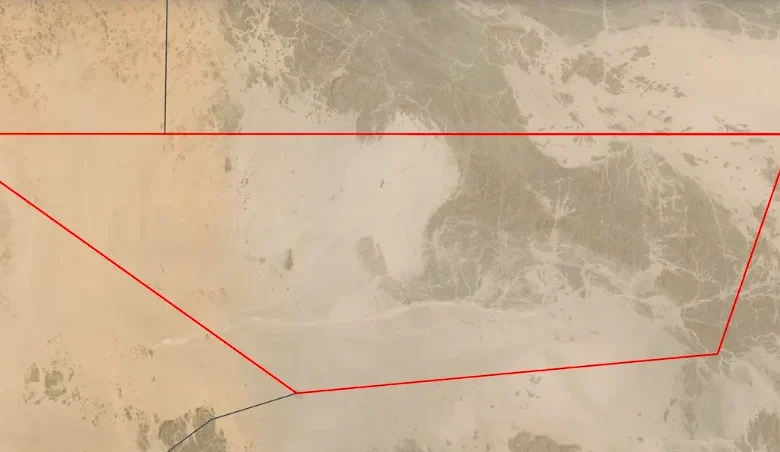
In a world where virtually every square meter of land is meticulously mapped, claimed, and frequently contested, there exists a stark anomaly: Bir Tawil. This desolate, rhomboid-shaped territory, spanning approximately 2,060 square kilometers (795 sq mi) between Egypt and Sudan, stands as one of the last true terra nullius—land belonging to no one—on Earth. Unlike almost every other border dispute globally, where nations fiercely assert sovereignty, Bir Tawil remains unclaimed by either of its two adjacent states, Egypt and Sudan, due to a convoluted colonial legacy and a strategic game of diplomatic chess. Its very existence highlights the profound complexities of international borders, the enduring shadows of colonial administration, and the surprising role that perceived value plays in territorial claims.
Historical Roots of the Dispute: A Colonial Legacy
The enigmatic status of Bir Tawil is not a natural phenomenon but a direct consequence of historical cartographic and administrative decisions made during the Anglo-Egyptian Condominium (1899-1956), a period when Britain and Egypt jointly administered Sudan. This dual administration laid the groundwork for the modern border dispute that continues to shape the region.
The initial agreement, signed in 1899, established the political boundary between Egypt and Sudan as the 22nd parallel north. Under this definitive line, Bir Tawil was unequivocally placed within Sudan, while a much larger, more valuable triangular area to its east, known as the Hala’ib Triangle, was positioned within Egypt. This 1899 boundary was intended to be the final and official demarcation of sovereignty.
However, just three years later, in 1902, the British, acting alone for administrative convenience, introduced a second, separate boundary. This new line, often referred to as the "administrative boundary," deviated significantly from the 22nd parallel. Its primary purpose was to facilitate the governance of nomadic tribes, ensuring that they were administered by the authority geographically closer to their traditional grazing grounds and centers of influence. Specifically, the 1902 line placed the Ababda tribe, who traditionally roamed the Bir Tawil area, under Egyptian administration, despite the 1899 line placing Bir Tawil in Sudan. Conversely, the Beja tribes, predominantly inhabiting the Hala’ib Triangle, were placed under Sudanese administration, despite the 1899 line placing Hala’ib in Egypt. This administrative adjustment meant that Bir Tawil was transferred to Egyptian administrative control, and the Hala’ib Triangle to Sudanese administrative control, effectively creating two different interpretations of the border.
The critical distinction here is that the 1902 line was never intended to alter the sovereignty established by the 1899 agreement. It was purely an administrative measure, designed for practical governance, not a redefinition of national borders. However, this administrative convenience would sow the seeds of a deep-seated and enduring geopolitical paradox once Sudan gained independence.
Post-Independence Dilemma: The Birth of Terra Nullius
When Sudan achieved full independence from the Anglo-Egyptian Condominium in 1956, it immediately asserted its claim to the territory based on the 1902 administrative boundary. This meant Sudan claimed the Hala’ib Triangle, which the 1902 line placed under its administration. Egypt, on the other hand, maintained that the legitimate border was the 1899 political boundary, which placed Hala’ib within its territory.
The core of the Bir Tawil paradox lies in the mutually exclusive nature of these claims. For either Egypt or Sudan to claim Bir Tawil, they would effectively have to relinquish their claim to the Hala’ib Triangle, a territory of far greater strategic and economic significance.
- If Egypt were to claim Bir Tawil based on the 1902 administrative line (which placed Bir Tawil under Egyptian administration), it would simultaneously have to accept the 1902 line as the legitimate border, thereby surrendering its claim to the Hala’ib Triangle, which the same 1902 line places in Sudan.
- Conversely, if Sudan were to claim Bir Tawil based on the 1899 political line (which places Bir Tawil in Sudan), it would simultaneously have to accept the 1899 line as the legitimate border, thereby surrendering its claim to the Hala’ib Triangle, which the same 1899 line places in Egypt.
