
Structured Outputs vs. Function Calling: Navigating the Architectural Divide in Modern Language Model Systems
The evolution of Large Language Models (LLMs) from experimental conversationalists to the backbone of enterprise-grade software has necessitated a shift in how developers interact with these systems. Originally designed as text-in, text-out interfaces, models like GPT-4, Claude 3.5, and Gemini 1.5 are increasingly being utilized as reasoning engines within deterministic software pipelines. For machine learning practitioners and software engineers, the primary challenge has transitioned from generating human-like prose to ensuring that model outputs are predictable, machine-readable, and capable of triggering specific programmatic actions. To address this, the industry has converged on two primary architectural patterns: structured outputs and function calling. While these mechanisms frequently overlap in their use of JSON schemas, they represent fundamentally different approaches to model control and application logic.
The Paradigm Shift in Model Interaction
In the early stages of LLM development, obtaining structured data—such as a list of entities from a news article or a specific JSON object—relied heavily on the fragility of prompt engineering. Developers would append instructions such as "return only JSON" or "do not include conversational filler," only to find the model occasionally reverting to natural language, thereby breaking downstream data pipelines. This unpredictability served as a significant barrier to the deployment of autonomous agents in production environments where reliability is non-negotiable.
The introduction of native support for structured data and tool use by major API providers has fundamentally altered this landscape. Rather than hoping for compliance, developers can now enforce it through the model’s decoding process or its training data. Understanding the distinction between these two paths is critical for optimizing latency, reducing costs, and ensuring the architectural integrity of AI-driven applications.
The Technical Foundations: How They Work Under the Hood
To differentiate between structured outputs and function calling, one must examine the underlying mechanics of token generation and model training.
Structured Outputs and Grammar-Constrained Decoding
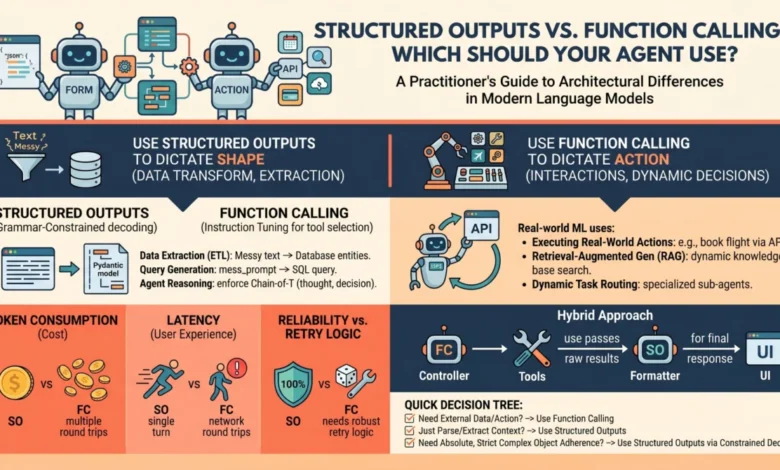
Structured outputs are a mechanism designed to ensure that a model’s response adheres strictly to a predefined schema, typically a JSON object or a Pydantic model. This is achieved through a technique known as grammar-constrained decoding. In standard generation, a model predicts the next token based on a probability distribution across its entire vocabulary. In a constrained environment, the system intercepts this process.
If the schema dictates that the next character in a sequence must be a colon or a numerical value, the probabilities of all non-compliant tokens are mathematically masked—set to zero—before the model makes its selection. This ensures that the model cannot "hallucinate" a format that deviates from the schema. Because this is a single-turn process, the model views the task as a direct completion of the prompt, but within a restricted vocabulary. This method is highly efficient for tasks where the model already possesses the necessary information and simply needs to format it for a machine-readable database.
Function Calling and Instruction Tuning
Function calling, or tool use, operates on a more complex, multi-turn logic. Unlike structured outputs, which focus on the shape of the data, function calling focuses on the capability of the model to interact with the external world. During the training phase, these models undergo specific instruction tuning to recognize when a query requires data or actions beyond their internal parameters—such as checking a real-time stock price or sending an email.
When a developer provides a list of "tools" to the model, they are providing a set of function signatures. The model does not execute the code itself; rather, it generates a "call" consisting of the function name and the necessary arguments in a structured format. The application then executes the code, feeds the results back to the model, and the model generates a final response. This is an inherently agentic process, characterized by a loop of reasoning and acting (often referred to as the ReAct framework).
An Architectural Chronology of LLM Constraints
The transition from unstructured text to precision-engineered outputs has followed a distinct timeline of innovation within the AI sector:
- 2022 – The Era of Prompt Engineering: Developers used "few-shot" prompting to show models examples of JSON. Reliability was low, with failure rates often exceeding 10% in complex tasks.
- Early 2023 – Introduction of Function Calling: OpenAI pioneered the
functionsparameter, allowing models to signal their intent to use a tool. This moved the logic from "formatting" to "action." - Late 2023 – JSON Mode: Providers introduced a "JSON Mode" which improved reliability but did not guarantee 100% adherence to specific schemas.
- August 2024 – Guaranteed Structured Outputs: OpenAI and other providers began offering "Structured Outputs" with 100% schema reliability, utilizing context-free grammar constraints during the inference phase.
- Present – The Agentic Workflow: Current industry standards involve hybridizing these methods to create autonomous agents that can both fetch data (function calling) and report it in standardized formats (structured outputs).
Comparative Analysis: Performance, Latency, and Cost
Choosing between these two methods has direct implications for the unit economics and user experience of an AI application.
Latency and Round-Trips
Structured outputs are generally faster because they occur in a single inference pass. The model receives the input and generates the formatted output immediately. In contrast, function calling often requires at least two round-trips to the API: one for the model to request the tool call, and another for the model to process the tool’s output into a final answer. For real-time applications like voice assistants or high-frequency data processing, the multi-turn nature of function calling can introduce significant lag.
Reliability and Validation
Structured outputs offer the highest level of reliability for data integrity. Because the constraint is applied at the token-level during decoding, the output is mathematically guaranteed to be valid JSON. Function calling, while highly reliable, still carries a slight risk of the model providing incorrect arguments or choosing the wrong tool, particularly when the tool library is large or the function descriptions are ambiguous.
Token Consumption and Cost
Both methods require the developer to pass the schema to the model, which consumes input tokens. However, because function calling involves multiple turns, the cumulative token count is higher. Furthermore, every time a model is asked to "think" before calling a tool, it generates reasoning tokens, which are billed at the standard output rate.
Industry Applications and Use Cases
The decision-making framework for practitioners typically hinges on the source of the information and the required outcome.
When to Utilize Structured Outputs
Structured outputs should be the default choice for data-centric tasks where the "action" is the transformation of information.
- Data Extraction: Converting a medical transcript into a structured patient record.
- Sentiment Analysis: Categorizing customer feedback into predefined buckets (e.g., "Positive," "Negative," "Neutral") for database entry.
- Synthetic Data Generation: Creating standardized datasets for training smaller, specialized models.
- Content Moderation: Flagging content according to a strict set of regulatory categories.
When to Utilize Function Calling
Function calling is essential for applications requiring environmental interaction or dynamic knowledge retrieval.
- Retrieval-Augmented Generation (RAG): Allowing a model to query a vector database or a search engine to find information not present in its training data.
- API Orchestration: An agent that can check a user’s calendar, find an open slot, and send an invite through a third-party service like Google Calendar.
- Dynamic Decision Trees: Systems where the model must choose between different computational paths based on user input, such as a technical support bot that can either "reset a password" or "escalate to a human."
Expert Analysis: The Risks of Conflation
Industry analysts and AI architects warn against treating these two features as interchangeable. A common pitfall in agent design is using function calling for tasks that are essentially formatting problems. This leads to "architectural bloat," where the system is forced into unnecessary multi-turn conversations, increasing the likelihood of "looping" errors and driving up API costs.
Conversely, attempting to use structured outputs for tool interaction—by asking the model to return a JSON object that the system then interprets as a command—is essentially a manual implementation of function calling. While this can sometimes reduce latency by skipping the model’s internal tool-selection logic, it often lacks the robustness of native function calling, which is specifically optimized for this type of reasoning.
The Future of Agentic Workflows
As LLM providers continue to optimize their inference engines, the line between these two mechanisms is expected to blur further. We are seeing the rise of "pre-cached" schemas, where the overhead of sending a large JSON schema is mitigated by the provider storing that schema on their servers.
The consensus among the developer community, including reactions from platforms like LangChain and LlamaIndex, suggests that the future lies in "Type-Safe AI." This involves a move away from the "black box" nature of early LLMs toward systems where the inputs and outputs are as strictly typed as a C++ or TypeScript application. In this future, structured outputs serve as the reliable glue of the data pipeline, while function calling serves as the hands and eyes of the model in the digital world.
Practitioner’s Decision Tree
To determine the appropriate mechanism for a specific feature, engineers are encouraged to follow a three-step evaluation:
- Does the model have all the data? If yes, use structured outputs to format it. If no, use function calling to fetch it.
- Is an external action required? If the model needs to change the state of a system (e.g., writing to a database or moving a robotic arm), function calling is the necessary interface.
- Is latency a primary constraint? For high-speed requirements, prioritize structured outputs and attempt to flatten the logic into a single-turn interaction whenever possible.
By maintaining a clear distinction between the shape of the data and the control flow of the application, developers can build AI agents that are not only intelligent but also predictable and cost-effective. Structured outputs provide the foundation of reliability, while function calling provides the bridge to utility. Together, they represent the essential toolkit for the next generation of software engineering.






{kind=link}