Neither nation is willing to make such a concession. Consequently, both Egypt and Sudan adamantly claim the Hala’ib Triangle (Egypt based on 1899, Sudan based on 1902) but steadfastly refuse to claim Bir Tawil. This unique stalemate leaves Bir Tawil in a state of limbo, truly belonging to no sovereign nation.
The Hala’ib Triangle: A Desirable Counterpart
To fully grasp why Bir Tawil is shunned, one must understand the immense value attributed to its counterpart, the Hala’ib Triangle. This 20,580 square kilometer (7,946 sq mi) region, roughly ten times the size of Bir Tawil, is a stark contrast in desirability.
The Hala’ib Triangle’s strategic importance is multifaceted:
- Red Sea Coastline: It boasts a significant stretch of coastline along the Red Sea, a vital global shipping lane. This provides access to maritime trade, potential port development, and naval strategic positioning.
- Resource Potential: The area is believed to hold significant mineral wealth, including gold, manganese, and iron ore. There have also been persistent rumors, though unconfirmed with definitive data, of offshore oil and natural gas reserves in the Red Sea waters adjacent to Hala’ib, making it a potentially lucrative territory.
- Fishing Rights: Control over the Red Sea coastline also entails valuable fishing rights in biologically rich waters.
- Population Centers: Unlike Bir Tawil, Hala’ib has several small towns and villages, including the main town of Halayeb, Abu Ramad, and Shalateen, indicating a more established human presence and economic activity.
- Tourism Potential: Its coastal location and unique desert-meets-sea landscape also offer potential for tourism development, particularly diving and eco-tourism.
Given these attributes, it is unsurprising that both Egypt and Sudan are locked in a continuous diplomatic and, at times, military standoff over Hala’ib. Egypt has maintained effective control over the territory since the mid-1990s, deploying military forces and integrating the area into its administrative system, much to the chagrin of Sudan, which continues to issue formal protests and refer the matter to international bodies. The strategic and economic calculus for Hala’ib is clear; the lack of such calculus for Bir Tawil is equally clear.
Bir Tawil: A Landscape of Extreme Isolation
In stark contrast to the sought-after Hala’ib, Bir Tawil is an epitome of desolation. Situated deep within the hyper-arid Nubian Desert, its geography and climate make it one of the most inhospitable places on Earth.
- Geography and Climate: The region is characterized by vast expanses of rocky desert, sand dunes, and low, rugged mountains. The most prominent feature is Jabal Bir Tawil (1,428 m), a mountain in the south-east, and Jabal Hadarba (612 m) in the north-east. The climate is unforgivingly hot and dry, with average daily temperatures frequently exceeding 40°C (104°F) for much of the year and often soaring past 50°C (122°F) during the summer months. Rainfall is negligible, averaging less than 50 millimeters (2 inches) annually, making it one of the driest places globally. There are no permanent rivers, lakes, or oases.
- Demographics and Infrastructure: Predictably, Bir Tawil has no permanent settlements, towns, or villages. It lacks any discernible infrastructure—no roads, power grids, communication networks, or established water sources. The only human presence is fleeting, primarily consisting of nomadic Ababda Bedouin tribes who occasionally traverse the area in search of grazing land for their camels and goats, or, less frequently, illegal miners prospecting for gold. These visits are temporary, driven by necessity, and underscore the region’s inability to sustain a permanent population.
- Lack of Economic Potential: There are no known significant mineral deposits, oil reserves, or agricultural land that could make Bir Tawil economically viable. Its extreme environment renders large-scale development impossible with current technology and economic incentives. This absolute lack of strategic or economic value is the primary, pragmatic reason why neither Egypt nor Sudan wishes to claim it. To claim Bir Tawil would be to accept a barren, costly, and resource-depleted territory, while simultaneously weakening their respective claims to the lucrative Hala’ib Triangle.
International Law and the Concept of Terra Nullius
Bir Tawil’s status as terra nullius is a fascinating case study in international law. Historically, the concept of terra nullius ("empty land" or "land belonging to no one") was primarily invoked by European colonial powers to justify their appropriation of lands inhabited by indigenous populations, arguing that these lands were "unoccupied" or "uncivilized" and therefore available for claim. This interpretation has been widely discredited and rejected in modern international law, particularly in light of decolonization and the recognition of indigenous rights.
In the contemporary context, terra nullius is exceptionally rare. Most unclaimed territories are either remote islands (e.g., Peter I Island, claimed by Norway but with limited international recognition) or areas covered by international treaties (e.g., Antarctica, governed by the Antarctic Treaty System which defers all territorial claims). Bir Tawil stands out as perhaps the only undisputed terra nullius that is not subject to a specific treaty regime or extreme geographical conditions like permanent ice caps.
The legal principle of uti possidetis juris, frequently applied to post-colonial states, dictates that new international boundaries should generally follow the administrative boundaries established by the colonial powers at the time of independence. This principle was intended to prevent endless border conflicts among newly independent nations. However, in the case of Bir Tawil and Hala’ib, the existence of two distinct colonial boundaries (1899 political and 1902 administrative) creates the intractable problem. Each nation selectively applies uti possidetis juris to the boundary that favors its claim to Hala’ib, thereby inadvertently creating the terra nullius status for Bir Tawil.
For any entity—be it a nation or an aspiring micro-nation—to legally claim Bir Tawil, it would need to satisfy several criteria under international law, particularly those outlined in the Montevideo Convention on the Rights and Duties of States (1933). These criteria include a defined territory, a permanent population, an effective government, and the capacity to enter into relations with other states. Given Bir Tawil’s lack of population, infrastructure, and an existing government, coupled with the political complexities of its location, any such claim would face insurmountable legal and diplomatic hurdles.
The Allure of the Unclaimed: Micro-Nation Attempts
Despite its legal ambiguities and harsh environment, Bir Tawil’s unique status has periodically captured the imagination of individuals seeking to create their own "nations." The most widely publicized attempt occurred in 2014 when Jeremiah Heaton, an American farmer from Virginia, traveled to Bir Tawil and planted a flag he designed, declaring the "Kingdom of North Sudan." His stated motivation was to fulfill his then seven-year-old daughter Emily’s wish to be a real princess.
Heaton’s widely publicized journey garnered significant media attention, but his declaration, while a romantic gesture, holds no legal weight in international law. For a claim of sovereignty to be recognized, it would require:
- Effective Occupation and Control: Demonstrating actual, continuous, and peaceful exercise of state functions over the territory. Given Bir Tawil’s conditions, this is practically impossible for an individual.
- Recognition by Other States: Crucially, a new state requires recognition from established sovereign states and international bodies like the United Nations. Without such recognition, any self-proclaimed "kingdom" remains merely a private endeavor.
- A Basis in Existing Law: Any claim would ideally need to be rooted in existing treaties, historical rights, or the principle of terra nullius applied in a way that is accepted by the international community and not contested by existing states. In Bir Tawil’s case, while it is terra nullius, a unilateral declaration by a private citizen does not meet the criteria for statehood.
Other individuals and groups have also made similar, albeit less publicized, attempts to claim Bir Tawil, often through online declarations or symbolic flag-plantings. All these efforts, however, share the same fate: they lack any form of international recognition and are generally dismissed as novelties rather than serious political undertakings. They highlight the enduring human fascination with unclaimed frontiers, even in the 21st century, but also underscore the rigorous and complex requirements for establishing a sovereign state.
Implications and Broader Context
Bir Tawil’s continued existence as an unclaimed territory offers several profound implications for international relations, law, and geopolitics:
- A Unique Geopolitical Anomaly: In an era of intense globalization, satellite mapping, and resource competition, Bir Tawil stands as a stark reminder that pockets of legal ambiguity and territorial neglect can still exist. It challenges the conventional understanding of a fully parceled and claimed world.
- Symbol of Complex Border Disputes: The Bir Tawil/Hala’ib conundrum serves as a potent example of how colonial-era administrative decisions, when combined with post-independence nationalist aspirations, can create intricate and intractable border disputes. It demonstrates that not all disputes are about outright conquest; some are about selective historical interpretations and strategic trade-offs.
- The Role of Value in Sovereignty: Perhaps the most significant lesson from Bir Tawil is the paramount importance of perceived strategic or economic value in territorial claims. Its absolute barrenness and lack of resources are its "protection" from being claimed. Had Bir Tawil possessed oil, fertile land, or a strategic port, it would undoubtedly be a hotly contested area, much like Hala’ib. This highlights the pragmatic, often self-interested, nature of national sovereignty.
- Challenges to International Law: While terra nullius is a rare concept, Bir Tawil forces a re-examination of how such areas are handled in modern international law. It poses questions about potential custodianship, environmental protection, or future resource discovery if the area were ever to reveal something valuable.
- Future Prospects: It is highly improbable that either Egypt or Sudan will claim Bir Tawil in the foreseeable future, as doing so would weaken their respective claims to the far more valuable Hala’ib Triangle. Nor is it likely that any private individual’s claim will ever achieve international recognition. Therefore, Bir Tawil is destined to remain a terra nullius, a silent testament to the enduring legacies of colonialism and the intricate calculations of geopolitical strategy.
In conclusion, Bir Tawil is far more than just a desolate strip of desert. It is a living, albeit barren, museum piece of geopolitical history, an enduring symbol of a unique border dispute, and a stark reminder that in the complex tapestry of international relations, sometimes the greatest paradox lies in what no one wants to claim. Its unclaimed status serves as a powerful illustration of how the absence of value, coupled with historical circumstance, can create one of the most singular territorial anomalies on the planet.








{kind=link}